
【Data analytics】Rで因子分析(Factor Analysis)・クロンバックα算出を試みる

なんでやるの?
因子分析はデータの裏側にある共通した因子を見つけるため。これにより、新たな軸ができるイメージ。軸出しはマーケティングなどで活かそうです(最後の方で、因子分析の応用例に触れられています→AiciaさんYoutube)。
クロンバックα算出は信頼性の確認のため。変数の調査とそれに紐づく質問を用意する際、本当にその質問でいいのか、信頼できるのか?この問いに答えるべく、統計処理を行い、信頼性を確認します!(詳しくは、Rによるやさしい統計学)
実際にやってみる
前提となる設定や要件は以下の通りです。
部門ごとのAIソリューション調査を行い、今後の商品開発、マーケティング施策、営業活動に役立つ情報を整理する。部門のスコープは、HR、コールセンター、工場の3部門とします。
質問データをもとに因子分析を行い、クロンバックαで質問項目の信頼性もチェックします。
最後に各部門ごとの特徴を把握するために、縦軸に質問項目の平均を、横軸に各部門を設定し、折れ線グラフを作ります。
(蛇足)恣意的に質問項目やデータを設計していますが、主旨はRを触ること、Rの結果を確認して考察することにあるので、ご承知を!
続いて、質問項目と回答データ(仮想)です!

(9行目はミスタイピングです。。Rではp_1.1と表示されてます。ご注意ください。)

次に因子分析を行ってみます。(全体のスクリプトは最後に添付しています。)
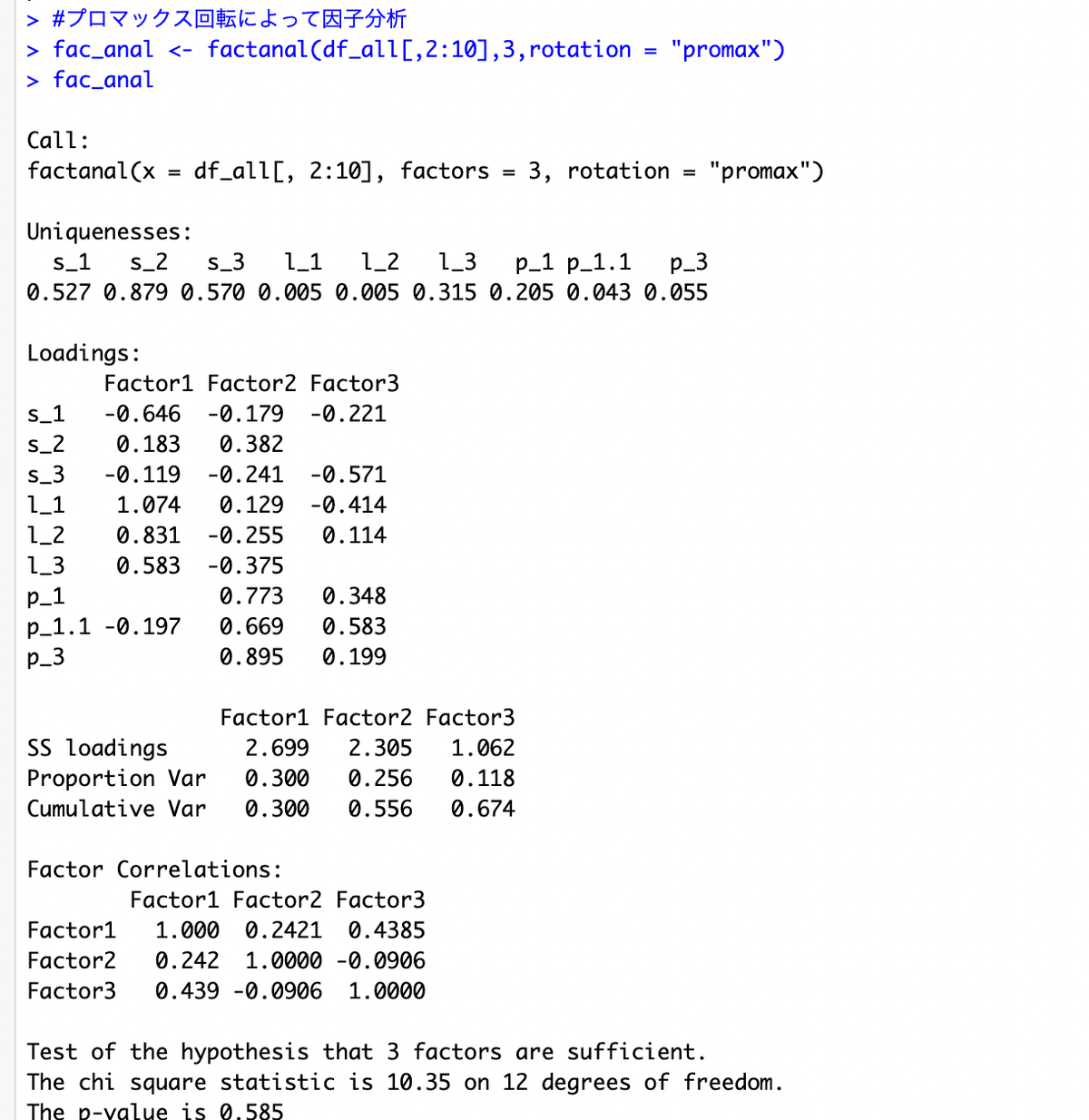
ここから、以下のことが言えそうです。
カイ二乗値が10.35、自由度12、p値0.585で、3因子モデルはデータと適合していると考えられます(図表3の下部)。
Uniquenessesを確認すると言語(l)、画像(p)に関する要素は値が小さくなっています(すなわち共通性(=1-Uniquenesses)が大きく、因子で説明できる部分が大きい。言い換えると、因子で説明できない部分が小さい)。一方、音(s)に関する要素はUniquenessの値が大きい(すなわり共通性が小さく、因子で説明できる部分が小さい。言い換えると因子で説明できる部分が大きい)結果となり、(s)については、質問項目の変更も考慮に入れなければならないです(図表3の上部)。
Factor1では、言語(l)における3つの質問項目の値(因子付加)が大きいため、言語因子としましょう(自明でしたが)。Factor2では、画像(p)における3つの質問項目の値(因子付加)が大きいため、画像因子としましょう(自明でしたが)。Factor3では、綺麗な数値が出ておらず、対応方法がわからず、困惑中です。(図表3のLoadings部分)。
まだ、Factor3の話ですが、「項目を削除して再度因子分析してみる」、「因子の数を変えて再調査してみる」がありそうです。今回の私の記事では試せていないですが、次回の気候で対応できるようにしたいと思いました。(参考レポート・・・数式少なめですが、分析の流れを理解する上で、わかりやすいと思います!)
続いて、クロンバックαによって信頼性を確認します。

