
SQL分析データ準備と基礎統計#20:可視化

ここまでで紹介してきた大量データに対する基礎統計結果の把握に用いる可視化手法について以下に整理します。ケースによってさまざまな可視化手法が選択されますが、基本的なものは以下の7つ+に集約されるかと思います。最後のネットワーク図の一部、サンキー図に関しては基礎統計というよりも分析結果の可視化になりますが、使うことが多いのであわせて記載しておきます。
横棒グラフ:
- 質的変数で比較的バリエーションが少ない場合
- 量的変数のカット
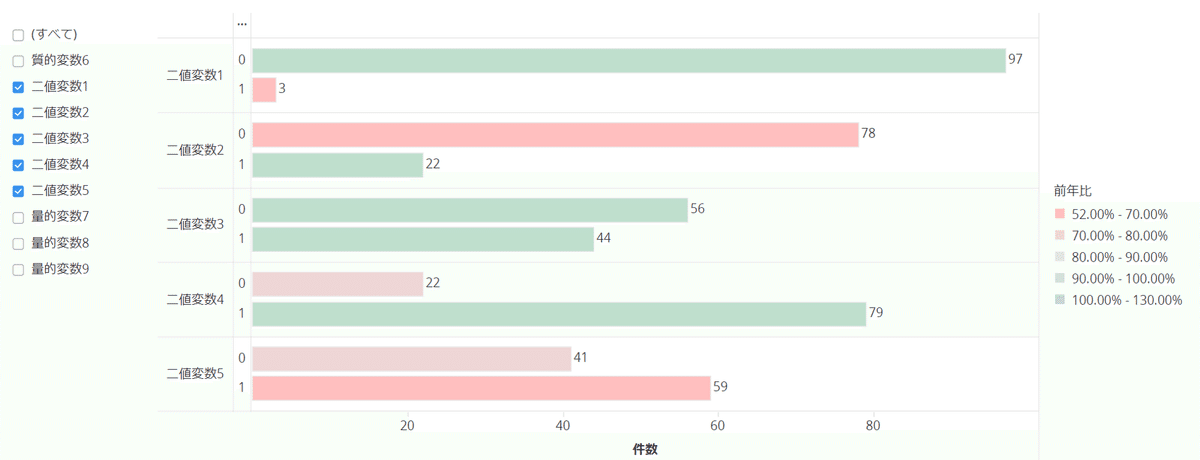

