Style-Bert-VITS2でささやきボイスを生成する【ヌルモデルマージ】

AIVtuberシロハナちゃんの開発プロデュースをしているyukiです。
このnoteではStyle-Bert-VITS2という合成音声技術を使ってささやき声を生成する方法について解説しています。
ささやきボイスのデモです!
— yuki@AIヒロイン研究P (@ai_shirohana) August 27, 2024
今週の土曜辺りにAIVtuberシロハナちゃん配信でASMR企画を計画中です。
ぜひ、チャンネル登録をしてお待ちください🌟https://t.co/vEZos4Pp45 https://t.co/1cBsGFe82E pic.twitter.com/moHr7wNXIO
Style-Bert-VITS2の概要や環境構築、各種使い方は割愛します。
下記の記事にてまとめてありますのでそちらをご覧ください。
また、本記事の内容は動画でもまとめてあります。
実際の音声デモなども含まれていますので、必要に応じて視聴いただけると良いかなと思います。
※この記事は2024/8/27時点のものなので今後変更があるかもしれないですのでご了承ください
ヌルモデル素材の用意
まずはヌルモデルというものがささやき音声モデルの作成には必要になるので用意します。
※もちろん、ささやき声にしたいモデルも必要なので、こちらは自由に用意してください
ヌルモデルとは?
いきなりヌルモデルと言われてもよくわからないと思うので概要を説明しておきます。
簡単に言うと、声の特徴"だけ"を抽出したモデルとなります。
イメージ例としては以下のような感じです。
2つの声を用意します:
声A:普通の声(例:普通に話すシロハナ)
声B:特殊な声(例:囁くシロハナ)
BからAを引きます(B - A)
結果:ささやき方の特徴だけが残ります
この「特徴だけ」を保存します
これがヌルモデルです!
素材のダウンロード
先ほどの例の通り、ささやき声にしたい元の声(A)とささやきだけを抽出したヌルモデル(B)が必要になります。
Aのモデルに関しては特に縛りないので自由に用意してください。
問題はヌルモデル(B)ですが、既に素材があるので今回はそれを使っていこうと思います。(加重和でも作れるみたいですが今回はパス)
上記サイトにアクセスして、sbv2\Style-Bert-VITS2\model_assets階層にクローンして配置します。
# インストール済みだったら不要
git lfs installgit clone https://huggingface.co/litagin/sbv2_null_modelsGIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/litagin/sbv2_null_modelsこれで他のモデルと同様に各ヌルモデルを配置して準備はOKです。
ヌルモデルマージをする
では準備が出来たらヌルモデルマージをしてささやき音声のモデルを作成していきましょう。
マージのイメージは以下のような感じです。
イメージ例)
2つのモデルを準備:
A:変えたい声(通常の声)
B:ヌルモデル(ささやき声の特徴)
重みを設定:
A:1.0
B:0.5(ささやき具合を調整)
マージする
結果:囁く音声モデルの完成!
調整:
重みを変えてささやき具合を微調整
何度か試して最適な声を見つける
モデル選択してセット
クローンした素材のヌルモデルは4つあり、それぞれについてまず簡潔に説明します。
whisper1_null:ささやき(無声)
whisper2_null:ささやき(有声)
flat_null:棒読み
minus_flat_null:大げさな抑揚
ここらひとつをヌルモデルマージの画面でBにセットします。
ささやき音声にしたいモデルに関してはAにセットします。

