
環境構築はいつも面倒だ#01: VMWare版Teradataのセットアップ

VMWare Player上で動くTeradataデータベースをWindows環境にセットアップした際のメモを記します。
(2023.8.26: 17.20の設定時のメモに基づき、いくつか更新)
必要なソフトウェアや環境
Windows10のパソコン:
4GB分のメモリーを使うので、他も動くことを考えると最低8GB程度のメモリー。あと昔の思い出でHDDでVMWareを起動するとやたらと時間がかかった記憶があるのでSSDが良いかと。Windows11は試してないけど多分同じじゃないかなと思います。VMWare版Teradataの仮想イメージ
以下のサイトからダウンロード可能(評価版のため無償、会員登録が必要)。中にはSUSE Linuxが動いていて、そのうえでTeradataが動く。記載時点でのバージョンは17.20、以下の2つがあれば良いです。Vantage Express 17.20 (VantageExpress17.20_Sles12_20230220064202.7z)
Guide: Vantage Express on VMware [pdf]
Teradata Studio
Teradataに対してSQLアクセスするためのクライアントツール。ホストOSからアクセスするのに使います。同じく会員登録が必要です。最新はTeradataStudio__win64_x86.17.20.00.04.zipとあります。インストレーションガイドとユーザーガイドもあれば何かあった際に参照できるので便利です。
7Zip
上述の仮想イメージを解凍するために必要。64ビット x64を選択。
VMWare Workstation Player
記載時点で最新版は17.0.2。VMWareの仮想イメージを動かします。
JRE: Java Runtime Environment
Teradata Studioを動かすのに使います。Azul版のJavaを使ってみました。上述のTeradata Studioページにおける指定では、JavaのJDKもしくはJRE、バージョンは11もしくは17と指定がある。JDKにJREの機能がすべて含まれているのでどちらかでよい。11と17では17のほうが新しい。ということで17の必要最小限なJREを選択しました。
https://cdn.azul.com/zulu/bin/zulu17.36.17-ca-jre17.0.4.1-win_x64.msi
RLogin
これは以降で必須ではないですが、何らかのSFTP/SSHツールがあった方が便利です。以下から「Windows 7以降、実行プログラム(64bit) rlogin_x64.zip」を選択。VMWare内のゲストOSにリモートアクセスしたりファイルのやり取りをするのに使います。
退屈を凌ぐための音楽
あまり刺激的な作業ではないので何か音楽でも聴きながらが良いかと。例えば以下。
インストール作業
7zip、VMWare Workstation Player、JRE
ダウンロードしてきたファイルを実行して後は道なりに進めば完了です。JREのインストール先フォルダは後ほどTeradata Studioのインストール時に聞かれるのでパスを控えておきましょう。Windowsだと通常
C:\Program Files\Zulu\zulu-17-jre\
になります。
VMWare版Teradataの仮想イメージ
7zipにて好きなところに解凍。VMWare Playerを起動し、[仮想マシンを開く]から解凍した先にある.vmxファイルを指定します。最初は起動せずに[仮想マシン設定の編集]から、メモリー設定を4GB(お手持ちの環境に余裕があるならもっと大きくしても構いません)、ネットワークアダプターの設定をNATに変えた上で起動します。
起動するとOS自体がまず起動し、コマンドラインが流れ、しばらくするとログイン/パスワードを聞かれるのでroot/rootでログインします。あっち向いている女性が壁紙の画面が表示されたらOSは起動してます。

Teradataのサービスは自動で起動します。Gnome Terminalから以下で起動状態を確認できます。

pdestate -a以下のメッセージがでれば起動済。違ったらしばらく待ってもう一度。
PDE state is RUN/STARTED. ..以下にて稼働確認。そのままGnome Terminal内でTeradataにログインします。bteqはBasic Teradata Queryの略で、コマンドラインからTeradataを利用するツールです。
bteq続いてログイン(以下のIPアドレスはゲストOS内の内部アドレス)
.logon 127.0.0.1/dbcパスワードを聞かれる
dbcこれでログインできたのでシステムテーブルにselect文を投げてみる(*はshift+8で)

