
傾向スコアリングによるパーソナライゼーションの開始

下記ブログの翻訳です。6.3.2022
ECサイトやストリーミングサービスなどで自分の好みのものが見やすく提示されるのはある意味便利な機能です。その裏側で動いている「パーソナライゼーション」はAI抜きには語れません。「xx%あなたに合致しています」を導きだすことは今や企業に課された大きな課題でもあります。それらをDatabricksでどのように実現しているか、が語られています。(北原)
消費者は、パーソナライズされた方法でサービスを受けることをますます期待するようになっています。最近購入した商品を紹介するeメールのメッセージ、よく閲覧するカテゴリの商品のセールを知らせるオンラインバナー、または開示した興味に沿ったコンテンツなど、消費者はお金を使う場所の選択肢を増やし、個人のニーズや好みを認識してくれる店舗との取引を希望しているのです。
マッキンゼーMcKinseyによる最近の調査では、消費者の約4分の3が、ショッピング体験の一部としてパーソナライズされた対応を期待していることが明らかになりました。この調査に含まれる調査では、パーソナライズをうまく活用している企業は、40%以上の収益を上げることができるとされており、パーソナライゼーションは小売業のトップ企業にとって重要な差別化要因になっています。
しかし、多くの小売業者はパーソナライゼーションに苦労しています。フォレスタForrester社の最近の調査では、米国の消費者の30%と英国の消費者の26%だけが、小売業者が自分に関連する体験をうまく作り出していると考えていることがわかりました。3radicalの別の調査では、カスタマイズされた推奨品を受け取ったと強く感じた回答者はわずか18%で、52%が無関係なコミュニケーションやオファーを受け取ることに不満を表明しています。消費者がブランドや販売店を変える力を増している今、パーソナライゼーションを正しく行うことは、ますます多くの企業にとって優先事項になっています。
パーソナライゼーションはジャーニー(旅のようなもの)
パーソナライゼーションに初めて取り組む企業にとって、One to Oneエンゲージメントを実現することは困難なことのように思われます。このアプローチに必要なデータを収集するために、サイロ化したプロセス、不十分なデータ管理、データプライバシーに関する懸念などをどのように克服すればよいのでしょうか。限られたマーケティングリソースの中で、どのようにパーソナライズされたコンテンツやメッセージを作成すればよいのでしょうか。また、作成したコンテンツが、ニーズや嗜好が変化する個人に対して効果的にターゲット化されていることを確認するには、どうすればよいのでしょうか。
パーソナライゼーションに関する多くの文献は、その斬新さ(ただし、必ずしも効果的とはいえない)が際立つ最先端のアプローチを紹介していますが、現実には、パーソナライゼーションは旅なのです。初期の段階では、プライバシーと顧客の信頼を維持しやすいファーストパーティデータを活用することが重視されます。実績のある機能を前進させるために、ごく標準的な予測技術が適用される。価値が実証され、組織がこれらの新しい手法に慣れるだけでなく、それらを業務に統合する様々な方法を開発するにつれて、より洗練された手法が採用されるようになる。
傾向スコアリングは、しばしばパーソナライゼーションへの第一歩である
パーソナライゼーションの最初のステップは、販売データを調査して顧客の嗜好を把握することである。傾向スコアリングと呼ばれるプロセスでは、企業は、オファーや製品のサブセットに関連するコンテンツに対する顧客の潜在的な受容力を推定することができます。このスコアを用いて、マーケティング担当者は、数あるメッセージの中から特定の顧客に提示すべきものを決定することができます。同様に、このスコアを使用して、特定のエンゲージメントに対してより受容的な顧客セグメントを特定することもできます。
傾向スコアリングの出発点は、過去のインタラクションから得られる数値属性(特徴量)の算出です。これらの特徴量には、顧客の購入頻度、特定の製品カテゴリに関連する支出の割合、最後の購入からの日数、その他履歴データから得られる多くの測定基準が含まれます。次に、これらの特徴量を算出した期間の直後の履歴期間において、特定のカテゴリー内の製品の購入やクーポンの利用など、関心のある行動を調査します。その行動が観察された場合、その特徴量にはラベル1が付けられ、そうでない場合は、0が割り当てられます。
データサイエンティストは、この特徴量をラベルの予測因子として、対象となる行動が発生する確率を推定するモデルを学習することができます。この学習したモデルを直近の期間に計算された特徴量に適用することで、マーケティング担当者は、顧客が予測可能な将来にその行動をとる確率を推定することができるのです。
多数のオファー、プロモーション、メッセージ、その他のコンテンツが自由に利用できるため、それぞれ異なる行動を予測する多数のモデルが、この同じ特徴量セットに学習され適用されます。各行動のスコアからなる顧客ごとのプロファイルが作成され、下流のシステムに公開され、マーケティング担当者がさまざまなキャンペーンの編成に使用するようになります。
Databricksが提供する傾向性スコアリングのための重要な機能
傾向性スコアリングは簡単なように聞こえますが、課題がないわけではありません。傾向性スコアリングを導入している小売企業との会話では、しばしば同じ3つの質問に遭遇します。
傾向モデルのトレーニングに使用する100から時には1,000のフィーチャーをどのように維持すればよいのか?
