
ElevenLabs(TTS)のAPI使い方【Pythonサンプルコード有り】

AIVtuberシロハナちゃんの開発プロデュースをしているyukiです。
この記事ではElevenLabsのAPIを試してみたので使い方などを備忘録として残します。
ElevenLabsというツールは簡単にいうと、人間の声を素材として音声クローンを作って合成音声として利用できます。
これはElevenLabsのサイトで利用可能に加えて、APIとして提供もされています。
そこでAPI使う参考に「入力したテキストをElevenLabsのAPIを使って合成音声にして音声ファイルとして書き出す」という簡易的なサンプルPythonコードも記載しています。
環境はWindowsで言語はPython 3.12.0です。
ElevenLabsのAPIドキュメント等の詳細は以下公式からどうぞ。
※この記事は2024/7/27時点のものなので今後変更があるかもしれないですのでご了承ください
ElevenLabsとは?使い方など
以下の動画で解説しています。
API以外の基本的な概要や使い方はこちらをご覧ください。
ElevenLabsのサイトでAPIキーとボイスID発行
①ElevenLabsのサイト左下のメニューからAPI keyという箇所をクリックします。
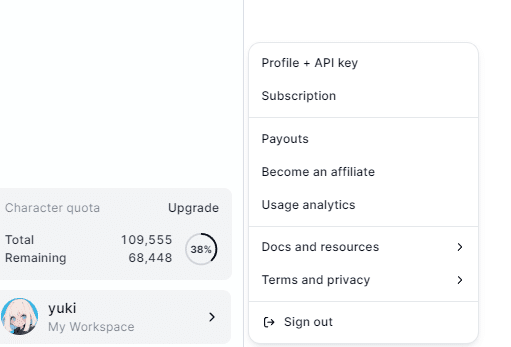
②APIを発行します。更新も可能です。

③Voices画面の呼び出したいボイスを選択してIDというボタンを押下するとボイスIDをコピーできます。(各ボイスごとにこの値は変わります)
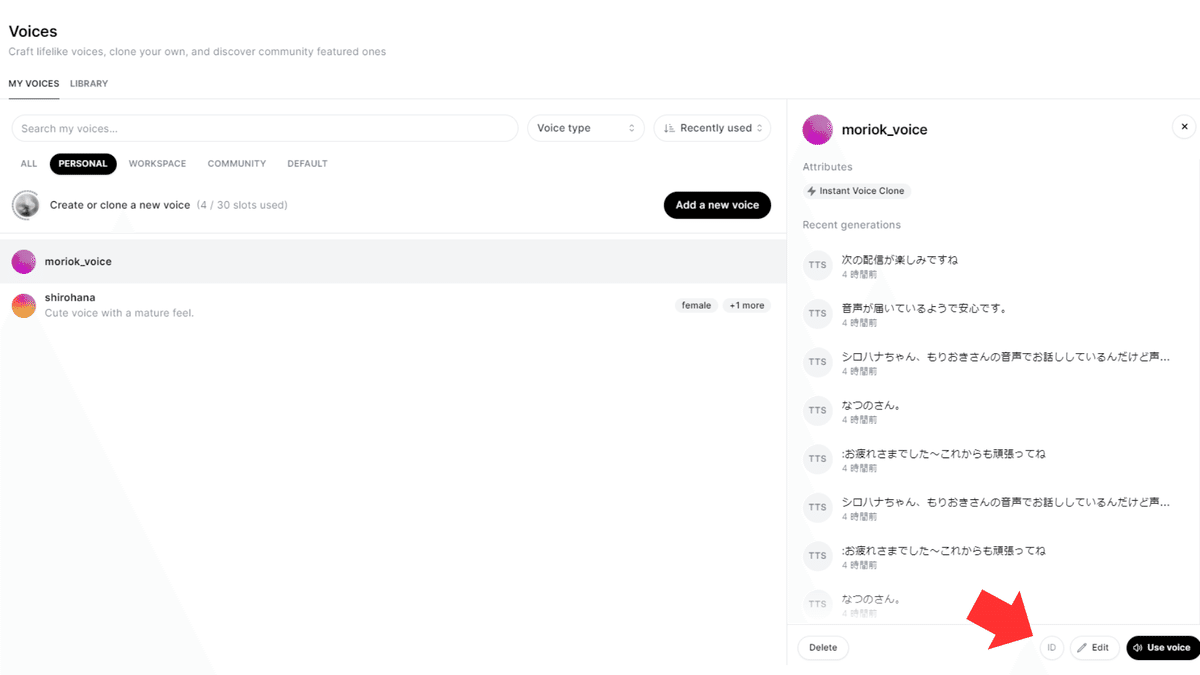
ElevenLabsのAPIをPythonで使う
事前準備
①任意の階層にフォルダ作成してターミナルで以下コマンドで仮想環境にする。
python -m venv .venv
.venv\Scripts\activate.bat②必要なパッケージのインストールをする。
pip install elevenlabs
pip install python-dotenv requestsPythonサンプルコード(elevenlabs.py)
import os
from dotenv import load_dotenv
import requests
import time
load_dotenv() # .envファイルから環境変数を読み込む
class ElevenLabs:
URL = "https://api.elevenlabs.io/v1/text-to-speech"
def __init__(self, api_key, voice_id):
self.api_key = api_key
self.voice_id = voice_id
def text_to_speech(self, text):
# APIリクエストのヘッダーとデータを設定
headers = {
"Accept": "audio/wav", # WAV形式を指定
"Content-Type": "application/json",
"xi-api-key": self.api_key,
}
data = {
"text": text,
"model_id": "eleven_turbo_v2_5", # モデルID
"voice_settings": {"stability": 0.5, "similarity_boost": 0.5}, # 音声設定
"output_format": "wav",
}
# APIにリクエストを送信
response = requests.post(
f"{self.URL}/{self.voice_id}", json=data, headers=headers
)
if response.status_code != 200:
print(f"エラー: {response.status_code} - {response.text}")
return None
return response.content
def save_audio(self, audio_content, output_dir):
