
ComfyUI HunyuanVideo 高速化をめざして

HunyuanVideo重いわー。
LowVRAMでの高速化と言えば、やっぱりGGUFの利用でしょう。検索してみると、GGUFのモデルも公開されていました。
ここから、hunyuan-video-t2v-720p-Q4_K_M.gguf を取ってきました。
せっかく16GBになったことなので、Q8_0でもよかったけど、ここは速さ優先でQ4_K_Mにしました。
ComfyUIで「Unet Loader(GGUF)」を出して、モデルをつなぎ替えます。

では、やってみます。

できた。
Prompt executed in 848.13 seconds
前回、GGUFでないもので、初回が1000s以上かかっていたので、ちょっと速くなりました。最初のモデルの読み込みが圧倒的に速かった感じです。でも、その先は同じようなスピードでした。

2回目に期待して、もう一度。
Prompt executed in 805.75 seconds
え?大して変わってない。
GGUFじゃないものでも、800s台だったので差が無いってこと?

何か他に方法がないかと色々検索してみると、めっちゃ期待できそうなのを見つけました。
なんだこれ。ヤバイって言ってるぞ。
これは良さそうだわ。やってみよう。
説明をみると、1回目はそこそこ時間がかかるけど、2回目は同じ計算はキャッシュを使って飛ばすから速くなるってことらしい。
ComfyUI Manager で検索しても出てこなかったので、Installation に書かれている通り、
cd custom_nodes
git clone https://github.com/chengzeyi/Comfy-WaveSpeed.git
これで追加。
ワークフローも色々置いてあるので、workflows/hunyuan_video.json を取ってきた。
これをポイっとしてみると、
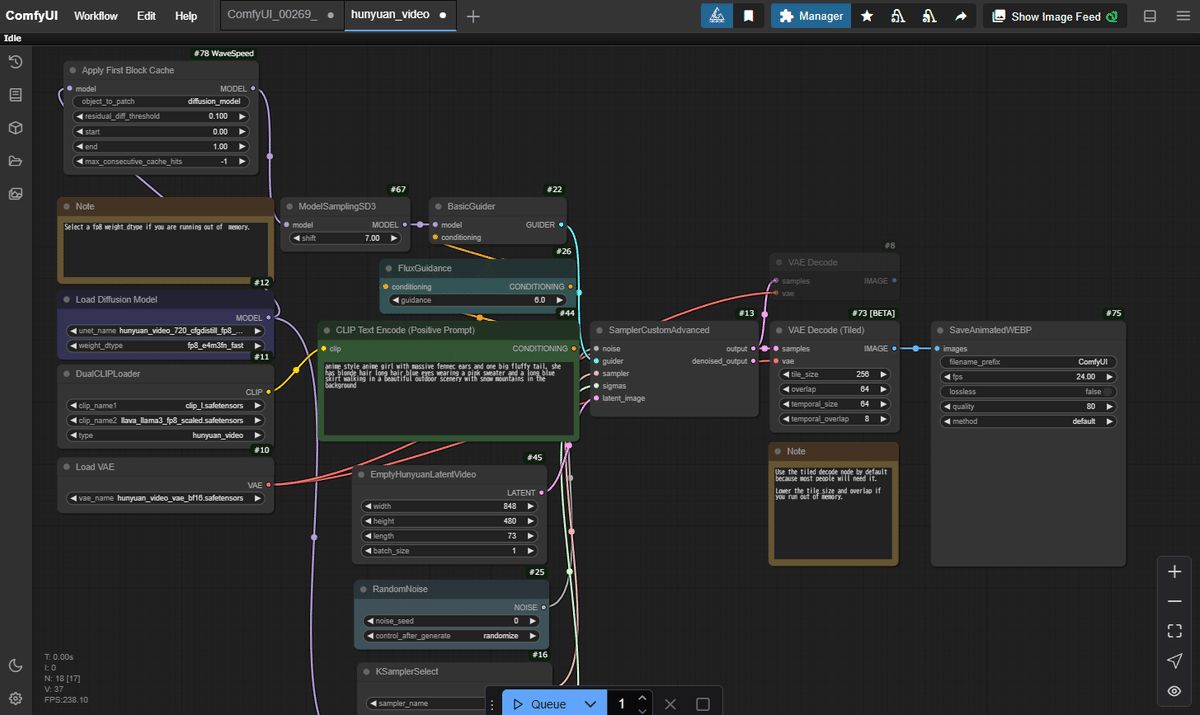
えっと、どこが変わったかな?
これか。

「Apply First Block Cache」っていうのがモデルの後に追加されただけのようです。
モデルは、hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors になってるけど、hunyuan_video_t2v_720p_bf16.safetensors でやってみます。
では、いってみよう。
Prompt executed in 1434.28 seconds
え?めっちゃかかったんだけど。24分。
寝そうになったわ。

喧嘩売ってくるヤンキーの動きやん
まぁまぁ、2回目はキャッシュのお陰で速くなるはずだからね。
よし、やってみよう。
rompt executed in 998.14 seconds
は?なんもしないほうが速いやん。16分って。

無表情で近寄ってくるな
そもそも、16GB程度のVRAMで動かすようなものじゃないってことなのかも。
ここの、First Block Cacheの説明の中にも、
NOTE: To run HunyuanVideo, you need to install diffusers from its latest master branch. It is suggested to run HunyuanVideo with GPUs with at least 48GB memory, or you might experience OOM errors, and the performance might be worse due to frequent memory re-allocation.
日本語訳
注意:HunyuanVideoを実行するには、最新のマスターからdiffusersをインストールする必要がありますbranch.Itは、少なくとも48 GBのメモリを搭載したGPUでHunyuanVideoを実行することをお勧めします。そうしないと、OOMエラーが発生し、頻繁なメモリ再割り当てによりパフォーマンスが低下する可能性があります。
って書いてある。
まさに、パフォーマンス低下を起こしてる。
それにしても、48GBって。庶民には無理やって。
この後、torch.compile っていうのも試してみようと思ってたけど、これはちょっとダメかも。
3秒の動画のために、10分以上も待てんわ。
うーん。
あ、「Apply First Block Cache」の付いたやつで、モデルをGGUFにしてみるか。

Unet Loader(GGUF)を出して、モデルをつなぎ替えてみた。これに対してもキャッシュできるのかどうか知らんけど。
では、やってみよう。
Prompt executed in 508.26 seconds
おー、1回目から8分半。いいね。でも、なんで?1回目なのに。

じゃあ、2回目。
Prompt executed in 468.27 seconds
あれ、もっといけるかと期待したけど。
それでも8分を切りました。

これなら、torch.compile を試してみる価値もあるのかも。
とりあえず、今日はここまで。
ではまた。