
35 Python×Djangoで作るホットペッパーグルメのデータ収集アプリの作り方 ~データ取得からExcel出力技術解説編~

こんにちは!TechCommitメンバーの友季子です♬
今回は、PythonとDjangoを使って「ホットペッパーグルメ」のデータを収集し、Excelファイルとして出力する方法を技術的な観点でまとめます。
DjangやPythonを学ばれている方、自動でデータを取得するWebアプリケーションを作成したい方の参考になれば幸いです。
※本記事では、view.pyに絞って綴ります。
Python・Django・APIについて基礎知識があることを前提としています。

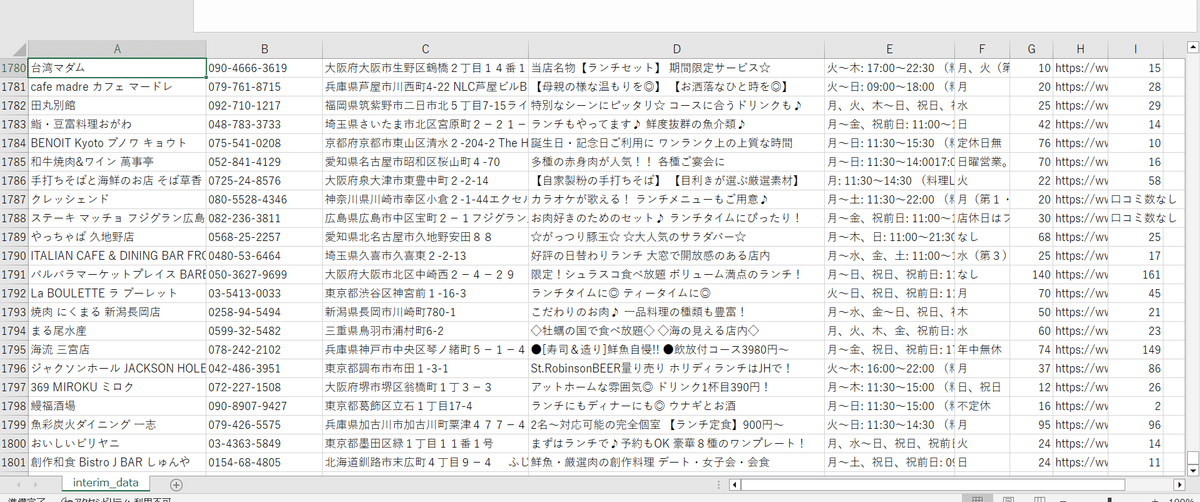
0. 全体の完成コード(サンプル)view.py
以下に、今回のプロジェクトで使用する全体の完成コードを示します。
# views.py
# Djangoのrender関数とHttpResponseクラスをインポート
from django.shortcuts import render
from django.http import HttpResponse
# APIリクエストに使用するrequestsライブラリをインポート
import requests
# データ処理に使用するpandasライブラリをインポート
import pandas as pd
# Webページの解析に使用するBeautifulSoupライブラリをインポート
from bs4 import BeautifulSoup
# 処理の待機に使用するtimeライブラリをインポート
import time
# Windowsのスリープを制御するためのctypesライブラリをインポート
import ctypes
# 日時の計算に使用するdatetimeとtimedeltaをインポート
from datetime import datetime, timedelta
# ファイル操作に使用するosライブラリをインポート
import os
# メモリ上でファイル操作を行うBytesIOクラスをインポート
from io import BytesIO
# リトライ時の待機時間にランダム性を持たせるためのrandomライブラリをインポート
import random
# ホットペッパーのAPIキーを定義
API_KEY = '634chogehogehoge'
# ホットペッパーAPIのURLを定義
URL = 'http://webservice.recruit.co.jp/hotpepper/gourmet/v1/'
# システムのスリープを防ぐ関数
def prevent_sleep():
ctypes.windll.kernel32.SetThreadExecutionState(
0x80000000 | 0x00000001 | 0x00000040) # システムスリープとディスプレイオフを防止
# スリープを許可する関数
def allow_sleep():
ctypes.windll.kernel32.SetThreadExecutionState(0x80000000) # スリープを再び許可
# 中間データをCSVファイルに保存する関数
def save_interim_data(results, file_path, batch_num):
"""中間データをCSVファイルに保存します。"""
try:
# 保存するデータのキーを定義
keys = ['name', '電話番号', 'service_area.name', 'address', 'catch', 'open', 'close',
'budget.average', 'capacity', 'genre.name', 'sub_genre.name', 'PC向けURL', '口コミ数']
# 結果に存在するキーだけを抽出
available_keys = [key for key in keys if key in results[0]]
# 結果をデータフレームに変換
df = pd.DataFrame(results, columns=available_keys)
# データをCSVファイルに保存(ヘッダーは最初のバッチのみ追加)
df.to_csv(file_path, index=False, mode='a', header=batch_num==0, encoding='utf-8-sig')
# 保存完了メッセージを表示
print(f"中間データを保存しました: 行数: {len(results)}")
except Exception as e:
# 保存中にエラーが発生した場合のエラーメッセージを表示
print(f"データの保存中にエラーが発生しました: {e}")
# APIリクエストをリトライ付きで実行する関数
def fetch_data_with_retry(params, retries=3, backoff_factor=1):
"""APIリクエストをリトライ付きで実行する"""
for attempt in range(retries):
try:
# APIリクエストを送信
response = requests.get(URL, params=params, timeout=10)
# ステータスコードが200以外なら例外を発生させる
response.raise_for_status()
# 正常にデータを取得できた場合はレスポンスを返す
return response
except requests.exceptions.RequestException as e:
# リクエスト中にエラーが発生した場合のメッセージを表示
print(f"APIリクエストでエラーが発生しました: {e}, リトライ回数: {attempt + 1}")
