tiger book読書記録 chapter 2

tiger book読書記録 chapter2編
August 15, 2018
MLの機能が気になったのでMLのtutorialを読む。一通りの機能を通すがfanctor, signature, structureの記法が曖昧なままだ。MLの勉強が主目的ではないので、おいおい必要になった時にまた、復習することにする。しかし、tutorialや入門編のtext bookらしきものを眺めているとfunctional programmingである為かlambda calculusの片鱗が垣間見える。出自から知てやっぱり理論よりなるのは、仕方がないことか。
MLで学んだこと
- as記法
- functorの書き方。引数の指定の仕方がよくわからない。functor F(S: SIG)とfunctor F(structure S: SIG)の違いって何?
- まだ理解してないもの。abstype, withtype構文, sharing, include
明日以降tiger bookへ戻ることにする。
August 16, 2018
chapter 2本文を読んだ。字句解析の基本である、regular expression, non deterministic finite automaton(NFA), deterministic finite automaton(DFA)が解説されている。まぁ、基本ですな。regular expressionからNFAを構成しprogram処理させる為にDFAに変換する。NFA -> DFAの変換は幅優先で処理すればnon-determinismを回避することが出来てdeterministicになるということか。人間が処理する場合は深さ優先でやったほうが解りやすいような気がするが、codeには落としづらいのだろうな。これだけの事が十数ページで解説されている。密度高いな。で結局Lex-MLなるML上でのlex処理系を使うのね。と思ったら、lex-MLはこの著者が作ったんやないかい。まぁ、今更字句解析の様な古典的理論を頑張ってやってもその先の発展はないのでさっくり理論を説明したあとlexの使い方で良いのかもしれない。興味ある人は論文参照かlex処理系を読めということで。明日から演習問題に移る。
August 17, 2018
exercise 2.1
a. [ac]*a.*b.*
ここで、文字列は少なくとも1つのaとbを含むとする
b. [bc]*(a[bc]*a[bc]*)*
c. 1.*100
d. 1.*......|11....|1011..|10101.
e. ((b+a?c)?[ac]*)*
f. 0[1-9][0-9]*|[1-9][0-9]*
g. 1|10eを解くのに手間取ってしまった。試行錯誤の末に辿り着いたけれど何かいい考え方があるのかしら。よくわからない。[追記september 4, 2018: DFAであれば、否定を受け付けるようにするのは難しくない。よって正規表現->DFAを行いDFA上で否定を演算を行う。受理、不受理の入れ替えるのはDFAでは難しくない。その後、regular expressionに戻せばよい。]
g.は問題がよく理解できない。フェルマーの大定理からするとn=1, 2(10進数)なのだけれど、これでいいのかしら。それとももっと深遠なのかな。翻訳が怪しいのかも。
exercise 2.2
a. 正規表現とDFAは等価と考えられるので、DFAで考える。DFAを使用した場合持てる状態は入力の位置とDFA上のどのstateにあるかを記録としているだけである。そのstateに至った過去の経緯は覚えていない。ここでaあるいはbの出現回数=過去の経緯なのでDFAに追加の状態無しには難しい。
b. 正規表現は文字列の先頭から解析するだけである。末尾から解析できない。
c.字句解析だけでは足りない。構文解析が必要。
exercise 2.3
a. 4桁2進数 (先頭は0で埋める)ただし0110は除く。
b. "a"が5n+1個並んだもの
c. むぅ、よくわからない。二進数な気もするけれど。少し考えてみるか。正規表現で書けば解るのかも。(0|(1(01*0)*1))* かな。でも余計わからなくなったなぁ。
今日はここまで。
August 18, 2018
exercise 2.4.a.
