
132【PyMuPDF】ExcelをPDF化したファイルの帳票からテキストを読み取ってメモに書き出す方法

はじめに
こんにちは!TechCommitメンバーの友季子です♬
今回は、PDFファイルからテキストを読み取ってメモに書き出す方法についてまとめてみます。
Pythonを使ったPDF処理に興味がある方、特にデータを自動で抽出したい方にお役に立てればと思い執筆しました。
では早速、Excelで作成した帳票をPDFに変換した後、その内容をPythonを使って抽出する方法をご紹介します!
PDFファイルからテキストを抽出する方法
ここでは、PyMuPDF(fitz)を使用して、PDFファイルからテキストを抽出する方法を紹介します。
PyMuPDFは、PythonからPDFを簡単に操作できるライブラリで、PDF内のテキストを効率よく抽出できます。
PyMuPDFを選んだ理由
①PyMuPDFを使うことでPDFから効率的にテキストを抽出できる。
②必要に応じてテキストの形式が比較的簡単にできる。
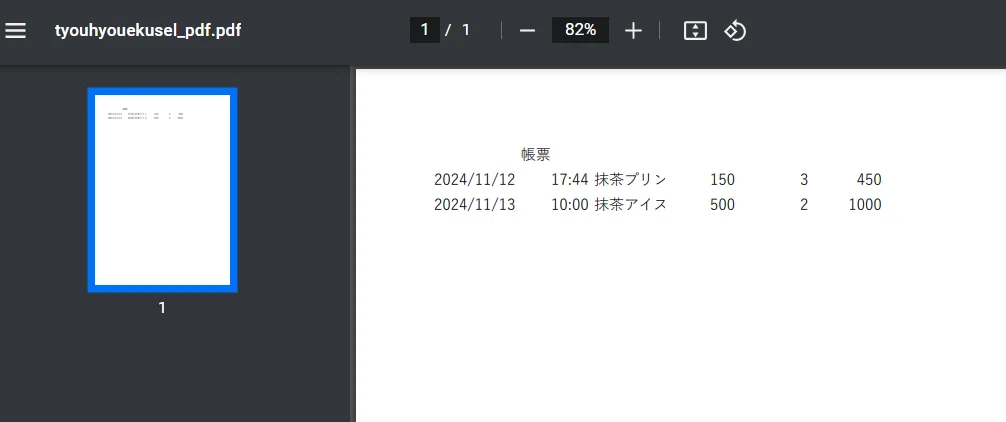
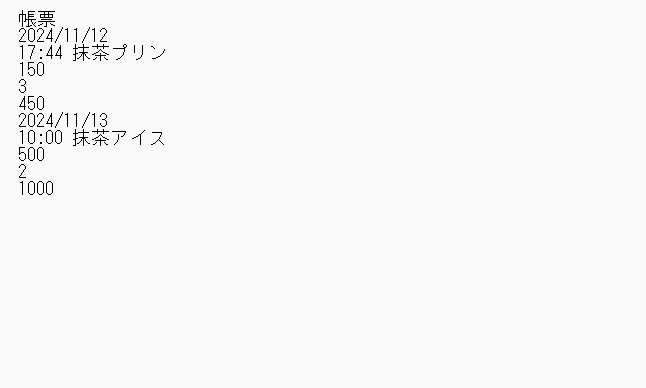
必要なライブラリのインストール
まずは、必要なライブラリをインストールします。以下のコマンドでPyMuPDFをインストールしてください。
pip install pymupdfコード例
それでは、実際にPDFファイルからテキストを抽出するコードを見てみましょう。
import fitz # PyMuPDFをインポート
# PDFファイルのパス
pdf_path = r'C:\hogehoge.pdf' # ここを変えてね(インプットファイルをPDF形式で)
output_txt_path = r'C:\hogehoge\kakidasi.txt' # ここを変えてね(アウトプットファイルをメモで)
# PDFを開く
doc = fitz.open(pdf_path)
# 抽出したテキストを保存するための文字列変数
extracted_text = ''
# 各ページをループしてテキストを抽出
for page_num in range(len(doc)): # PDFの全ページをループ
page = doc.load_page(page_num) # ページをロード
extracted_text += page.get_text() # ページからテキストを抽出
# 抽出したテキストをファイルに書き出す
with open(output_txt_path, 'w', encoding='utf-8') as output_file:
output_file.write(extracted_text)
print(extracted_text) # ここでテキストを表示してデバッグ
print(f"PDFから抽出したテキストが '{output_txt_path}' に保存されました!")