ここから以下のことが言えそうです。
言語、画像に関する質問項目はクロンバックアαが1に近く、信頼性が高いといえます。そのまま使えそうですね。
音(s)に関する質問項目はクロンバックαが0以下(1から離れており)であり、信頼性が低いといえそうです。
仮にこの調査が、プレ調査であれば、本調査に向けて質問項目の見直しも検討しないとですね。
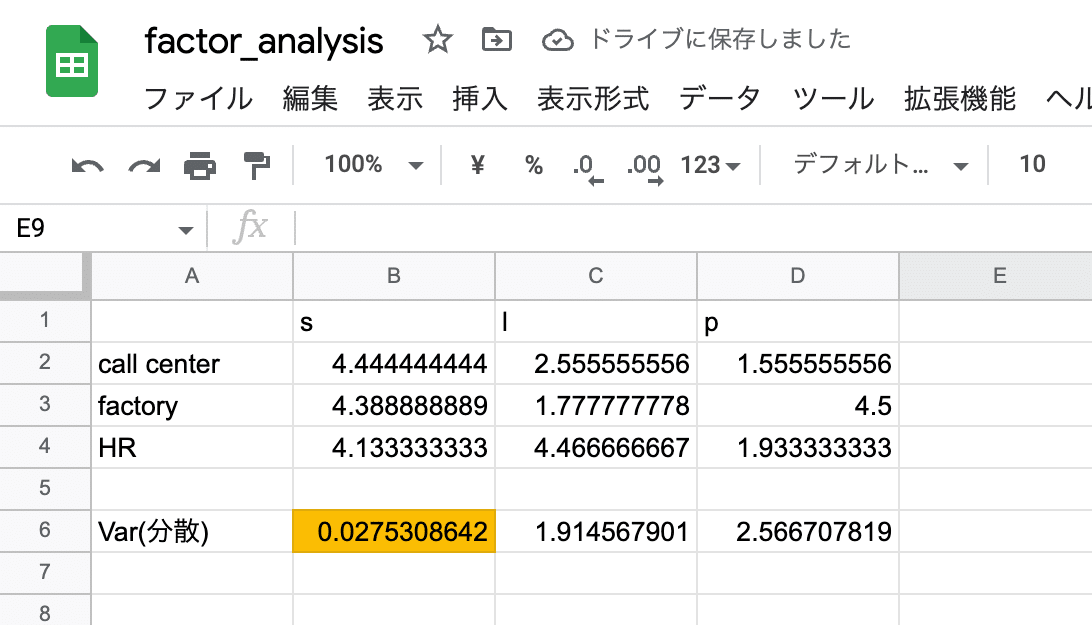
なぜ、音(s)は渋い結果を出すのかを検討してみました。まず各Functionにおける回答データ平均と平均の分散を計算した図表5を確認ください。音(s)に関する質問はいずれのFunctionでも4〜5をつけており、結果、分散が小さくなっています。要は、せっかく質問したのに、差が出ない質問項目なのです。言い換えると、この質問項目は必要なのか?もっと差が出るように質問しないといけないのではないか?という意味だと思います。一方、この質問項目は各Functionで4〜5を取っていて、分散も小さいことから、音データを活用したAIは、ほぼどのFunctonでも求めらるインフラ的な要素であるとも解釈できそうです。ポジティブネガティブの両面から考えてみましたが、いずれにせよFunctionごとの特徴を見出すには音(s)は十分な質問ではなかったということになりそうです。
最後に総じて何が言えそうか?まとめてみます。
図表6をご覧ください。因子分析によって質問項目から3つの因子を特定し(今回は音(s)も因子の一つとして、検証を進めます)、それぞれの質問データの平均をとったものです。
コールセンターは音を重視したAIソリューションが需要としてありそうですね。コール発信者のニーズ分析としてAI活用が見込まれそうですね。
次に、工場では、音や画像を重視したAIソリューションが需要としてありそうですね。ロボットが音や画像をもとに、正確な製造につなげることが見込まれます。
最後に人事部では、音や文字を従事したAIソリューションが需要としてありそうですね。もしかしたら面接前の書類選考時や面接中においてAIソリューションの活用見込みがあるかもです