select * from dbc.dbcinfo;3行の結果を返してくれれば動いているはず。以下にてbteqを終了。Linuxに戻ります。
.quit続いてホストOS側からアクセスするためのIPアドレスを確認します。
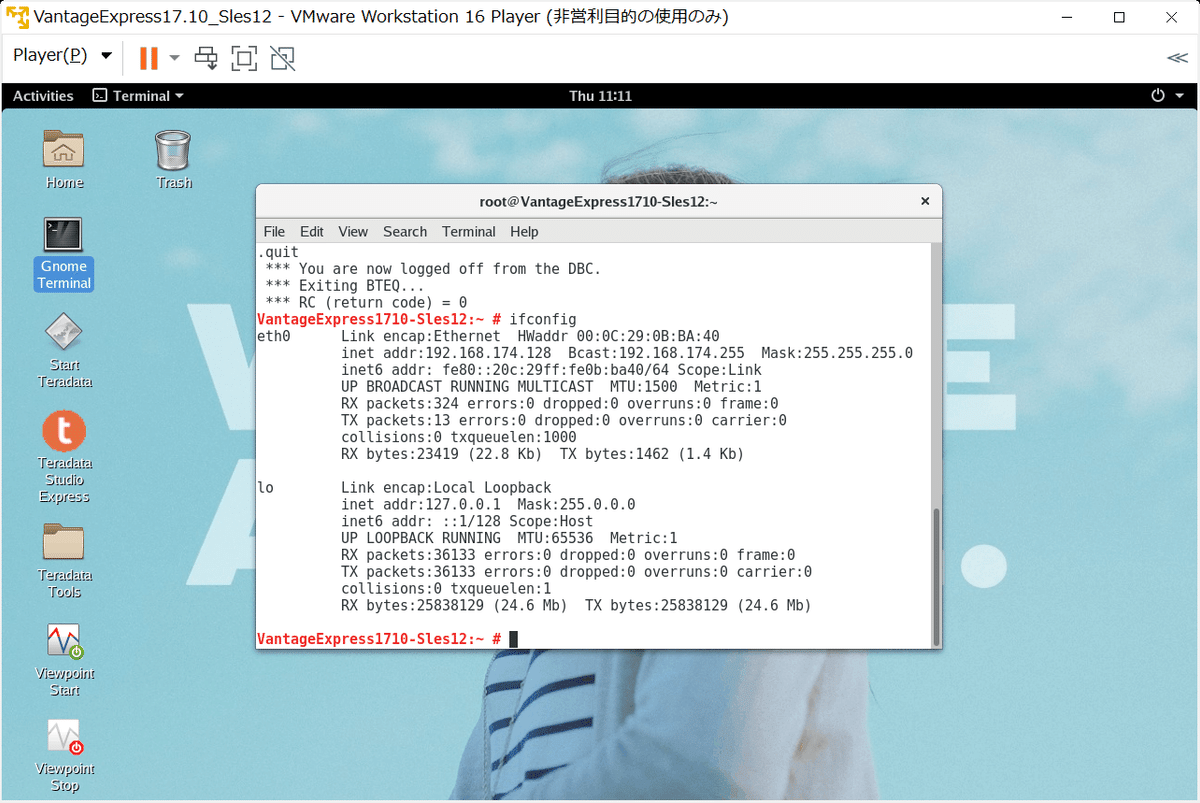
ifconfigeth0,inet addrのIPアドレスを控えておきましょう。スクリーンショットでは192.168.174.128となっている部分です。
これをのちのちTeradata StudioやRLoginのアクセスにて用います。
Teradata Studioのインストール
ダウンロードしたファイルを解凍し、中にあるインストールファイルを実行します。記載時のファイル名は以下。
Teradata Studio nt-x8664.msi
あとは道なりに。JREのパスを自動で見つけてもらえなかったら上述のパスをセットします。インストールが完了したら起動し、ウェルカムスクリーンみたいなのが出るので閉じ、画面右上にあるクエリー開発(Query Development)をクリックすると以下のような構成の画面が現れます。
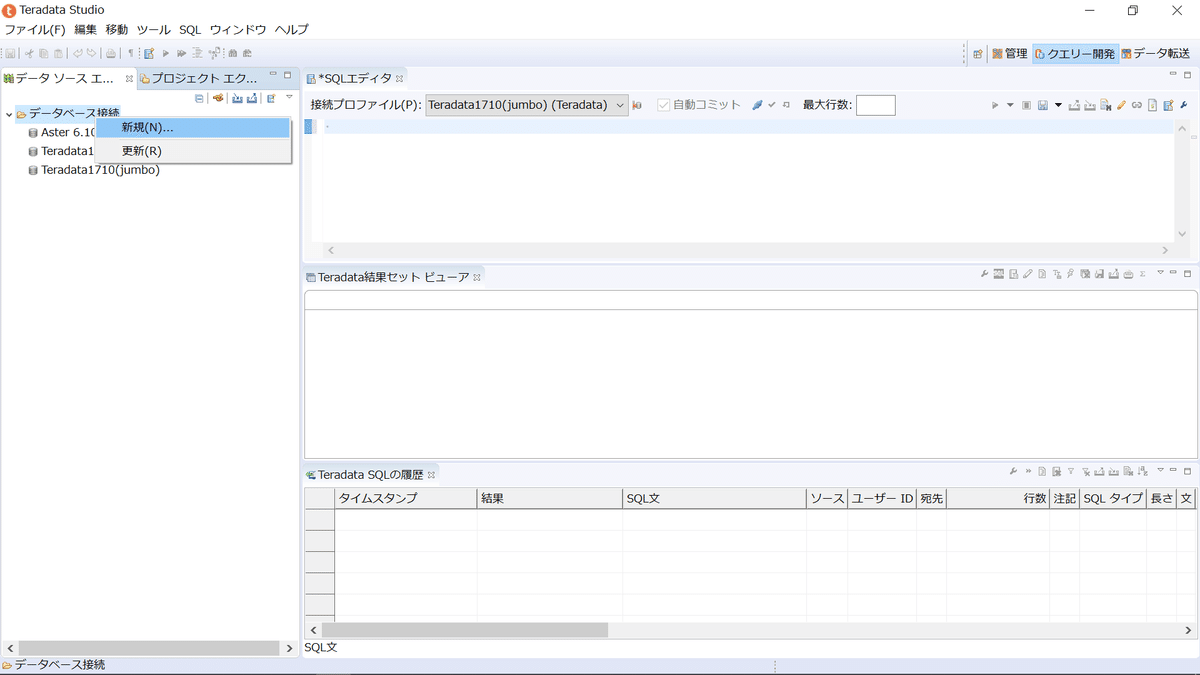
左側がデータベースへの接続をセットアップする部分、画像ではすでに作成済みですが接続プロファイル(ユーザー/パスワード/接続先)を作成、管理しています。真ん中から右側の上部を占めている部分がクエリーを書くところ(SQLエディタ)、真ん中がクエリー結果が表示されるところ、下側が実行ログの履歴表示部分です。
まずは接続プロファイルを作成します。利用開始時点での管理者権限はユーザー/パスワードがdbcで、接続先は先ほど確認したIPアドレスです。左側のフォルダアイコン[データベース接続]を右クリックし、[新規] > [Teradata] > 好きな名前を入力 > [次へ]