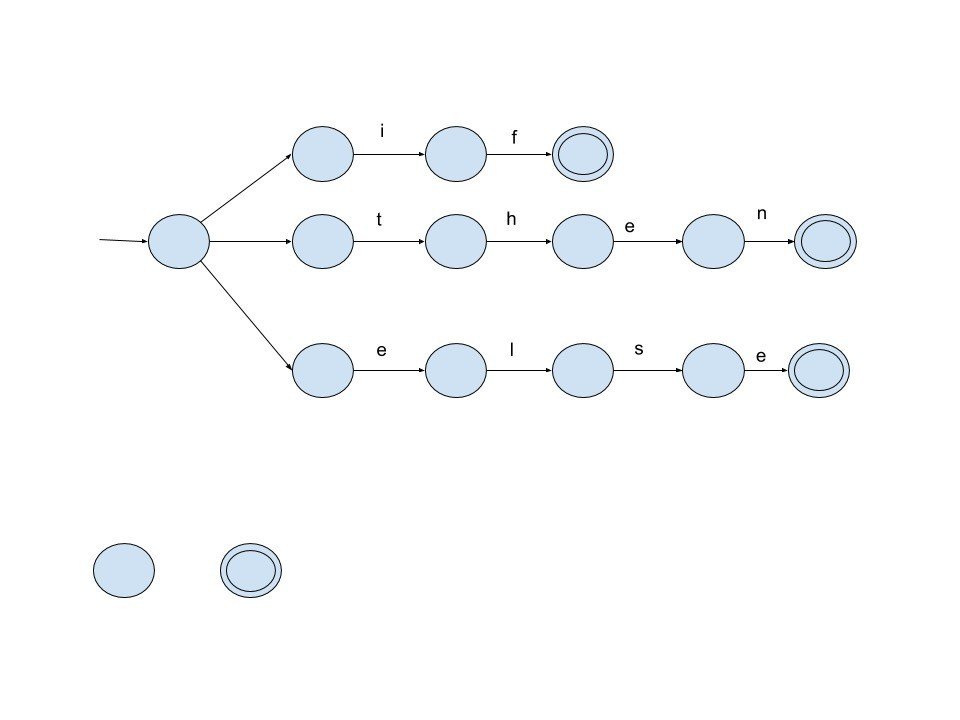
exercise 2.4.b

exercise 2.5.a

exercise 2.5.b

これは完全に失敗である。単純にDFA->NFAのアルゴリズムを適用したのが失敗なのだろうか。何がなんだか遷移を追うことが出来ない。時間がかかった割に出来上がったのがこれではがっかりだが、これをきれいに治すのも面倒なので、これで良いことにする。どこか間違っていても気づくのは無理だな。最初にaでの遷移を横方向に取ったのが間違いだったかも。正規表現だと (a|b)*a(a|b)(a|b)(a|b)(a|b)(a|b)なので簡潔なのだがDFAだと大変になるという見本で良問なのかも。もしかしてうまく正規表現を眺めると綺麗に書けるのか。多分(a|b)*aの部分をうまく展開しろというのが問題の趣旨か?
Auguest 21, 2018
exercise 2.5c

これは簡単。2.5bのと落差は何なのだろう。
exercise 2.6

なにかおかしい気がする。状態4に辿り着くことが出来ない。よって状態4は意味がないので削除した。問題の間違いかしら。
exercise 2.7
(0|1((01*0)*)1)*
exercise 2.8
問題が理解出来なかった。しようがないので原文を見たところ理解できた。これは訳がおかしいだろう。というか日本語になってない。問題の趣旨は「tokenの切れ目を認識するのに最大何文字先読みが必要になるか。また、その例を示せ。」
受理するtokenを次の様に命名する
- "+"
- "-"
- ID: [a-z][a-z0-9]*
- int: [0-9]+
- float: [0-9]+e("+"|"-")?[0-9]+ (+と-が正規表現と被ってるので""でくくった)
2.8aと2.8b
- トークン名: 先読みが必要な文字数:例(トークンの切れ目を|で示す。)
- "+": 0: +|a| (先読み必要なし)
- "-": 0: -|a| (先読み必要なし)
- ID: 1: a|+| ([a-z0-9]以外の文字を見つけてIDの最後が解る。)
- integer: 3: 1|e|+|a| (integerかfloatの違いを区別するのにe(+|-)?以降に数字か数字以外かを先読みする必要がある。)
- float: 1: 1e+1|a| (指数部の後に数字以外が来るのを先読みする必要あり。)
exercise 2.9
[追記: (aba)+を(aba)*と勘違いしている。NFAの時点で違っている。ぐはぁ。直す気力もないのでこのままとする。]
まずはNFAを作りDFAに変換した結果を次の図に示す。DFAでは状態番号を振り直した。赤の番号で新しい番号を示す。

次にedgeとfinalの内容を示す。DFAに示したものを行列に直したものである。indexは0から始まり状態0はerrorを示す。
val edges =
(* 0=error *)
vector [ (* a *) (* b *)
(* state error: 0 *) vector[ 0, 0, ],
(* state {1,2,6,9}:1 *) vector[ 1, 10, ],
(* state {3,7,10}: 2 *) vector[ 8, 3, ],
(* state {4,7}: 3 *) vector[ 4, 9, ],
(* state {2,5,8}: 4 *) vector[ 5, 0, ],
(* state {3}: 5 *) vector[ 0, 6, ],
(* state {4}: 6 *) vector[ 7, 0, ],
(* state {5}: 7 *) vector[ 5, 0, ],
(* state {8}: 8 *) vector[ 0, 0, ],
(* state {7}: 9 *) vector[ 8, 9, ],
(* state {11}: 10 *) vector[ 0, 0, ],
]
]
final:
0: 0
1: 0
2: 1
3: 0
4: 1 (*both action1 and action 3 match. action 1 has precedence*)
5: 0
6: 0
7: 1
8: 2
9: 0
10: 3星無し、星一つのexerciseはやって、星2つ、星3つは飛ばすことにする。
明日からはchapter 2のプログラム演習に取り掛かることにする。
august 21, 2018
演習用のprogramを実行しようとしてハマる。SMLNJ 100.79 (ubuntu packageでinstallされるもの)ではcompiler managerがnew versionらしい。でsources.cmも少し違うみたいで修正が必要だった。
CM.make "sources.cm";
で呼び出す必要がある。本ではCM.make()と書いてあるが変わったようだ。
diff --git a/tiger/chap2/sources.cm b/tiger/chap2/sources.cm