# 最大リトライ回数に達していない場合
if attempt < retries - 1:
# リトライまでの待機時間を計算
sleep_time = backoff_factor * (2 ** attempt) + random.uniform(0, 1)
# 待機時間を表示
print(f"{sleep_time:.2f}秒後に再試行します...")
# 指定した時間待機
time.sleep(sleep_time)
else:
# リトライの上限に達した場合、エラーメッセージを表示
print("リトライの上限に達しました。")
# Noneを返して終了
return None
# データ取得のメイン関数
def get_data(keywords, total_count=10000):
"""データ取得メイン関数"""
# スリープを防止
prevent_sleep()
# キーワードをスペースで連結
keyword_str = ' '.join(keywords)
# 取得した全結果を保存するリストを初期化
all_results = []
# APIリクエストのパラメータを設定
params = {
'key': API_KEY, # APIキー
'keyword': keyword_str, # 検索キーワード
'format': 'json', # レスポンス形式
}
# バッチごとの取得件数を計算
quot = total_count // 100
remain = total_count % 100
req_cnt = quot + (1 if remain > 0 else 0)
# 処理開始時間を記録
start_time = datetime.now()
total_scraping_time = timedelta(0)
total_api_time = timedelta(0)
# 中間データ保存用のファイルパスを設定
downloads_dir = os.path.expanduser('~/Downloads')
file_path = os.path.join(downloads_dir, 'interim_data.csv')
# 既存の中間データファイルを削除
if os.path.exists(file_path):
os.remove(file_path)
# バッチ処理のループ
for i in range(req_cnt):
# 最後のバッチの場合、残りの件数を処理
if i == req_cnt - 1 and remain > 0:
count = remain
else:
count = 100
# バッチ内のリクエスト処理用のリストを初期化
batch_results = []
remaining_to_fetch = count # このバッチで取得する必要がある件数
# バッチごとにAPIリクエストを送信
while remaining_to_fetch > 0:
params['count'] = remaining_to_fetch
params['start'] = i * 100 + 1 + len(batch_results) # 取得開始位置を設定
# APIリクエストの進行状況を表示
print(f"APIリクエストを送信しています... (Batch {i + 1}/{req_cnt}, 残り: {remaining_to_fetch})")
# APIリクエストの開始時間を記録
api_start_time = datetime.now()
# リクエストを実行
response = fetch_data_with_retry(params)
# リクエストに失敗した場合、次のバッチに進む
if response is None:
print("APIリクエストに失敗しました。次のバッチに進みます。")
break
# APIリクエストの終了時間を記録
api_end_time = datetime.now()
total_api_time += api_end_time - api_start_time
# レスポンスのステータスコードが200(正常)である場合
if response.status_code == 200:
try:
# レスポンスデータをJSON形式で取得
data = response.json()
# 現在のバッチで取得した結果をリストに追加
current_batch_results = data.get('results', {}).get('shop', [])
batch_results.extend(current_batch_results)
# 取得済みの件数を減算
remaining_to_fetch -= len(current_batch_results)
# データ取得開始時間を記録
scraping_start_time = datetime.now()
# 取得した各店舗データの処理を行う
for result in current_batch_results:
try:
# PC用のURLを取得し、電話番号と口コミ数を取得するためのURLを生成
pc_url = result['urls']['pc'].split('?')[0]
tel_url = pc_url + 'tel'
# 電話番号を取得して結果に追加
result['電話番号'] = get_phone_number(tel_url)
result['電話番号URL'] = tel_url
# 口コミ数を取得して結果に追加
result['口コミ数'] = get_review_count(pc_url)
result['PC向けURL'] = pc_url
except Exception as e:
# データ取得中にエラーが発生した場合のメッセージを表示
print(f"データ取得中にエラーが発生しました(個別店舗処理): {e}")