Bにささやきヌルモデル
このWebUIはsbv2\Style-Bert-VITS2階層のApp.batで開きます。
マージパラメータ調整してマージ

マージするモデルをセットしたら下にスクロールして、作成するモデル名を入力するのと、各種パラメータを調整していきます。
パラメータについては以下の4つがあります。
声質
声の高さ
話し方(抑揚・感情表現等)
話す速さ・リズム・テンポ
基本的にはそれぞれ0~1の間で調整していきます。
値が大きくなればなるほどその項目がささやきヌルモデル側に寄ります。(つまりささやき具合が強くなるイメージ)
ここは各モデルや目指したい音声によって変わってくるので最適な値は何回か試しながら調整していきましょう。
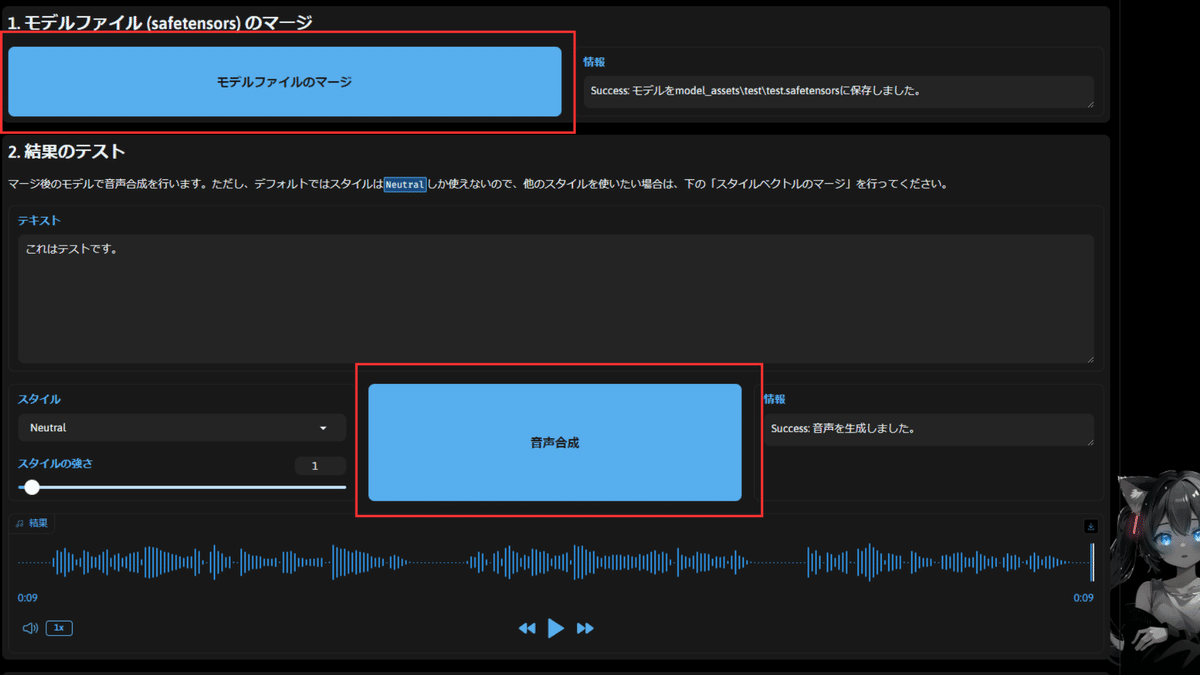
パラメータをセットしたら、「モデルファイルのマージ」「音声合成」でその音声を聴くことができます。
ちなみにAIVtuberシロハナの場合は「声の高さ」の値を大きく(0.9や1など)したところ、かなりささやき具合がアップしました。
これで最適なささやき音声モデルができたら完成です!
エディターやAPIにてそのささやき音声モデルを使うことができます。
最後に
今回はヌルモデルマージでStyle-Bert-VITS2でささやき音声生成するまでの手順と説明をしました。
他にも差分マージや加重和などもあり、かなりカスタマイズに富んでおり自由度が高いです。
ただ、それらは少し複雑かなと思い、今回は素材をもとにヌルモデルマージで、ささやきモデルを作ってみました。(最後に公式の参考記事貼っておきます)
ヌルモデルマージであれば比較的シンプルに作れると思うのでぜひ試してみてください。
また、今回の手順をもとに、私が開発をしているAIVtuberシロハナちゃんにささやきボイスを導入してASMR配信をする企画を予定しています。
どのように活用されるのか興味ある方は要チェックです。
配信は以下から参照できます。
以上!それではまた👋
参考記事
いいなと思ったら応援しよう!