index 154039e..baa47c3 100644
--- a/tiger/chap2/sources.cm
+++ b/tiger/chap2/sources.cm
@@ -5,4 +5,5 @@ errormsg.sml
tokens.sig
tokens.sml
tiger.lex
-smlnj-lib.cm
+$/basis.cm
+$/smlnj-lib.cm
$ sml
...
- CM.make "sources.cm";
[New bindings added.]
val it = true : bool
- Parse.parse "test.tig";
...むぅ、今日は無駄に時間を溶かしてしまった。他のchap<N>/sources.cmも同様の変更が必要なのだろう。少し本が古いから仕方がないのかな。改訂版が出てもいいのに。明日からは演習に集中できるといいな。
August 23, 2018
プログラミング演習。lexの定義ファイルの書き方の練習である。tokenの定義は与えられているが何か気に入らなかったので書き換えたらハマってしまった。errormsg.smlはそのままで変更なし。
tokens.sml: 完全に書き換えた。
structure Tokens =
struct
type linum = int;
type base_info = { pos: int, lineno: linum, text: string};
datatype aux_info = INTVAL of int
| STRVAL of string
| NOVAL;
datatype token_type = WHILE
| FOR
| TO
| BREAK
| LET
| IN
| END
| FUNCTION
| VAR
| TYPE
| ARRAY
| IF
| THEN
| ELSE
| DO
| OF
| NIL
(* symbols *)
| COMMA
| COLON
| SEMICOLON
| LPAREN
| RPAREN
| LBRACKET
| RBRACKET
| LBRACE
| RBRACE
| DOT
| PLUS
| MINUS
| TIMES
| DIV
| EQUAL
| NOTEQUAL
| LESS
| LESSEQUAL
| GREATER
| GREATEREQUAL
| AND
| OR
| COLONEQUAL
(* literals*)
| ID
| INT
| STR
(* meta *)
| EOF;
type token = {token_type : token_type, info : base_info, aux : aux_info};
fun toTOKEN (tokenType, pos, lineNum, yytext) = {token_type=tokenType, info={pos=pos, lineno=lineNum, text=yytext} : base_info, aux=NOVAL} : token;
fun toINT (pos, lineNum, yytext) = {token_type=INT, info={pos=pos, lineno=lineNum, text=yytext} : base_info, aux=INTVAL (valOf (Int.fromString yytext))} : token;
fun toSTR (pos, lineNum, yytext) = {token_type=STR, info={pos=pos, lineno=lineNum, text=yytext} : base_info, aux=STRVAL(String.extract(yytext, 1, SOME (size yytext - 2)))} : token;
fun toEOF (pos, lineNum) = {token_type=EOF, info={pos=pos, lineno=lineNum, text=""} : base_info, aux=NOVAL} : token;
(* access method *)
fun getTokenType (t : token) = #token_type t;
fun getPos (t : token) = #pos (#info t);
fun getLineNum (t : token) = #lineno (#info t);
fun getText (t : token) = #text (#info t);
end初めはdatatypeにtupleを使っていたのだが値を取り出すうまい方法が見つけられなかった。そのためrecordで書き換えた。accessor methodに: tokenをつけて型を指定しないといけないのが気に入らない。というかそもそもaccessorが必要な時点でイケてない。pattern matchingを使うべきか。
tiger.lex: tokenの定義の変更に対する修正と不足分の追加