マーケティングチームが推進したい新しいキャンペーンに合わせて、どのように迅速にモデルをトレーニングするか?
顧客パターンの変化に応じて再トレーニングしたモデルを、スコアリング・パイプラインに迅速に再展開するにはどうしたらよいでしょうか?
Databricksでは、企業のエンドツーエンドのニーズを念頭に置いて構築された分析プラットフォームを通じて、お客様のお役に立つことに重点を置いています。そのため、特徴量(フィーチャー)ストア、AutoML、MLFlowなどの機能をプラットフォームに組み込んでおり、これらの機能は堅牢な傾向スコアリングプロセスの一部として、これらの課題に対処するために使用することが可能です。
特徴量ストア(Feature Store)
Databricks Feature Storeは、様々なモデルトレーニングにおいて特徴の永続化、発見、共有を可能にする一元化されたレポジトリです。特徴量を取得すると、その系統や他のメタデータも取得されるため、他の人が作成した特徴量を再利用したいデータサイエンティストは、安心して簡単に再利用することができます。標準的なセキュリティモデルにより、許可されたユーザーとプロセスのみがこれらの機能を使用できるようにし、データサイエンスプロセスがデータアクセスに関する組織のポリシーに従って管理されるようにします。
AutoML
Databricks AutoMLを使用すると、業界のベストプラクティスを活用してモデルを迅速に生成することができます。グラスボックス・ソリューションとして、AutoMLはまず、シナリオに沿ったさまざまなモデルのバリエーションを表すノートブックのコレクションを生成します。異なるモデルを繰り返しトレーニングして、データセットに最適なモデルを決定すると同時に、各モデルに関連するノートブックにアクセスできるようにします。多くのデータサイエンスチームにとって、これらのノートブックは、モデルのバリエーションをさらに検討するための編集可能な出発点となり、最終的に、目的を達成できると確信できる学習済みモデルに到達することを可能にします。
MLflow
MLFlowは、Databricksプラットフォームで管理されるオープンソースの機械学習モデルリポジトリです。このリポジトリにより、データサイエンスチームは、AutoMLとカスタム学習サイクルの両方によって生成された様々なモデルの繰り返しを追跡し、分析することができます。また、ワークフロー管理機能により、学習済みモデルを開発から実運用に迅速に移行させ、学習済みモデルをより即座に運用に反映させることができます。
