
来店購入サイクルと、休眠顧客の定義を考える

大した話ではないのですが、割とよく出くわす話なのでまとめておきます。オンラインや物理店舗を問わない物販の来店、スマホアプリの利用、Webサイトの訪問において、リピートと来店来訪サイクルを把握する話がよく出てきます。ある顧客が一度来店して、次に来店するまでの期間を計測して出てくる、未来店・未訪問の期間です。これを顧客のリピートサイクルとして捉える場合もありますし、次の来店はいつになるか未知であるため、RFMにおけるRecencyの指標としても利用されます。そしてこの両方のデータを用いて、顧客が休眠したのかどうかを判断する際にも利用できます。ここではこの休眠判断についての基礎理解用のデータ整理について触れていきます。
ある種のサービスは、明確な解約がなく、それが休眠なのか、次の利用までの無風潜伏期間なのか、あいまいでわからない場合があります。無料アプリの利用、ポイントカードや会員プログラムなどがそれです。反対に、例えばサブスクリプションサービスであれば月額などで利用料金が発生するため、支払いがなくなれば、もしくは解約の申し込みがあればそれは解約で明確です。また一定期間利用がなかったら解約になるといったルールがある場合も明確でしょう。でも前者のようなケースの場合、顧客はどのくらいの期間利用しなかったらもう戻ってこないのか、つまり休眠してしまったのかを判断するのは難しいです。
もちろん顧客の利用サイクルはそれぞれに異なります。しかしながら全体として、このくらいの期間利用しなかったらもう戻ってこない、というのをある程度定量化しようというのが以降での試みです。
アプローチ
顧客があるタイミングで来店し、そして次1ヶ月後にまた来店したとします。そして現在に至るまで1ヶ月間来店をしていないとしましょう。そうすると、1回目と2回目の来店の間隔は1ヶ月、2回目の来店から現在までの間隔はも1ヶ月です。ここで我々は、1ヶ月の間隔が空いたとき、顧客が「帰還」するというサンプルを1つ、顧客が帰ってこない(まだ帰ってこないという意味で「未帰還」と名付けます)サンプルを1つ、合計2つのサンプルを1ヶ月の間隔ケースに関して手に入れたことになります。そしてこのとき帰還の確率も、未帰還の確率も同様に1/2=50%となります。今回の話は難しいものではなく、これを全顧客の全来店サイクルに適用してみよう、というアイデアです。
期待としては、再来店までの期間(以降では「未来店訪問期間(日数、月数)」とします)が短いケースでは帰還するケースが多く、長いケースでは返ってこないケースが多いのではという期待があります。また実際に遭遇したいくつかのケースではそうでした。言い換えると未来店訪問期間が短いと帰還確率が高く、長いと未帰還確率が高く(=期間確率が低く)なるという想定です。簡単に言うなら、「前回の来店から5日しか経過していない顧客はまた来てくれるかもしれないけど、5年経過した顧客は、..まあもう来ないよね」ということです。でもそうなると、「また来てくれるかも」と「まあもう来ないよね」の潮目がぶつかる部分はどこなんだろうという疑問が沸きます。仮にこの期待が正しいとすると、どこかのタイミングで帰還確率が未帰還確率に逆転されるはずで、それがいつなのかを探しに行きましょう、というのが今回の趣旨となります。
元データ
実際のデータを使って処理の流れを確認するのと、お試しをしてみましょう。以下のOnline Retail Datasetというデータを用います。オンラインショッピングの購買履歴データです。
中のデータは以下のような列構成になっています。いわゆるレシート明細のデータと考えたら良いかと思います。全部の列は使いませんが、いったんロードします。
Invoice: 注文番号、バスケットやレシートの括り
StockCode: 商品番号
Description: 商品名称
Quantity: 数量
InvoiceDate: 日付、実際には日付時刻
Price: 価格
Customer ID: 顧客番号
Country: 国
事前にTeradataにロードしやすいよう、3つのCSVファイルにまとめたので、こちらも置いておきます。
処理の流れと解説
まずはノードブックを。追って解説を加えます。最初の方はデータロードの処理と事前整理なので、再現するのでなければ無視していただいて大丈夫です。
以降でノートブック内のサブタイトルに応じた解説をします。
01.利用データ
事前整理が終わったテーブルがonlineretailです。データの並びはご覧の通りです。2009年から2011年にかけてのデータで、80万件弱、顧客数は6,000名弱のデータです。
02.顧客ごとの来店回数、ならぬ日数を集計する
来店日数をカウントします。例えば1日に複数回来店・利用する、百貨店のような複数フロアの施設で売り場ごとにお会計する(=1日に複数回取引が発生する)といった重複は除外するため、顧客番号と日付でgroup byして重複排除します。なので来店回数ではなく、来店日数としました。結果を見ると、6,000名弱のうち、1,460名は1日しか来店がなく、最大では508日来店した人が1名いることがわかります。前述のサンプルという観点では、1,460名からは未帰還のサンプルを1つづつ採取でき、508日来店した顧客からは期間のサンプルを507件、未帰還のサンプルを1件採取できたということになります。
03.未来店訪問月数
続いて未来店訪問期間を計算します。lead関数を用いて、顧客ごとに次の来店日付をずらして保持し、次の来店日付と今回の来店日付の引き算をして未来店訪問日数を計算しています。サンプルが少なそうなので雑ですが30で割って月数にしています。lead関数で次がない場合はnullにしていますが、nullの場合は次がない=未帰還なので未帰還に、それ以外は帰還のフラグにしています。そのほかの細かなやり口はSQL内のコメントをご覧ください。
なお、商品番号もgroup by列に含めて処理すれば商品ごとの利用インターバルを計算できます。言い換えると商品のリピートサイクルを理解できます。が、今回のテーマから脱線するので割愛します。
この結果をそのまま次のクエリーに派生させても良いですが、今回はいったんこの状態をテーブルに書いておきます。解説用にわかりやすくするため、無駄に途中の処理を列として出力していますがご容赦ください。
作成されたデータをみてみましょう。顧客番号18118に関してのデータを日付順で出してあります。こちらの顧客は30回来店しており、ほぼほぼ1ヶ月間隔であることがわかります。30件なので29件の帰還サンプルと1件の未帰還サンプルです。あとはこれを集計するだけ。
04.帰還未帰還と未来店訪問月数で集計
帰還フラグと、未来店訪問月数で集計したのがこちらです。期待通り未来店訪問月数が13か月目あたりで逆転している気もしますが、地べたを這っているので正確なところはわかりません。件数サンプルとしては、未来店月数が長くなるほど少なくなります。そして帰還と未帰還でも母数規模が異なることもわかります。