# データ取得終了時間を記録
scraping_end_time = datetime.now()
total_scraping_time += scraping_end_time - scraping_start_time
except Exception as e:
# レスポンスデータの処理中にエラーが発生した場合のメッセージを表示
print(f"APIレスポンスの処理中にエラーが発生しました: {e}")
continue
else:
# ステータスコードが200以外の場合のエラーメッセージを表示
print("APIリクエストでエラーが発生しました。ステータスコード:", response.status_code)
break
# 現在のバッチで取得したデータを全体の結果リストに追加
all_results.extend(batch_results)
# 中間データを保存
save_interim_data(batch_results, file_path, i)
# 進行状況を表示
print(f"現在の取得件数: {len(all_results)} 件")
# 経過時間を計算
elapsed_time = datetime.now() - start_time
# バッチあたりの平均処理時間を計算
avg_time_per_batch = (elapsed_time + total_scraping_time + total_api_time) / (i + 1)
# 残りのバッチ数を計算
remaining_batches = req_cnt - (i + 1)
# 残り時間を予測
estimated_remaining_time = avg_time_per_batch * remaining_batches
# 完了予測時間を計算
estimated_completion_time = datetime.now() + estimated_remaining_time
# 残り時間と完了予測時間を表示
print(f"予測完了時間: {estimated_completion_time.strftime('%Y-%m-%d %H:%M:%S')}")
print(f"残り時間: {estimated_remaining_time}\n")
# データ取得が完了していない場合、少し待機
if len(all_results) < total_count:
print("1.5秒の休憩中...")
time.sleep(1.5)
# データ収集が完了したことを表示
print(f"データ収集が完了しました。ファイルパス: {file_path}")
# スリープを許可
allow_sleep()
# 取得したデータを返す
return all_results
# 口コミ数を取得する関数
def get_review_count(url):
"""口コミ数を取得します。"""
review_count_text = "口コミ数なし" # デフォルトの口コミ数
try:
# 指定されたURLにリクエストを送信
response = requests.get(url, timeout=10)
# ステータスコードが200以外なら例外を発生させる
response.raise_for_status()
# レスポンスのHTMLを解析
soup = BeautifulSoup(response.text, 'html.parser')
# 口コミ数が記載されている要素を検索
li_element = soup.select_one('li.recommendReport > a')
if li_element:
p_element = li_element.find_next('p', class_='recommendReportNum')
if p_element:
# 口コミ数を取得
review_count_text = p_element.find('span').get_text()
except Exception as e:
# 口コミ数取得中にエラーが発生した場合のメッセージを表示
print(f"口コミ数取得中にエラーが発生しました: {e}")
# 取得した口コミ数を返す
return review_count_text
# 電話番号を取得する関数
def get_phone_number(url):
"""電話番号を取得します。"""
phone_number_text = "電話番号なし" # デフォルトの電話番号
try:
# 電話番号を取得するためのURLを表示
print(f"電話番号取得中のURL: {url}")
# 指定されたURLにリクエストを送信
response = requests.get(url, timeout=10)
# ステータスコードが200以外なら例外を発生させる
response.raise_for_status()
# レスポンスのHTMLを解析
soup = BeautifulSoup(response.content, 'html.parser')
# 電話番号が記載されている要素を検索
phone_number_tag = soup.select_one('div.storeTelephoneWrap > p.telephoneNumber')
if phone_number_tag:
# 電話番号を取得
phone_number_text = phone_number_tag.get_text().strip()
print(f"取得した電話番号: {phone_number_text}")
else:
# 電話番号のタグが見つからなかった場合のメッセージを表示
print("電話番号のタグが見つかりませんでした")
except Exception as e:
