
R言語によるRaschモデル

RでRaschモデルによるテストデータの分析を行う場合の手順です。
準備として、データは以下の記事の方法で乱数で生成して"resp"というオブジェクトに格納したものを使うことにします。項目数は50問、人数は500人(item.n=50; person.n=500)でランダムに生成した0/1の回答データです。
RでRaschモデルを扱うライブラリは"eRm"です。これをロードしておきます。あわせて項目反応理論のライブラリ"ltm"も呼び出しておきます。
install.packages("eRm")
install.packages("ltm")
library(eRm); library(ltm)まず、eRmでRaschモデルの項目パラメータの推定と、個人スコアの推定を行います。
result.rasch=RM(resp,sum0=FALSE)
score.rasch=person.parameter(result.rasch)$thetapar1行目で項目パラメータの推定を行っています。sum0=FALSEとすると、1項目目のパラメータの推定値が0に固定されます。sum0=TRUEとすると、項目パラメータの和が0に制約されます。
2行目では個人別の能力値パラメータの推定を行っています。
下の図は、項目パラメータの推定の際に、sum0=FALSEとした場合(左の図)と、sum0=TRUEとした場合(右の図)の、個人別の能力値パラメータの分布を調べたものです。
左のヒストグラムの平均は1.42、右は0.05となっており、分布の位置が異なります。eRmでは、項目パラメータに対する制約の与え方が個人の能力値の分布に影響を与えるので、注意が必要です。

ltmパッケージにも、Raschモデルの項目パラメータを推定する機能があるので、eRmの場合と結果を比較してみます。
result.ltm=rasch(resp)横軸をeRmによる項目パラメータの推定値、縦軸をltmによる項目パラメターの推定値として50個の項目をプロットしたのが下の図です。結果は直線上に並んでいますが、右下がりになっており両者で符号が逆転していることがわかります。これはモデル上の項目パラメータの符号が両者で異なるためだと考えられます(ltmは結果の取り出し方によって想定するモデルが変化するので、その影響もあります。詳しくは以下の記事を参照)。
https://note.com/yoshinori_oki/n/n7a722c00aa34
また、横軸で値が1付近の項目は、縦軸の値が0.5あたりになっており、両者で値の水準(位置)が異なることもわかります。これは項目パラメータの推定時の制約がltmとeRmで異なっており、ltmの結果には全項目共通のaパラメータが存在することによるものだと思われます。

score.ltm=factor.scores(result.ltm,resp.patterns=resp)$score.dat$z1ltmでも能力特性値を推定してeRmの結果と比較してみます。下の図がその結果です。横軸がeRmによる推定結果、縦軸がltmによる推定結果です。
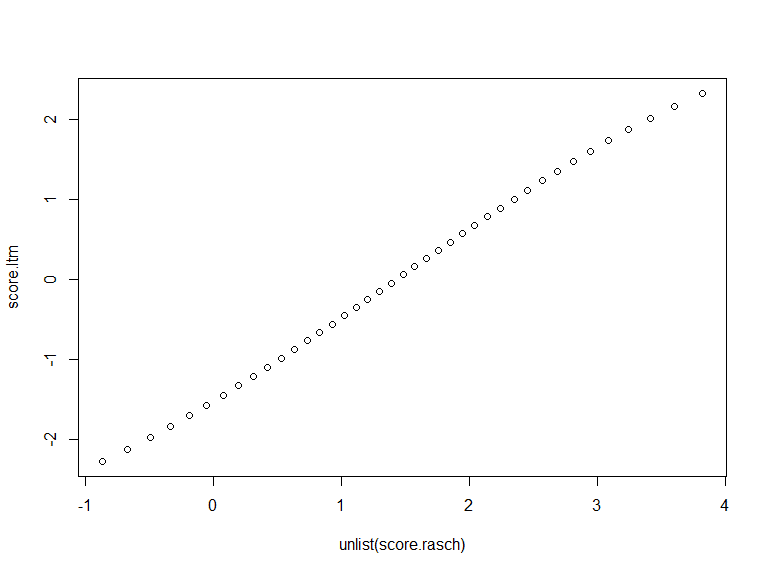
若干の歪みはありますが、両者の推定結果は非常に似た傾向をもっていることがわかります。だだし、eRmのほう(横軸)をみるとレンジが-1から4あたりであるのに対して、ltm(縦軸)では-2から2くらいになっており、値の幅と位置が異なります。

上の図は先ほどの散布図の縦軸に対応するltmによる能力特性値の推定値の分布です。平均は0.0、SDは0.9であり、ltmは(項目パラメータに制約を入れる代わりに)能力特性値の平均が0になるように制約が入っていることがわかります。
また、2パラメータ・ロジスティックモデルとは異なり全項目に共通ですが、ltmではRaschモデルでも項目パラメータとして"Dscrmn"という値が出力されます。これは能力特性値の分散に制約が入っていることに対応しているものだと思われます(能力特性値の分散に制約を入れるためにはaパラメータが必要)。
まとめると、Raschモデルの分析はeRmでもltmでも実行可能で、それぞれ結果の傾向はほぼ同じものですが、制約条件の取り扱いの関係で、値自体は異なったものが出力されるということになります。両者で並行して分析するような場合には、混乱しやすいので少し注意が必要だと思います。
この記事が、参考になれば幸いです。
この記事が気に入ったらサポートをしてみませんか?