データベースサーバー名、ユーザー名、パスワード、データベースに以下をそれぞれ入力します。
データベースサーバー名: 先ほど控えておいたIPアドレス
ユーザー名: dbc
パスワード: dbc
データベース: dbc

[パスワードを保存]は、個人で使う分にはチェックを入れておいてよいかと。一旦保存すればアイコンをダブルクリックで接続できるので楽です。下側にある[接続テスト]をクリックすればpingを投げてくれて、問題なければその旨返ってきます。これで管理者dbcの接続プロファイル作成が完了です。画面左側にバケツのアイコンが出来上がり、こいつをダブルクリックすれば接続状態になります。画面真ん中から右側上部を占めているSQLエディタで接続プロファイルを指定し、SQLを書き込み、画面上部の矢印を実行すればSQLがTeradataに対して投げられます。エディタ内の一部分だけ実行したい場合は範囲指定してハイライトしたうえで、右クリックから[Execute Selected Text]で実行されますAlter+Xを押すと実行されます。結果のデータがある場合は真ん中の結果セットビューアに、結果データがある場合もない場合も、SQLに誤りなどがありエラーになる場合も、1行ずつログが下のSQLの履歴にたまっていきます。
(17.20ではバグがあるようでAlt+Xは動かなかった)

このdbcユーザーをそのまま使っても良いのですが、新たなユーザーを作る場合はdbcユーザーで新規ユーザーを作成します。例えば以下のような感じでユーザーを作成します。ユーザーはjumbo、パスワードはmambo、与えるデータ領域のサイズに約13GB割り当てています。
create user jumbo from dbc as password=mambo perm=13000000000;作成したらjumboユーザーとして新たに接続プロファイルを作成し(手順は上述の通り)、そちらからアクセスしましょう。試しにテーブル作成とデータの挿入、そこへのアクセスをしてみます。まずはテーブルの作成。
create multiset table jumbo.test (
c1 integer,
c2 varchar(10) character set unicode,
c3 integer
) primary index (c1)
;気にしなければならない点は2つです。まず、文字型のデータで日本語を入れたいときには上述のようにunicodeを指定します。デフォルトはlatinのため、ダブルバイトデータを挿入できません。次に、primary indexにはなるべく値がばらけるような、そして顧客番号とか製造番号、取引番号のようなキーとなるような列を指定します。列は複数指定しても構いません。なぜかというとTeradataはここで指定した列を基準に、内部的にデータを分散させるためです。これが例えば性別や01フラグのような2値しかとりえないようなデータだとデータ配置が偏ってしまい、ディスク利用上よろしくないのと、検索時の性能にも影響を与えてしまいます。逆に例えば顧客番号で分散させれば、多くの場合顧客番号はユニークでもかなりの数になると思うのでばらけさせることができ、なおかつ同じ顧客のデータは同じ場所に(簡単に言うと近くに)配置されるため、顧客ごとの集計を行う際にデータを色々なところからかき集める手間が省け、性能を最大限生かせます。
イメージとしては並列データベースのなかに100人位の小人(仮想プロセス)がいて、それぞれが担当データを持っていることを想像いただくとわかりやすいです。性別で分散させると100人のうち2人にデータが集中し、他の98人は暇してる状態です。300顧客のデータを基準に分散させれば小人1人あたり3顧客、1顧客10件の取引があれば30件ずつで、顧客ごとの取引集計をする際にほかの小人とデータをやり取りする必要がなくなります。
あと確か日付型はprimary indexに指定できなかった記憶があります。multisetについては気になった方は調べてください。何も考えずに使いたい人はそのまま呪文だと思ってもらえばよいです。
続いてデータの挿入。数値型以外はシングルクォーテーションでくくります。もちろん数値型もくくって構いません。くくっていない3行目はエラーとなるはずです。2行目のように列がすべて埋まっている場合は列名を省略できます。また値がない場合はnullでセットされます。
insert into jumbo.test (c1,c2,c3) values ('6','あいう','8');
insert into jumbo.test values ('5',,'8');
insert into jumbo.test (c1,c2,c3) values (4,えお,8);以下にて挿入したデータの確認。
select * from jumbo.test;最後にファイルのデータをテーブルにロードします。数行のデータであれば上述のようにinsert文を書いてもよいですが、大きいデータはファイルから直接流し込めないと面倒です。まずは以下のような内容を記載したファイルをtest.txtとしてUTF8にて好きな場所に保存します。拡張子は.txtですがカンマ区切りのcsvファイルです。
c1,c2,c3
1,'かきくけこ',8
2,'さしすせそ',9
3,'たちぬねの',10次にTeradata Studioで左側の接続プロファイルを展開していき、ロード対象のテーブルであるjumbo内のtestを右クリック > [データ] > [データのロード]を指定します。