# 電話番号取得中にエラーが発生した場合のメッセージを表示
print(f"電話番号取得中にエラーが発生しました: {e}")
# 取得した電話番号を返す
return phone_number_text
# 検索画面の表示とデータ取得の開始
def index(request):
"""検索画面の表示とデータ取得の開始"""
results = []
if request.method == 'POST':
# フォームからキーワードと取得件数を取得
keywords = request.POST.get('keywords', '').split()
count = request.POST.get('count')
total_count = int(count) if count else 10000
# データ取得関数を呼び出して結果を取得
results = get_data(keywords, total_count)
# セッションに結果とファイル名を保存
request.session['results'] = results
request.session['filename'] = 'HotPepper_Gourmet_Django_Version'
# 検索画面を表示
return render(request, 'index.html', {'results': results})
# 取得データをExcelとしてダウンロード
def download_excel(request):
"""取得データをExcelとしてダウンロード"""
# ファイル名と結果をセッションから取得
filename = request.session.get('filename', 'HotPepper_Gourmet_Django_Version')
results = request.session.get('results', [])
if results:
# 保存するデータのキーを定義
keys = ['name', '電話番号', 'service_area.name', 'address', 'catch', 'open', 'close',
'budget.average', 'capacity', 'genre.name', 'sub_genre.name', 'PC向けURL', '口コミ数']
# 結果に存在するキーだけを抽出
available_keys = [key for key in keys if key in results[0]]
# 結果をデータフレームに変換
df = pd.DataFrame(results, columns=available_keys)
# メモリ上でExcelファイルを作成
buffer = BytesIO()
with pd.ExcelWriter(buffer, engine='xlsxwriter') as writer:
df.to_excel(writer, index=False, sheet_name='Results')
# HttpResponseでExcelファイルを返す
response = HttpResponse(
buffer.getvalue(),
content_type='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'
)
response['Content-Disposition'] = f'attachment; filename={filename}.xlsx'
return response
else:
# データがない場合はエラーメッセージを表示
return HttpResponse("データがありません。")
1. 各部分の解説
以下に、コードの各部分にコメントを付けて解説します。
各パーツに分けたコード解説
ここでは、Djangoアプリケーションのviews.pyファイルのコードを主要なパーツに分けて解説します。それぞれのパーツがどのように機能しているかを詳しく見ていきましょう。
1.1. 必要なライブラリと定数の定義
# Djangoのrender関数とHttpResponseクラスをインポート
from django.shortcuts import render
from django.http import HttpResponse
# APIリクエストに使用するrequestsライブラリをインポート
import requests
# データ処理に使用するpandasライブラリをインポート
import pandas as pd
# Webページの解析に使用するBeautifulSoupライブラリをインポート
from bs4 import BeautifulSoup
# 処理の待機に使用するtimeライブラリをインポート
import time
# Windowsのスリープを制御するためのctypesライブラリをインポート
import ctypes
# 日時の計算に使用するdatetimeとtimedeltaをインポート
from datetime import datetime, timedelta
# ファイル操作に使用するosライブラリをインポート
import os
# メモリ上でファイル操作を行うBytesIOクラスをインポート
from io import BytesIO
# リトライ時の待機時間にランダム性を持たせるためのrandomライブラリをインポート
import random
# ホットペッパーのAPIキーを定義
API_KEY = '634c407235d16f2b'
# ホットペッパーAPIのURLを定義
URL = 'http://webservice.recruit.co.jp/hotpepper/gourmet/v1/'
解説
from django.shortcuts import render: Djangoのビューをレンダリングするための関数です。
