
Netflixのデータを見る【Python】

こんにちは。みなさんNetflixを見ますか?私は毎日ドラマや映画、アニメのどれかを1つ観てます。
今回はそんなNetflixのデータを、Pythonを使って調べてみようと思います。
kaggleに『Netflix Original Films & IMDB Scores』があるので、これを使います。
Jupyter Notebookでファイルを開きます。
import pandas as pd
df = pd.read_csv("C:\\Users\\csv_file\\NetflixOriginals.csv", encoding='latin1')
df
584の作品がありますね。
このデータはNetflixで作られたオリジナルのみです。
まずはデータの整形をします。
最初にnullが含まれるか、確認します。
df.isnull().sum()
次に"Premiere"の列からdatetime型を作ります。
こうすることでdfを時系列で扱えるようにします。
df["date"] = pd.to_datetime(df["Premiere"])
df.head(5)
今度は"date"から"year"と"month"と"day"の列を作ります。
"day"は曜日の列となります。
df["year"] = df["date"].dt.year
df["month"] = df["date"].dt.month
df["day"] = df["date"].dt.strftime("%a")
df.head(5)
そして"date"の列をindexにセットして、indexを並び替えます。
df.set_index('date', inplace=True)
df.sort_index(inplace=True)
df.head(5)
最後に”Premiere”の列を削除して、整形は終わりです。
df.pop("Premiere")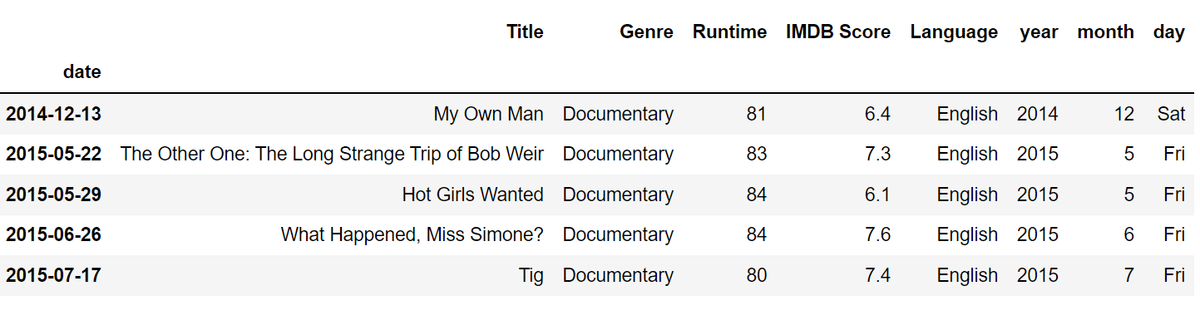
ここまでをまとめると。
df.isnull().sum()でnullの確認。
pd.to_datetime()で、"Premiere"の列からdatetime型を作る
dfに"year", "month", "day"の列を追加
df.set_index()で"date"の列をindexにセット
df.sort_index()でindexを並び替える
df.pop()で”Premiere”の列を削除
となります。
ちなみに、このデータは2014-12-13から2021-05-27までのデータです。

それではデータを見ていきましょう。
まずはIMDB ScoreのTop10から。
IMDbはInternet Movie Databaseの頭文字で、映画、ドラマ、ゲームの批評サイトです。
df.sort_values("IMDB Score",ascending=False).head(10)
David Attenborough: A Life on Our Planet Documentary 9.0
Emicida: AmarElo - It's All For Yesterday Documentary 8.6
Springsteen on Broadway One-man show 8.5
Winter on Fire: Ukraine's Fight for Freedom Documentary 8.4
Ben Platt: Live from Radio City Music Hall Concert Film 8.4
Taylor Swift: Reputation Stadium Tour Concert Film 8.4
Cuba and the Cameraman Documentary 8.3
Dancing with the Birds Documentary 8.3
Seaspiracy Documentary 8.2
The Three Deaths of Marisela Escobedo Documentary 8.2
一位は自然をテーマに扱った番組で9.0です。
ほとんどがドキュメンタリー番組で、ライブなんかも入ってますね。
真実に基づいた話は、それだけ面白いという事なんでしょうか。
では"Genre"の種類を見てみましょう。
df.value_counts("Genre").head(10)
ドキュメンタリーが多いですね。ドラマの倍以上あります。
Netflixはドキュメンタリー番組には、積極的なんでしょうか。
次にドラマ、コメディと続きます。
ドラマの中で評価が高いのを見ます。
df_drama = df[df["Genre"] == "Drama"]
df_drama.sort_values("IMDB Score",ascending=False).head(10)
Marriage Story 7.9
The Trial of the Chicago 7 7.8
Roma 7.7
The Two Popes 7.6
Yeh Ballet 7.6
I'm No Longer Here 7.3
Private Life 7.2
The Disciple 7.2
First They Killed My Father 7.2
Sometimes 7.2
ドラマの最高スコアは7.9で、あとは7点代ですね。
金曜日に公開されている数が多いのは、興味深いです。週末に見てもらう狙いがあるのでしょうか。
次はコメディーを評価順に見ます。
df_comedy = df[df["Genre"] == "Comedy"]
df_comedy.sort_values("IMDB Score",ascending=False).head(10)
The 40-Year-Old Version 7.2
Rose Island 7.0
Long Live Brij Mohan 6.8
Death to 2020 6.8
Just Another Christmas 6.7
The Incredible Jessica James 6.5
Chopsticks 6.5
Get the Goat 6.3
Porta dos Fundos: The Last Hangover 6.3
Have You Ever Seen Fireflies? 6.2
単純に数が少ないのもありますけど、全体的にスコアは低くなりました。
ただこのデータでも金曜日が多い傾向があります。
では実際に金曜日が多いのかを調べてみます。
df.value_counts("day")
df.value_counts("day", normalize=True)
金曜日がかなり多いです。公開された曜日の65%が金曜日で、14%が水曜日ですね。土曜日は、前日が金曜日ということもあって0.8%しかないです。
やはり、金曜日の公開は意図的だと言えますね。
グラフだとこうなります。
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
plt.tick_params(labelsize=15)
plt.rcParams['figure.figsize'] = (7 ,8)
df.value_counts("day").plot.bar().grid(axis='x')
次は各年の公開数を見ます。
df.value_counts("year", sort=False)
df.value_counts("year", sort=False).plot.bar().grid(axis='x')
年々増加していますね。2021年は5月までのデータなので、この調子だと200近い数字まで、上がることが予想できます。
各月の公開数を見ます。
df.value_counts("month", sort=False)
df.value_counts("month", sort=False).plot.bar(rot=0).grid(axis='x')
10月が何故か高いです。これも意図的な狙いがあっての事なんでしょうか。
最後に時間とスコアの関係を調べてみます。
fix, ax = plt.subplots()
ax.scatter(df["Runtime"], df["IMDB Score"])
plt.tick_params(labelsize=15)
ax.set_xlabel("minute", fontsize=15)
ax.set_ylabel("score", fontsize=15)
plt.show()
見たところ時間とスコアの関係はないと言えます。
5から8までのスコアが多く、全体的に100分前後に集中しているといった具合でしょうか。150分を超える作品はほとんどないです。
ひとつだけ200分越えがありますね。
スコアが7.8で『アイリッシュマン』でした。
まとめ
Netflixオリジナルは意外とドキュメンタリーが多く、評価が高い。
年々オリジナルの本数が増えている。
次はNetflixオリジナルのドラマシリーズのデータを見たいです。
もちろん直近のデータで。
以上です。
この記事が気に入ったらサポートをしてみませんか?