パースペクティブを切り替えますか?みたいなメッセージが出るので[はい]、データ転送ウィザードが表示されたら、ソースタイプを[外部ファイル]に切り替えます。

[起動]をクリックすると以下のような画面になるのでファイルや項目を指定します。気にしなければならないのは列ヘダーがあるかどうか、区切り文字に何を使っているか、文字型データのクオーテーション文字、改行コード、ファイルのエンコーディングです。設定し終えたら[終了]をクリックするとロードが始まります。
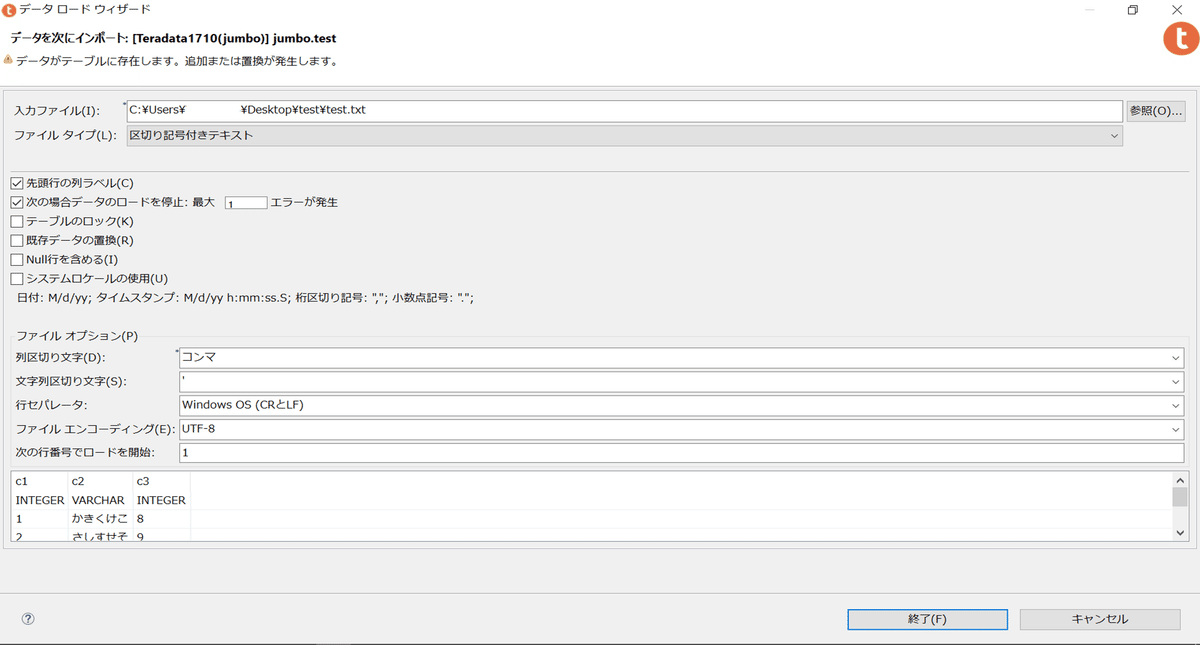
以下画面の真ん中部分で転送進行状況が動き、完了すると下側の転送履歴ビュー内ステータスに完了とロギングされます。失敗した場合は設定かデータに何かおかしい部分があるので確認が必要です。
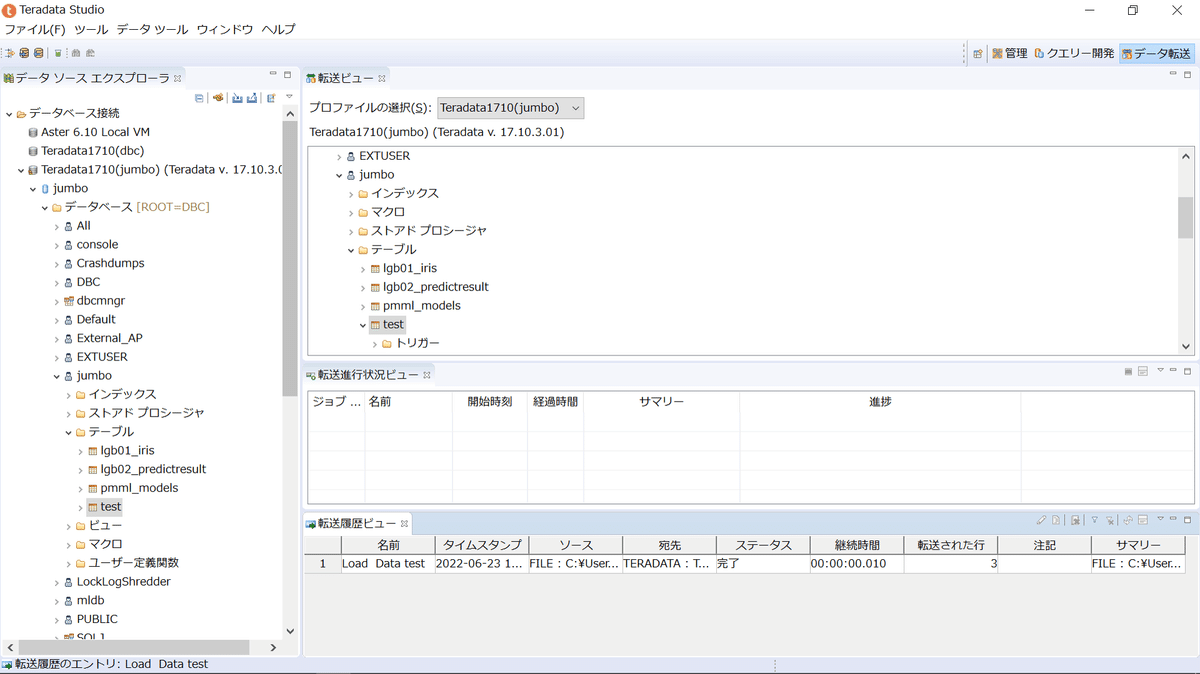
完了後クエリー開発に戻り、先ほどと同じ以下のSQLを実行し、上述の3行が追加されているのを確認します。
select * from jumbo.test;不要になったテーブルを削除します。
drop table jumbo.test;これにてセットアップと最低限の操作ウォークスルーは完了です。その他の利用や設定、例えばクエリー結果のExcel等へのエクスポートなんかはユーザーガイドを参照ください。
忘備で好みの設定を記載:
全角および半角スペース、タブ、改行を見えるようにする設定:
Windows > Preferences > Editors > Text Editors > Show whitespace characters結果セットをCtrl+Cコピーする際に列名も一緒にコピーする設定:
Windows > Preferences > Teradata Datatools > Result Set Viewwer > Copy Options > Copy Include Column Headers
RLoginの設定
最後にSFTP/SSHのツールを紹介しておきます。ファイルをLinux側に置きたい場合、またホストOSからLinuxを操作したい場合にはRLoginが便利です。もちろん他のSFTP/SSHツールでも良いのですが、何か1つ使えるものをご紹介しておきます。インストールは不要で、ダウンロードしたzipファイルを解凍すればすぐ使えます。解凍して出現するRLogin.exeを実行し、[ファイル] > [サーバーに接続] > [新規]で以下のような画面がでるので、以下の設定をします。
エントリー: 先ほど控えておいたIPアドレス
ホスト名: 先ほど控えておいたIPアドレス
ログインユーザー名: root
パスワード: root