from django.http import HttpResponse: HTTPレスポンスを返すためのクラスです。
requests: HTTPリクエストを行うためのPythonライブラリです。
pandas: データの操作や分析を行うためのライブラリで、データをDataFrameとして扱います。
BeautifulSoup: HTMLやXML文書を解析し、必要なデータを抽出するためのライブラリです。
time: 処理の待機やタイミング計測に使用します。
ctypes: Windows APIを呼び出して、システムのスリープを制御します。
datetime: 日付や時間を扱うためのライブラリです。
os: OS依存の機能にアクセスするためのライブラリで、ここではファイルパスの操作に使用しています。
BytesIO: メモリ上でファイルのような操作を行うためのクラスです。
random: ランダムな数値を生成するために使用します。
API_KEY: HotPepper APIにアクセスするためのキーです。
URL: HotPepper APIのエンドポイントURLです。
1.2. スリープ防止・許可関数
# システムのスリープを防ぐ関数
def prevent_sleep():
ctypes.windll.kernel32.SetThreadExecutionState(
0x80000000 | 0x00000001 | 0x00000040) # システムスリープとディスプレイオフを防止
# スリープを許可する関数
def allow_sleep():
ctypes.windll.kernel32.SetThreadExecutionState(0x80000000) # スリープを再び許可
解説
prevent_sleep: この関数は、Windowsシステムがスリープ状態に入るのを防ぎます。APIデータの取得中にシステムがスリープしてしまうと、データ取得が中断されてしまうためです。
allow_sleep: データ取得が完了した後、この関数を呼び出してスリープを再び許可します。
1.3. 中間データの保存
# 中間データをCSVファイルに保存する関数
def save_interim_data(results, file_path, batch_num):
"""中間データをCSVファイルに保存します。"""
try:
# 保存するデータのキーを定義
keys = ['name', '電話番号', 'service_area.name', 'address', 'catch', 'open', 'close',
'budget.average', 'capacity', 'genre.name', 'sub_genre.name', 'PC向けURL', '口コミ数']
# 結果に存在するキーだけを抽出
available_keys = [key for key in keys if key in results[0]]
# 結果をデータフレームに変換
df = pd.DataFrame(results, columns=available_keys)
# データをCSVファイルに保存(ヘッダーは最初のバッチのみ追加)
df.to_csv(file_path, index=False, mode='a', header=batch_num==0, encoding='utf-8-sig')
# 保存完了メッセージを表示
print(f"中間データを保存しました: 行数: {len(results)}")
except Exception as e:
# 保存中にエラーが発生した場合のエラーメッセージを表示
print(f"データの保存中にエラーが発生しました: {e}")
解説
save_interim_data: データ取得処理の途中でデータを部分的に保存するための関数です。
keys: 保存したいデータの項目(列名)をリストとして定義します。
available_keys: 実際に取得したデータに存在するキーだけをフィルタリングします。
pd.DataFrame: データをDataFrameとして扱い、CSVファイルに保存します。
mode='a': 追記モードでファイルに書き込み、header=batch_num==0で最初のバッチのみヘッダー行を追加します。
1.4. APIリクエストのリトライ機能
# APIリクエストをリトライ付きで実行する関数
def fetch_data_with_retry(params, retries=3, backoff_factor=1):
"""APIリクエストをリトライ付きで実行する"""
for attempt in range(retries):
try:
# APIリクエストを送信
response = requests.get(URL, params=params, timeout=10)
# ステータスコードが200以外なら例外を発生させる
response.raise_for_status()
# 正常にデータを取得できた場合はレスポンスを返す
return response
except requests.exceptions.RequestException as e:
# リクエスト中にエラーが発生した場合のメッセージを表示
print(f"APIリクエストでエラーが発生しました: {e}, リトライ回数: {attempt + 1}")
# 最大リトライ回数に達していない場合
if attempt < retries - 1:
# リトライまでの待機時間を計算
sleep_time = backoff_factor * (2 ** attempt) + random.uniform(0, 1)
# 待機時間を表示
print(f"{sleep_time:.2f}秒後に再試行します...")