今回の反省や次回やりたいこと!
因子分析によって得られた因子とその因子を用いた簡単な統計値比較を行いました(最後は平均のみの比較となりお許しを。。。)
質問調査で用いたデータの信頼性をクロンバックαで確かめました。
特に分散が小さい質問項目は、「本調査では質問文を変えてみる」や「もしかしたらこの質問自体、当たり前すぎて取る意味ないかも」など検討できるポイントがいくつもあるという発見がありました。
次は因子分析の発展版ともいえる、共分散構造分析(SEM)にトライしてみます!
# コールセンター、HR、工場部門に対するAIソリューション調査
#csvインストール
df_all <- read.csv("factor_analysis - シート1.csv",header = TRUE)
df_all
#相関係数行列
cor_matrix <- cor(df_all[,2:10])
cor_matrix
#プロマックス回転によって因子分析
fac_anal <- factanal(df_all[,2:10],3,rotation = "promax")
fac_anal
#最後にクロンバックαを算出し、質問項目の信頼性をチェック
#①音声に関する質問項目のクロバックα→-0.28
library(psy)
tmp1 <- df_all[2:4]
tmp1
sum_score <- rowSums(tmp1)
tmp2 <- cbind(tmp1,sum_score)
tmp2
cronbach(tmp2[,1:3])
#②言語に関する質問項目のクロバックα→0.91
library(psy)
tmp3 <- df_all[5:7]
sum_score <- rowSums(tmp3)
tmp4 <- cbind(tmp3,sum_score)
cronbach(tmp4[,1:3])
#③画像に関する質問項目のクロンバックα→0.94
library(psy)
tmp5 <- df_all[8:10]
sum_score <- rowSums(tmp5)
tmp6 <- cbind(tmp5,sum_score)
cronbach(tmp6[,1:3])
参考(GitHub含む)
因子分析の考え方や応用例は何?→AiciaさんYoutube
因子分析やクロンバックαのR実装と解釈をどのように行う?→Rによるやさしい統計学
因子分析のフローはどんな?因子分析で困った時にとるべき対応は?→脇田さん・浦上さんレポート
因子分析の後、マーケティングでどんな使い方してるのか?→インテージさんの記事
クロンバックαの数式はどんなものか?→統計WEB
練習や確認にお使いください→GitHub
*Top Pictureは青森の酸ヶ湯温泉近く!(5月)