type lexresult = Tokens.token;
val lineNum = ErrorMsg.lineNum;
val linePos = ErrorMsg.linePos;
val commentNest = ref 0;
fun eof () =
let
val pos = hd(!linePos)
in
Tokens.toEOF (pos, !lineNum)
end;
%%
%s INITIAL COMMENT;
alpha = [a-zA-Z];
alnum = [a-zA-Z0-9];
digit = [0-9];
ws = [\ \t];
%%
\n => (lineNum := !lineNum + 1; linePos := yypos :: !linePos; continue ());
{ws}+ => (continue ());
<INITIAL>"while" => (Tokens.toTOKEN (Tokens.WHILE, yypos, !lineNum, yytext));
<INITIAL>"for" => (Tokens.toTOKEN (Tokens.FOR, yypos, !lineNum, yytext));
<INITIAL>"to" => (Tokens.toTOKEN (Tokens.TO, yypos, !lineNum, yytext));
<INITIAL>"break" => (Tokens.toTOKEN (Tokens.BREAK, yypos, !lineNum, yytext));
<INITIAL>"let" => (Tokens.toTOKEN (Tokens.LET, yypos, !lineNum, yytext));
<INITIAL>"in" => (Tokens.toTOKEN (Tokens.IN, yypos, !lineNum, yytext));
<INITIAL>"end" => (Tokens.toTOKEN (Tokens.END, yypos, !lineNum, yytext));
<INITIAL>"function" => (Tokens.toTOKEN (Tokens.FUNCTION, yypos, !lineNum, yytext));
<INITIAL>"var" => (Tokens.toTOKEN (Tokens.VAR, yypos, !lineNum, yytext));
<INITIAL>"type" => (Tokens.toTOKEN (Tokens.TYPE, yypos, !lineNum, yytext));
<INITIAL>"array" => (Tokens.toTOKEN (Tokens.ARRAY, yypos, !lineNum, yytext));
<INITIAL>"if" => (Tokens.toTOKEN (Tokens.IF, yypos, !lineNum, yytext));
<INITIAL>"then" => (Tokens.toTOKEN (Tokens.THEN, yypos, !lineNum, yytext));
<INITIAL>"else" => (Tokens.toTOKEN (Tokens.ELSE, yypos, !lineNum, yytext));
<INITIAL>"do" => (Tokens.toTOKEN (Tokens.DO, yypos, !lineNum, yytext));
<INITIAL>"of" => (Tokens.toTOKEN (Tokens.OF, yypos, !lineNum, yytext));
<INITIAL>"nil" => (Tokens.toTOKEN (Tokens.NIL, yypos, !lineNum, yytext));
<INITIAL>"," => (Tokens.toTOKEN (Tokens.COMMA, yypos, !lineNum, yytext));
<INITIAL>":" => (Tokens.toTOKEN (Tokens.COLON, yypos, !lineNum, yytext));
<INITIAL>";" => (Tokens.toTOKEN (Tokens.SEMICOLON, yypos, !lineNum, yytext));
<INITIAL>"(" => (Tokens.toTOKEN (Tokens.LPAREN, yypos, !lineNum, yytext));
<INITIAL>")" => (Tokens.toTOKEN (Tokens.RPAREN, yypos, !lineNum, yytext));
<INITIAL>"[" => (Tokens.toTOKEN (Tokens.LBRACKET, yypos, !lineNum, yytext));
<INITIAL>"]" => (Tokens.toTOKEN (Tokens.RBRACKET, yypos, !lineNum, yytext));