# 指定した時間待機
time.sleep(sleep_time)
else:
# リトライの上限に達した場合、エラーメッセージを表示
print("リトライの上限に達しました。")
# Noneを返して終了
return None
解説
fetch_data_with_retry: APIリクエストを行い、失敗した場合に指定した回数まで再試行する関数です。
retries: リトライの最大回数を指定します。
backoff_factor: リトライ間隔を指数的に増加させるための係数です。
time.sleep(sleep_time): 次のリトライまでの待機時間を設定し、指数的に待機時間が増えます。
1.5. データ取得のメイン関数
# データ取得のメイン関数
def get_data(keywords, total_count=10000):
"""データ取得メイン関数"""
# スリープを防止
prevent_sleep()
# キーワードをスペースで連結
keyword_str = ' '.join(keywords)
# 取得した全結果を保存するリストを初期化
all_results = []
# APIリクエストのパラメータを設定
params = {
'key': API_KEY, # APIキー
'keyword': keyword_str, # 検索キーワード
'format': 'json', # レスポンス形式
}
# バッチごとの取得件数を計算
quot = total_count // 100
remain = total_count % 100
req_cnt = quot + (1 if remain > 0 else 0)
# 処理開始時間を記録
start_time = datetime.now()
total_scraping_time = timedelta(0)
total_api_time = timedelta(0)
# 中間データ保存用のファイルパスを設定
downloads_dir = os.path.expanduser('~/Downloads')
file_path = os.path.join(downloads_dir, 'interim_data.csv')
# 既存の中間データファイルを削除
if os.path.exists(file_path):
os.remove(file_path)
# バッチ処理のループ
for i in range(req_cnt):
# 最後のバッチの場合、残りの件数を処理
if i == req_cnt - 1 and remain > 0:
count = remain
else:
count = 100
# バッチ内のリクエスト処理用のリストを初期化
batch_results = []
remaining_to_fetch = count # このバッチで取得する必要がある件数
# バッチごとにAPIリクエストを送信
while remaining_to_fetch > 0:
params['count'] = remaining_to_fetch
params['start'] = i * 100 + 1 + len(batch_results) # 取得開始位置を設定
# APIリクエストの進行状況を表示
print(f"APIリクエストを送信しています... (Batch {i + 1}/{req_cnt}, 残り: {remaining_to_fetch})")
# APIリクエストの開始時間を記録
api_start_time = datetime.now()
# リクエストを実行
response = fetch_data_with_retry(params)
# リクエストに失敗した場合、次のバッチに進む
if response is None:
print("APIリクエストに失敗しました。次のバッチに進みます。")
break
# APIリクエストの終了時間を記録
api_end_time = datetime.now()
total_api_time += api_end_time - api_start_time
# レスポンスのステータスコードが200(正常)である場合
if response.status_code == 200:
try:
# レスポンスデータをJSON形式で取得
data = response.json()
# 現在のバッチで取得した結果をリストに追加
current_batch_results = data.get('results', {}).get('shop', [])
batch_results.extend(current_batch_results)
# 取得済みの件数を減算
remaining_to_fetch -= len(current_batch_results)
# データ取得開始時間を記録
scraping_start_time = datetime.now()
# 取得した各店舗データの処理を行う
for result in current_batch_results:
try:
# PC用のURLを取得し、電話番号と口コミ数を取得するためのURLを生成
pc_url = result['urls']['pc'].split('?')[0]
tel_url = pc_url + 'tel'
# 電話番号を取得して結果に追加
result['電話番号'] = get_phone_number(tel_url)
result['電話番号URL'] = tel_url
# 口コミ数を取得して結果に追加
result['口コミ数'] = get_review_count(pc_url)
result['PC向けURL'] = pc_url
except Exception as e:
# データ取得中にエラーが発生した場合のメッセージを表示
print(f"データ取得中にエラーが発生しました(個別店舗処理): {e}")
# データ取得終了時間を記録
scraping_end_time = datetime.now()
total_scraping_time += scraping_end_time - scraping_start_time
except Exception as e:
# レスポンスデータの処理中にエラーが発生した場合のメッセージを表示
print(f"APIレスポンスの処理中にエラーが発生しました: {e}")
continue
else:
# ステータスコードが200以外の場合のエラーメッセージを表示
print("APIリクエストでエラーが発生しました。ステータスコード:", response.status_code)
break
# 現在のバッチで取得したデータを全体の結果リストに追加
all_results.extend(batch_results)
# 中間データを保存
save_interim_data(batch_results, file_path, i)
# 進行状況を表示
print(f"現在の取得件数: {len(all_results)} 件")
# 経過時間を計算
elapsed_time = datetime.now() - start_time
# バッチあたりの平均処理時間を計算
avg_time_per_batch = (elapsed_time + total_scraping_time + total_api_time) / (i + 1)
# 残りのバッチ数を計算
remaining_batches = req_cnt - (i + 1)
# 残り時間を予測
estimated_remaining_time = avg_time_per_batch * remaining_batches
# 完了予測時間を計算
estimated_completion_time = datetime.now() + estimated_remaining_time
# 残り時間と完了予測時間を表示
print(f"予測完了時間: {estimated_completion_time.strftime('%Y-%m-%d %H:%M:%S')}")
print(f"残り時間: {estimated_remaining_time}\n")
# データ取得が完了していない場合、少し待機
if len(all_results) < total_count:
print("1.5秒の休憩中...")