解説あり
import fitz # PyMuPDFをインポート
# PDFファイルのパス
pdf_path = r'C:hogehoge/1112kakidasirist.pdf' # 処理するPDFファイルのパス
output_txt_path = r'C:\hogehogekakidasi.txt' # 抽出したテキストを保存する出力先
# PDFを開く
doc = fitz.open(pdf_path) # PDFファイルを開く
# 抽出したテキストを保存するための文字列変数
extracted_text = '' # ここに各ページから抽出したテキストを追加していく
# 各ページをループしてテキストを抽出
for page_num in range(len(doc)): # PDFのページ数分ループ
page = doc.load_page(page_num) # ページをロード(page_numは0から始まる)
extracted_text += page.get_text() # ページからテキストを抽出して変数に追加
# 抽出したテキストをファイルに書き出す
with open(output_txt_path, 'w', encoding='utf-8') as output_file: # 出力ファイルを開く(書き込みモード)
output_file.write(extracted_text) # 抽出したテキストをファイルに書き込む
print(extracted_text) # 抽出したテキストをデバッグ用にコンソールに表示
# 抽出したテキストがファイルに保存されたことを確認
print(f"PDFから抽出したテキストが '{output_txt_path}' に保存されました!")
コメントと説明
PyMuPDFのインポート: import fitz により、PyMuPDFの機能を使用できるようになります。PyMuPDFはPDFの読み込み、テキスト抽出などをサポートします。
PDFファイルのパス設定:
pdf_path は処理したいPDFファイルのパスです。
output_txt_path は抽出したテキストを保存するファイルのパスです。
PDFの読み込み: fitz.open(pdf_path) によって、指定されたPDFを開きます。
ページごとのテキスト抽出:
for page_num in range(len(doc)) で、PDF内のすべてのページを順に処理します。
doc.load_page(page_num) で各ページをロードし、page.get_text() でそのページからテキストを抽出します。
テキストファイルへの書き出し:
抽出したテキストを output_txt_path に指定したファイルに書き込みます。'w' は書き込みモードを指定しており、ファイルが存在しない場合は新規作成されます。
デバッグ用表示:
print(extracted_text) で抽出したテキストをコンソールに表示し、正しくテキストが抽出されているかを確認します。
完了メッセージ: テキストがファイルに保存されたことをコンソールに表示することで、処理が終了したことを確認できます。
改善点
抽出されたテキストの形式: 現在、PDFから抽出されたテキストは1行ずつ連結されますが、元のフォーマット(例えば表形式や段落など)を保持するためには、get_text("dict") や get_text("html") などを使うと、より複雑なレイアウト情報を取得できます。
例えば、get_text("dict") でページのテキストを辞書形式で取得し、より詳細な情報(座標やフォントなど)を扱うことができます。
改行や空白処理: PDFから抽出されるテキストは、PDFのレイアウトに依存して改行が不規則だったり、必要な空白が不足している場合があります。これを改善するために、抽出後にテキストを加工することができます。例えば、text.replace("\n", " ") で改行をスペースに置き換えたり、特定の形式に合わせて整形できます。
例外処理:
PDFファイルが読み込めなかったり、書き込み先のディレクトリが存在しない場合のエラーハンドリングを追加すると、より堅牢なコードになります。
try:
doc = fitz.open(pdf_path)
except Exception as e:
print(f"PDFの読み込みに失敗しました: {e}")
try:
with open(output_txt_path, 'w', encoding='utf-8') as output_file:
output_file.write(extracted_text)
except Exception as e:
print(f"ファイルの書き込みに失敗しました: {e}")
コードのポイント
PDFを開く:
fitz.open(pdf_path) で指定したPDFファイルを開きます。
テキストを抽出する:
page.get_text() メソッドでページからテキストを抽出します。これを各ページに対して実行し、テキストをextracted_textに追加していきます。
ファイルへの保存:
output_txt_pathに指定したパスにテキストを保存します。'w'モードで書き込んでいるので、既存のファイルがあれば上書きされます。
おわりに
いかがでしたか?
このコードを使えば、PDF形式で保存された帳票から簡単にテキストを抽出できるので、データ処理の自動化や解析に役立ちます。
特に、Pythonを学ばれている方には、PDFからのテキスト抽出の基本を理解するのにぴったりの内容だと思います。
ちょっとでも参考にしていただければ幸いです。
▼実際に試したい方はこちらをどうぞ。
https://drive.google.com/drive/folders/1TRe0Qya8wEpeEcJLwOxcV-WMXbIhq3uL?usp=sharing