以上にて接続プロファイルの作成は完了です。次回以降もこのプロファイルを利用してログインできます。
ログインすると若干見てくれは違うかもしれませんが、以下のような画面が表示されます。あとはLinuxコマンドで操作可能です。

ファイル転送は画面上部のファイルをスイングさせているアイコンをクリックすると、SFTPの画面が起動します。ホストOS側のディレクトリが左側に配置され、転送先のLinux上のディレクトリが右側に配置されています。多分最初に開くとrootの下が開くと思うのでそのままそこにファイルをドラッグ&ドロップすればファイル転送は完了です。
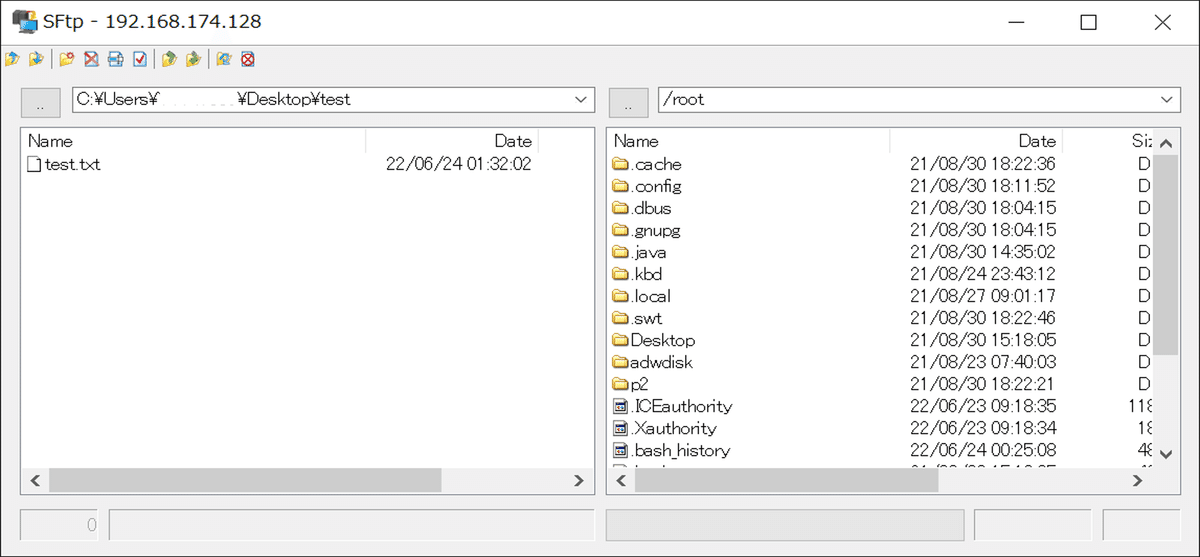
以上です。最後にVMWare Playerですが、×ボタンで終了する際にサスペンドで終了でも問題ありません。再度起動するときにはTeradataのサービスが立ち上がったままウェイクアップします。
///