time.sleep(1.5)
# データ収集が完了したことを表示
print(f"データ収集が完了しました。ファイルパス: {file_path}")
# スリープを許可
allow_sleep()
# 取得したデータを返す
return all_results
解説
get_data: メインのデータ取得関数です。APIリクエストをバッチごとに処理し、結果を収集します。各バッチの進行状況がターミナルに表示され、データが中間保存されます。
params: APIに送信するパラメータを設定します。
save_interim_data: データが部分的に取得されるたびに中間データをCSVファイルに保存します。
time.sleep(1.5): 各バッチの取得間に短い休憩を入れ、APIサーバーへの負荷を軽減します。
1.6. Webスクレイピング関数
# 口コミ数を取得する関数
def get_review_count(url):
"""口コミ数を取得します。"""
review_count_text = "口コミ数なし" # デフォルトの口コミ数
try:
# 指定されたURLにリクエストを送信
response = requests.get(url, timeout=10)
# ステータスコードが200以外なら例外を発生させる
response.raise_for_status()
# レスポンスのHTMLを解析
soup = BeautifulSoup(response.text, 'html.parser')
# 口コミ数が記載されている要素を検索
li_element = soup.select_one('li.recommendReport > a')
if li_element:
p_element = li_element.find_next('p', class_='recommendReportNum')
if p_element:
# 口コミ数を取得
review_count_text = p_element.find('span').get_text()
except Exception as e:
# 口コミ数取得中にエラーが発生した場合のメッセージを表示
print(f"口コミ数取得中にエラーが発生しました: {e}")
# 取得した口コミ数を返す
return review_count_text
# 電話番号を取得する関数
def get_phone_number(url):
"""電話番号を取得します。"""
phone_number_text = "電話番号なし" # デフォルトの電話番号
try:
# 電話番号を取得するためのURLを表示
print(f"電話番号取得中のURL: {url}")
# 指定されたURLにリクエストを送信
response = requests.get(url, timeout=10)
# ステータスコードが200以外なら例外を発生させる
response.raise_for_status()
# レスポンスのHTMLを解析
soup = BeautifulSoup(response.content, 'html.parser')
# 電話番号が記載されている要素を検索
phone_number_tag = soup.select_one('div.storeTelephoneWrap > p.telephoneNumber')
if phone_number_tag:
# 電話番号を取得
phone_number_text = phone_number_tag.get_text().strip()
print(f"取得した電話番号: {phone_number_text}")
else:
# 電話番号のタグが見つからなかった場合のメッセージを表示
print("電話番号のタグが見つかりませんでした")
except Exception as e:
# 電話番号取得中にエラーが発生した場合のメッセージを表示
print(f"電話番号取得中にエラーが発生しました: {e}")
# 取得した電話番号を返す
return phone_number_text
解説
電話番号と口コミ取得はスクレイピングで実行しました。
get_review_count: 指定された店舗の口コミ数をWebページから取得するための関数です。HTMLを解析して口コミ数を抽出します。
get_phone_number: 店舗の電話番号を取得するための関数です。電話番号が記載されている要素を検索して、テキストとして抽出します。
1.7. 検索画面の表示とデータ取得の開始
# 検索画面の表示とデータ取得の開始
def index(request):
"""検索画面の表示とデータ取得の開始"""
results = []
if request.method == 'POST':
# フォームからキーワードと取得件数を取得
keywords = request.POST.get('keywords', '').split()
count = request.POST.get('count')
total_count = int(count) if count else 10000
# データ取得関数を呼び出して結果を取得
results = get_data(keywords, total_count)
# セッションに結果とファイル名を保存
request.session['results'] = results