<INITIAL>"{" => (Tokens.toTOKEN (Tokens.LBRACE, yypos, !lineNum, yytext));
<INITIAL>"}" => (Tokens.toTOKEN (Tokens.RBRACE, yypos, !lineNum, yytext));
<INITIAL>"." => (Tokens.toTOKEN (Tokens.DOT, yypos, !lineNum, yytext));
<INITIAL>"+" => (Tokens.toTOKEN (Tokens.PLUS, yypos, !lineNum, yytext));
<INITIAL>"-" => (Tokens.toTOKEN (Tokens.MINUS, yypos, !lineNum, yytext));
<INITIAL>"*" => (Tokens.toTOKEN (Tokens.TIMES, yypos, !lineNum, yytext));
<INITIAL>"/" => (Tokens.toTOKEN (Tokens.DIV, yypos, !lineNum, yytext));
<INITIAL>"=" => (Tokens.toTOKEN (Tokens.EQUAL, yypos, !lineNum, yytext));
<INITIAL>"<>" => (Tokens.toTOKEN (Tokens.NOTEQUAL, yypos, !lineNum, yytext));
<INITIAL>"<" => (Tokens.toTOKEN (Tokens.LESS, yypos, !lineNum, yytext));
<INITIAL>"<=" => (Tokens.toTOKEN (Tokens.LESSEQUAL, yypos, !lineNum, yytext));
<INITIAL>">" => (Tokens.toTOKEN (Tokens.GREATER, yypos, !lineNum, yytext));
<INITIAL>">=" => (Tokens.toTOKEN (Tokens.GREATEREQUAL, yypos, !lineNum, yytext));
<INITIAL>"&" => (Tokens.toTOKEN (Tokens.AND, yypos, !lineNum, yytext));
<INITIAL>"|" => (Tokens.toTOKEN (Tokens.OR, yypos, !lineNum, yytext));
<INITIAL>":=" => (Tokens.toTOKEN (Tokens.COLONEQUAL, yypos, !lineNum, yytext));
<INITIAL>{alpha}{alnum}* => (Tokens.toTOKEN (Tokens.ID, yypos, !lineNum, yytext));
<INITIAL>{digit}+ => (Tokens.toINT (yypos, !lineNum, yytext));
<INITIAL>\".+\" => (Tokens.toSTR (yypos, !lineNum, yytext));
<INITIAL>"/*" => (commentNest := !commentNest + 1; if !commentNest = 1 then (YYBEGIN COMMENT) else (); continue ());
<COMMENT>"*/" => (commentNest := !commentNest - 1; if !commentNest = 0 then (YYBEGIN INITIAL) else (); continue ());
<COMMENT>. => (continue ());
. => (ErrorMsg.error yypos ("illegal character " ^ yytext); continue ());driver.sml若干修正
structure Parse =
struct
fun parse filename =
let val file = TextIO.openIn filename
fun get _ = TextIO.input file
val lexer = Mlex.makeLexer get
fun do_it() =
let
val t = lexer();
val tokenType = Tokens.getTokenType t;
in
print (Tokens.getText t);
print "\n";
case tokenType of Tokens.EOF => ()
| _ => do_it ()
end
in do_it();
TextIO.closeIn file
end
endこんなところか。lexの使い方の練習なので時間をかけてもしょうがない。tokenの定義はもっとうまいやり方があると思うが、どうせyaccが定義してくれるのだろうからその結果を見よう。明日からはchapter 3.