05.帰還確率を未帰還確率が逆転するのは何か月目か?
続いてこれを確率でみてみましょう。各月数の帰還+未帰還件数を確率分母として計算すると上下シンメのグラフとなり、交差部分からやはり13か月目に逆転したことがわかります。8か月目程度からサンプルが少なくなっていたため、若干数値が暴れる傾向がありますが、全体としては期待通りのデータです。これを見ると12か月未来店なら帰還(また来店してくれる)確率は80%弱なのが、13か月目なら30%強まで落ちることがわかります。結論としては、13か月来店がなければ、休眠とみなして良さそうです。
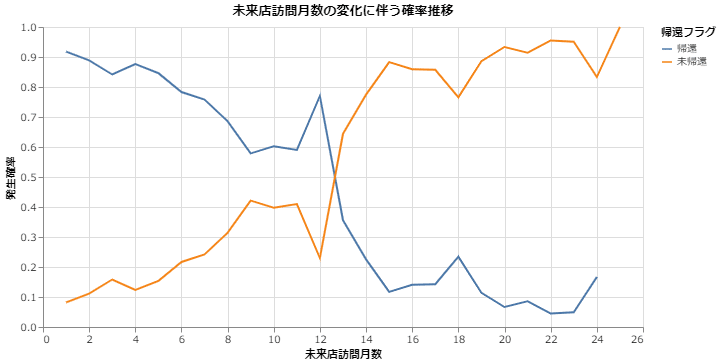
06.確率 vs. 確率、未来店訪問月数が長引くとどれだけ確率がリフトするか?
帰還確率を基準にしたとき、未帰還の確率がどの程度リフトしているかも見ました。結論としては同じなのですが、13か月目で未帰還確率が帰還確率の1.8倍、14か月目で3.4倍、以降も大差がついています。

以上です。すべてのケースでこのような傾向になるとは言い切れませんが、来店や来訪、利用といったサイクリックな動きと、そこから徐々に発生していく休眠脱落を考えると、このようなポイントを見つけ出せるケースも多いのではと思います。
///