request.session['filename'] = 'HotPepper_Gourmet_Django_Version'
# 検索画面を表示
return render(request, 'index.html', {'results': results})
解説
index: ユーザーが検索画面でキーワードを入力し、データ取得を開始するためのビューです。
request.method == 'POST': フォームが送信された場合、データ取得処理が開始されます。
get_data: データ取得のメイン関数を呼び出し、結果を取得します。
request.session: 結果をセッションに保存し、後でExcelとしてダウンロードできるようにします。
1.8. 取得データをExcelとしてダウンロード
# 取得データをExcelとしてダウンロード
def download_excel(request):
"""取得データをExcelとしてダウンロード"""
# ファイル名と結果をセッションから取得
filename = request.session.get('filename', 'HotPepper_Gourmet_Django_Version')
results = request.session.get('results', [])
if results:
# 保存するデータのキーを定義
keys = ['name', '電話番号', 'service_area.name', 'address', 'catch', 'open', 'close',
'budget.average', 'capacity', 'genre.name', 'sub_genre.name', 'PC向けURL', '口コミ数']
# 結果に存在するキーだけを抽出
available_keys = [key for key in keys if key in results[0]]
# 結果をデータフレームに変換
df = pd.DataFrame(results, columns=available_keys)
# メモリ上でExcelファイルを作成
buffer = BytesIO()
with pd.ExcelWriter(buffer, engine='xlsxwriter') as writer:
df.to_excel(writer, index=False, sheet_name='Results')
# HttpResponseでExcelファイルを返す
response = HttpResponse(
buffer.getvalue(),
content_type='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'
)
response['Content-Disposition'] = f'attachment; filename={filename}.xlsx'
return response
else:
# データがない場合はエラーメッセージを表示
return HttpResponse("データがありません。")
解説
download_excel: 取得したデータをExcelファイルとしてダウンロードするためのビューです。
BytesIO: メモリ上でExcelファイルを作成し、ダウンロード用に準備します。
pd.DataFrame: データをDataFrameに変換し、Excel形式で保存します。
HttpResponse: 作成したExcelファイルをHTTPレスポンスとして返します。
2.技術的なポイントについて
APIリクエストのリトライ: fetch_data_with_retry関数では、リクエストが失敗した場合に指定された回数までリトライを行います。リトライ間隔は指数的に増加するバックオフ方式を採用しており、APIサーバーへの負荷を軽減します。
中間データの保存: save_interim_data関数では、データを部分的に取得しながら逐次CSVファイルに保存します。これにより、途中で処理が中断されてもデータが失われることがありません。
Webスクレイピング: get_review_countやget_phone_number関数で、BeautifulSoupを使ってWebページから特定のデータを抽出します。これらの関数はAPIから取得できない追加情報を補完するために使用されます。
進行状況の表示: get_data関数内で、データ取得の進行状況や予想完了時間をターミナルに表示する機能を実装しています。これにより、長時間かかる処理の進捗を確認することができます。
3. コードの流れ
検索画面表示: ユーザーがキーワードを入力して検索を開始します。
データ取得処理: 入力されたキーワードに基づいて、APIを使って飲食店のデータを取得します。取得されたデータは中間ファイルとして保存され、進捗がターミナルに表示されます。
スクレイピング: 各店舗のWebページをスクレイピングして、電話番号や口コミ数を取得します。
結果表示とダウンロード: 取得したデータを画面に表示し、Excelファイルとしてダウンロードできるようにします。
4. API定義書
Powered by ホットペッパーグルメ Webサービス
5. 終わりに
今回は、Djangoを使ったホットペッパーグルメのデータ収集アプリの作成方法を技術的な観点で紹介しました。
PythonやDjangoの学習をしたい方、一緒に頑張りましょう♪
Happy Coding!