# 出力ディレクトリが存在しない場合は作成
os.makedirs(output_dir, exist_ok=True)
# タイムスタンプを使用してユニークなファイル名を生成
filename = f"audio_{int(time.time())}.wav" # 拡張子をwavに変更
file_path = os.path.join(output_dir, filename)
# 音声データをファイルに書き込む
with open(file_path, "wb") as audio_file:
audio_file.write(audio_content)
print(f"音声ファイルを保存しました: {file_path}")
def main():
# 環境変数からAPIキーとボイスIDを取得
api_key = os.getenv("ELEVENLABS_API_KEY")
voice_id = os.getenv("ELEVENLABS_VOICE_ID")
if not api_key or not voice_id:
print(
"エラー: ELEVENLABS_API_KEYまたはELEVENLABS_VOICE_ID環境変数が設定されていません"
)
return
tts = ElevenLabs(api_key, voice_id)
output_dir = "audio_files" # 保存先ディレクトリ
# ユーザーからの入力を受け付けて音声を生成・保存するループ
while True:
text = input("話させたいテキストを入力してください(終了するには'q'を入力): ")
if text.lower() == "q":
break
audio_content = tts.text_to_speech(text)
if audio_content:
tts.save_audio(audio_content, output_dir)
if __name__ == "__main__":
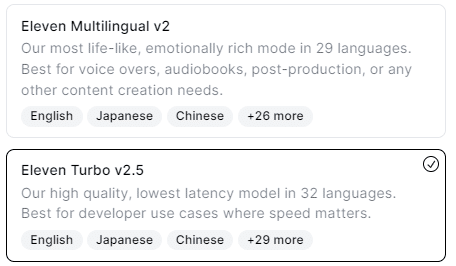
main()モデルはElevenLabs Turbo v2.5を使っています。
環境変数(.env)
ELEVENLABS_API_KEY= "発行したAPIキーを入力"
ELEVENLABS_VOICE_ID= "ElevenLabsのVoicesページにて取得したボイスIDを入力"テキスト入力→ElevenLabsのAPI使ってTTS→音声ファイル保存
①コマンド実行
python elevenlabs.py②「こんばんは」と入力して実行。audio_filesが作成されて、その中にElevenLabsのAPIで生成された音声ファイルが保存されている。
(.venv) C:\ElevenLabs>python elevenlabs.py
話させたいテキストを入力してください(終了するには'q'を入力): こんばんは
音声ファイルを保存しました: audio_files\audio_1721916526.mp3さいごに
ElevenLabsは環境構築や複雑な準備は不要で、簡単にAPI使えたり気軽に音声学習できる点が強いと思います。
同じ合成音声系でStyle-Bert-VITS2は環境構築や学習が大変だったので…
Style-Bert-VITS2について興味あれば以下で解説しています。
細かい調整やマージ機能など使い場合はsbv2が良いです。
また、ElevenLabsは多言語対応も簡単にできるので、今後様々な活用が見込めそうです。
導入が簡単なので私も今後、模索していきたいと思います。
そしてElevenLabsを導入したAIVtuber配信を現在予定しているので興味あれば以下からチェックしていただけると幸いです。
最後に私がプロデュースしているAIVtuberシロハナちゃんの宣伝をさせてください。
理想のAIヒロインを目指して、AIを使ったリアルタイム配信や、AIヒロイン研究所というコンセプトのもと、「テクノロジー×キャラクター」に関する動画等を発信しています。
興味がありましたらぜひ!
以上!それではまた👋
いいなと思ったら応援しよう!