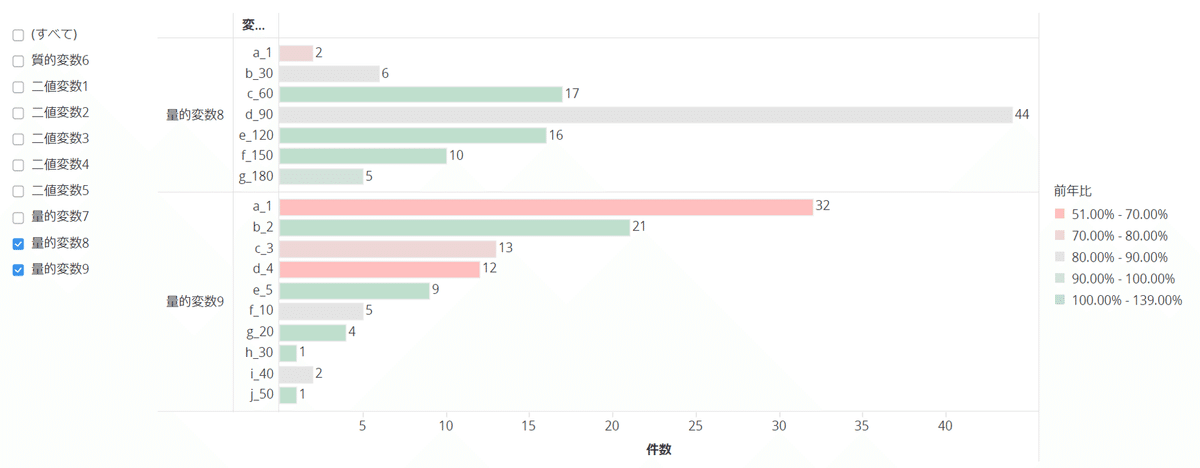

折線グラフ:
- 量的変数のカット、特に群比較を行いたいとき、構成比に変換して件数の偏りを調整して用いる
- 時系列データ


ヒートマップ:
- 質的変数で比較的バリエーションが多い場合
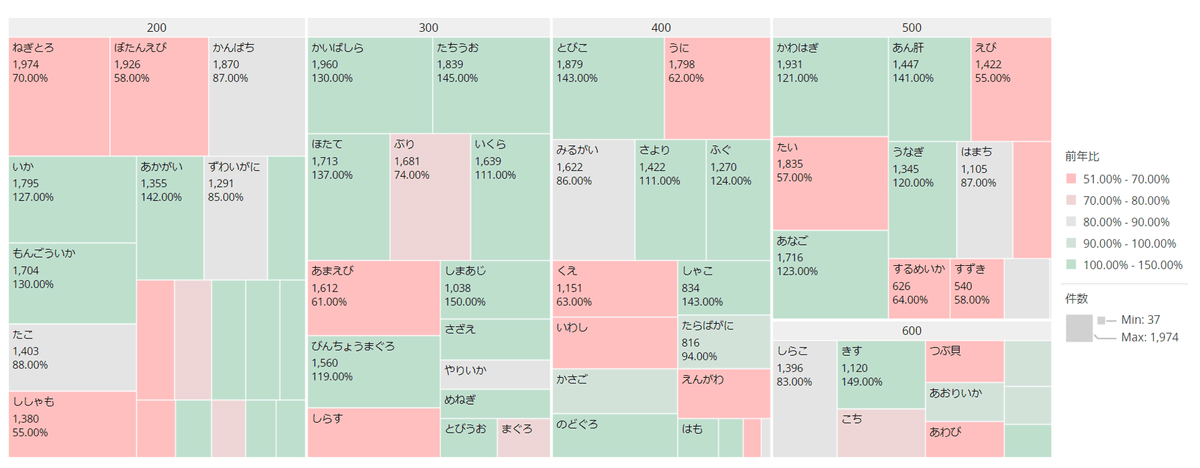
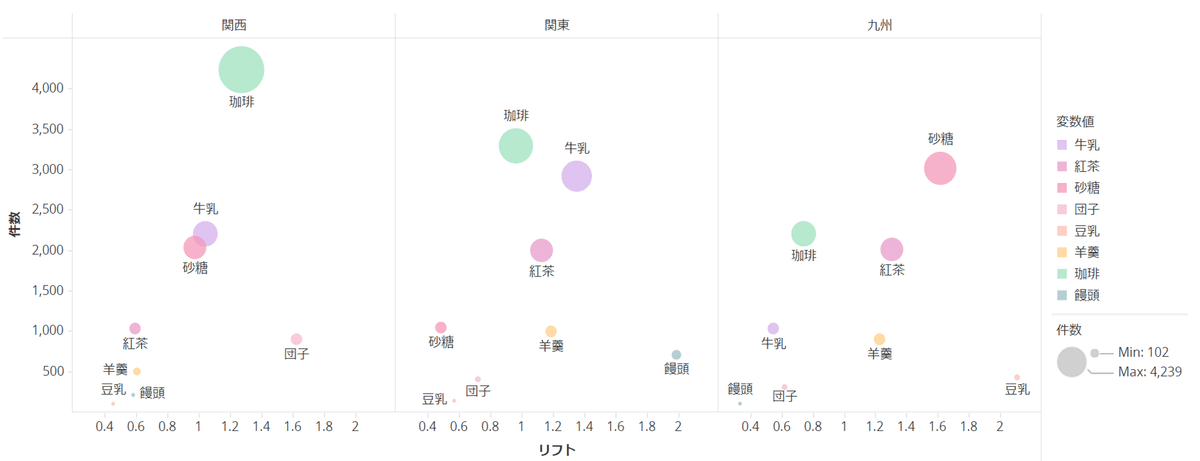
散布図:
- リフト値+件数もしくは構成比の2軸把握をする場合
クロス表:
- 相関係数における総当たり表現
- 変数同士の関係を見る(簡易的な散布図として)

ネットワーク図:
- グラフ/関連性のような組み合わせデータ
- 相関係数における一部の強い組み合わせのみ表現

サンキー図:
- 経路分析結果

添付したグラフ画像はサンプルとしてMicrostrategy Workstationで作成しました。TableauやRのggplot2などでも同様の可視化はできると思います。
大量データを分析用に準備し、基礎統計を取るときの鉄則
他の代表的な可視化手法としては、箱ひげ図、2変数の散布図が挙げられます。もちろんそれらの可視化も有用ですが、大量データをローカルのツールにデータを食わせて箱ひげ図、散布図を作成するのは現実的ではないため、割愛しました。
統計量は箱ひげ図を使うまでもなく表のまま見ればよいですし、例えば平均値等適時必要な値は量的変数のカットに追記すれば良いと思います。散布図は集約済のクロス表で代替したほうが、データ量が少なくて済みますし、サンプリングによって外れ値を見逃してしまう心配もありません。
もちろん元のデータ件数とローカル環境のリソース、与えられた時間によっては、そのままのデータをダウンロードしてきて可視化しても構いません。例えば数百行から数千行であれば手元のパソコンでも無理なく扱えるでしょう。ですが、例えば数億行の明細データ、数百万行の変数表を前提とした場合、データベース内部でデータ準備と基礎統計を実施し、その結果として十分に小さくなったデータを最後にダウンロードして可視化する方が効率的です。
///