
【Data analytics】SEMによって、満足度の要因分析にトライ

What/Why is SEM?
SEM(別名:共分散構造分析、構造方程式モデリング)は因果関係を説明する上でとても有効な分析手法です。細かな説明はアイシアさんの動画がわかりやすいです。SEMで使われている方程式の正体や具体例が丁寧に説明されています。
(動画終盤)
謎の変なおっちゃんが言ってるのではなく、データが導いてくれる。
前提の確認(使う言語・使うデータ)
【使うツール】
私は学生時代に、「消費者はなぜ000を使うのか/使い続けるのか/人に推奨するのか」を心理に着目して、このSEMを活用して、因果関係の解明を試みました。学生時代はSPSS(大学で無料で使用できた)を使っていました。卒業後は高くて使えず、今回はPythonを使用して分析していきます。コードについては本記事の最後かGItHubに載せてるのでご興味ある方は確認してみてください!
【使うデータ】
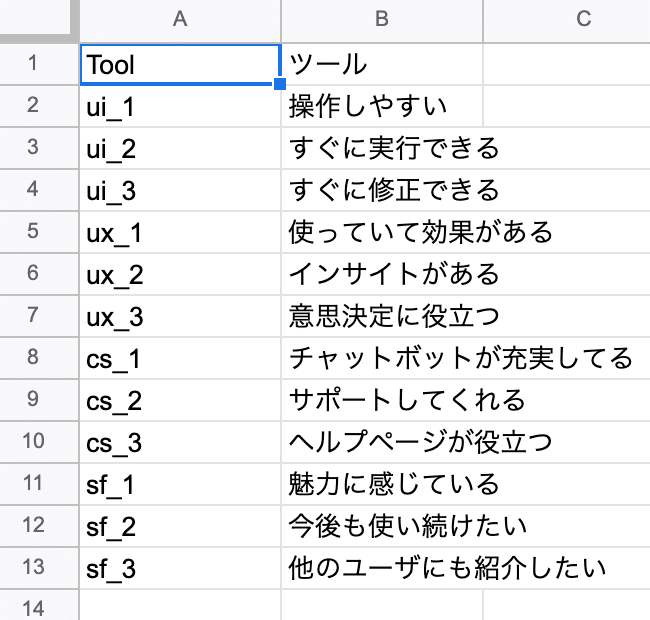
今回使うデータは、あるAIソリューションの製品評価に関する仮想データです。(図表1,2)
このデータを使って、満足度に影響する要因を調査しようと思います。

やってみる(PythonでSEM)
【PLAN:仮説】
AIソリューションにより、働き方が大きく変化していることから、以下の仮説を立てました。
H1:AIソリューションのUXは満足度に正の影響がある
AIソリューションの操作性が他社の同サービスよりも優れていると、満足度を感じやすいと予想し以下の仮説を立てました。
H2:AIソリューションのUIは満足度に正の影響がある
AIソリューションを運用する会社のカスタマサポートが充実していると顧客は満足度を感じると予想し以下の仮説を立てました。
H3:AIソリューションのCSは満足度に正の影響がある
【DO:実装】
上記の仮説を想定を検証すべく、Pythonを用いてSEMを実装してみました。
【CHECK:評価】
モデル精度は図表3の通りです。
chi2 p-valueがかなり小さく、5%有意で棄却されます。
これは、大標本の場合、棄却されたとしても、そのほかの指標の当てはまりが良ければ問題ないです。
ところが、小標本の場合は、棄却されないことが必要です。今回用意したデータは標本サイズが20と、小標本といえるため、このモデルを受け入れるのはまずいです。
一応、そのほかもかいつまんで見てみますが、
0.95以上が望ましい、CFI,GFI,AGFI,NFIはいずれも0.9以下で適合度の低さを伺えます。(評価指標の見方はこちらが参考になるかと思います。)

適合度が低いという前提ですが、パス図とその結果(図表4)を確認していきましょう。結果は有意水準5%に設定し、p値から解釈していきます。各観測変数から潜在変数はおおむね1周辺の値を刻んでおり、p値も有意水準以下であることから、潜在変数から説明できる部分が大きいと言えるでしょう。一方、潜在変数から潜在変数へのパスはui,uxはマイナス、csのみプラスで、いずれのパスもp値が有意水準以上で棄却できませんでした。よって、統計解析を通して、満足度の要因を説明できるモデルではなかったと言えます。

【ACT:示唆出し】
今回モデルが悪い中でのトライでした。想定される原因とその解決方針を示して終えようと思います!
具体的には、So what?方式で、検討してみます!サンプルサイズを大きくするというのは自明なのでそれ以外の、解決方針を考えてみます。
・モデルが当てはまってない。つまり、パス図が悪い?
・パス図が悪い。つまり、説明しきれていない?
・説明しきれていない。つまり、説明変数に抜け漏れがある?
・説明変数に抜け漏れがある。つまり、満足度につながる要因のサーベイが必要?
・満足度につながる要因のサーベイが必要。つまり、実際にそのソリューションを使ってみて、何が良い・悪いを感じることが大事?
まとめると、モデルの当てはまりの悪さは、満足度を説明できる説明変数に抜け漏れがあると推察しました。1階層の構造だったのですが、満足度要因は2階層、3階層と複雑な要因と構造によって、説明できるかもしれません。なので、実際に調査対象のAIソリューションを触ってみたり、体験者にサーベイしたりすることから、新たな仮説を立てることが大事かもしれません。そうすることで深い洞察を得られると思いました。
まとめ
初めて、PythonをつかってSEMにトライしてみました。実装自体は簡単で機会があれば積極的に使ったり、周りに推奨したりしたいです。
モデルの当てはまりは良くなかったので、サンプルサイズの大きいデータを用意し、仮説検証を机の上でなく、実際の体験も含めて行うのが妥当でありそうだと再認識しました。
pip install semopy
pip install graphviz
pip install see
# import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from see import see
import graphviz
import semopy
from semopy import Model
# read datasets
df_all = pd.read_csv("datasets_for_SEM(structural equation modeling) - datasets.csv")
df_all.head()
df_all_2 = df_all
df_all_3 = df_all_2.drop('Tool',axis=1)
df_all_3
# 標準化(standardization)
df_all_4 = (df_all_3 - df_all_3.values.mean()) / df_all_3.values.std(ddof=1)
df_all_4
#潜在変数の設定(=~)、相関の設定(~~)、因果関係の設定(~)
mod = """
ui =~ ui_1 + ui_2 + ui_3
ux =~ ux_1 + ux_2 + ux_3
cs =~ cs_1 + cs_2 + cs_3
sf =~ sf_1+sf_2+sf_3
ux ~~ ui
ux ~~ cs
ui ~~ cs
sf ~ ui + ux + cs
"""
#モデル定義
model = Model(mod)
#パラメータ推定(df_all_4はdf_allを標準化)
result = model.fit(df_all_4)
# パラメータ推定結果の確認
inspect = model.inspect()
print(inspect)
semopy.semplot(model,"graph.png")
# モデル精度確認
stats = semopy.calc_stats(model)
print(stats.T)参考(GItHub含む)
コードの確認や仮想データのダウンロードはこちら→GitHub
SEMとは何か?どんな具体例があるか?→アイシアさん動画
Pythonでのコーディングはどのように行う?→@roki18dさん
評価指標をどう解釈する?→構造方程式モデリングの基礎 - 京都大学大学院 教育学研究科
*Top picture は佐々木朗希選手が京セラドームで登板した試合(2022年4月)