Databricks Feature Storeと組み合わせて使用すると、MLFlowで保持されたモデルは、トレーニング中に使用された特徴量に関する知識を保持します。推論のためにモデルを取得する際、この同じ情報によってモデルはフィーチャーストアから関連する特徴量を取得することができ、スコアリングのワークフローを大幅に簡素化し、迅速な展開を可能にします。
傾向性スコアリングワークフローの構築
これらの機能を組み合わせて、多くの組織が傾向性スコアリングを3つのワークフローの一部として実装しているのを私たちは見ています。最初のパートでは、データエンジニアがデータサイエンティストと協力して傾向性スコアリングに関連する特徴を定義し、それらを特徴量ストアに格納します。その後、毎日、あるいはリアルタイムの特徴量エンジニアリングプロセスを定義し、新しいデータのインプットに合わせて最新の特徴量を計算します。
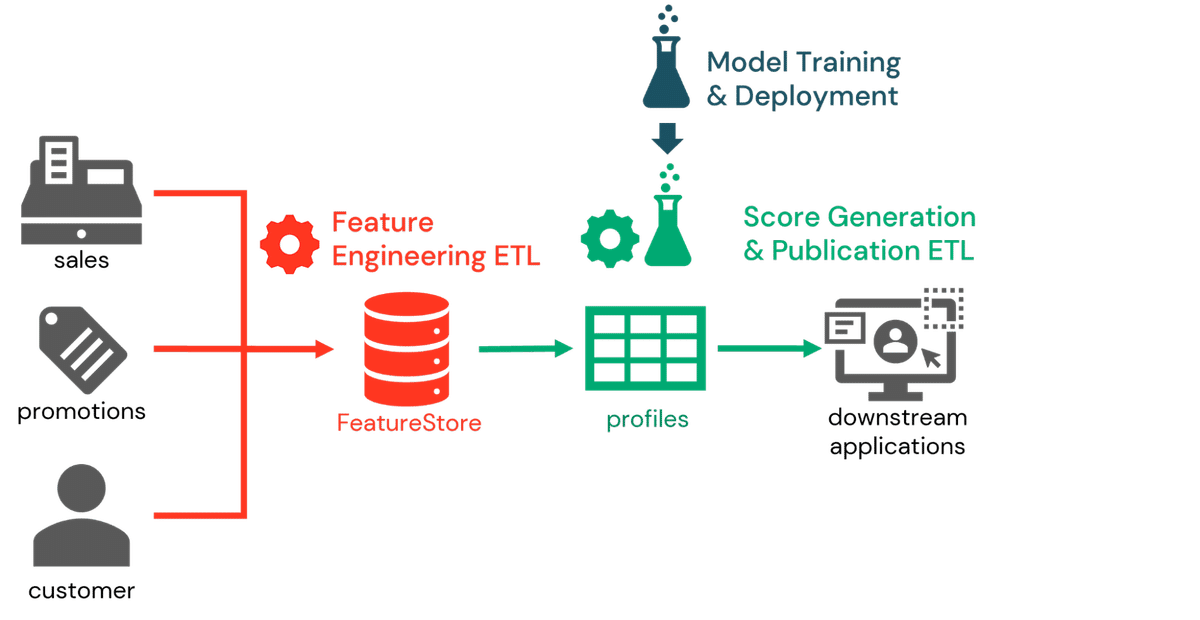
次に、推論ワークフローの一部として、顧客識別子を事前にトレーニングされたモデルに提示し、利用可能な最新の特徴量に基づいた傾向スコアを生成します。モデルとともに取得された特徴量ストア情報により、データエンジニアは比較的容易にこれらの特徴量を取得し、必要なスコアを生成することができます。これらのスコアはDatabricksプラットフォーム内で分析するために保存されることもありますが、より一般的には下流のマーケティングシステムに公開されます。
最後に、モデルトレーニングワークフローでは、データサイエンティストが傾向スコアモデルを定期的に再トレーニングし、顧客行動の変化を捉えます。これらのモデルがMLFLowに保持されると、変更管理プロセスが採用され、モデルを評価し、組織の基準を満たしたモデルを本番環境に移行させる。推論ワークフローの次の反復では、各モデルの最新の製品版が取り出され、顧客スコアが生成されます。
これらの機能がどのように連携しているかを示すために、一般に公開されているデータセットに基づく傾向スコアリングのエンドツーエンドのワークフローを構築しました。このワークフローは、上記のワークフローの3つの脚を実演し、Databricksの主要な機能を使用して効果的な傾向性スコアリングパイプラインを構築する方法を示しています。
このアセットをダウンロードして、Databricksプラットフォームを使ってパーソナライゼーションの基盤を構築するための出発点としてご利用ください。