
テストのDIF(特異項目機能)

通常、心理テストや学力テストでは、受検者のレベルが同じなら、国籍などの属性が異なっていたとしても同じスコアが出力されるべきだと考えられています。
一方で、一般的なフローでテストを開発した場合、いくつかの理由で上記の事柄が満たされない可能性が残るケースがあります。たとえば
■ 日本語の性格検査を英語に翻訳して実施したが,項目のニュアンスが微妙に変わってしまう
■ 同じ知能テストを英語圏の2カ国で実施したが,それぞれの国の基礎教育の内容の違いが問題の正誤に影響を与えてしまう
■ 性格検査において,ジェンダーに関する規範の影響で男女で回答の傾向に違いが生じる
受検者の属性によって、本来は同じレベルの受検者の回答に差がでる作用はDIF(Differential Item Functioning/特異項目機能)と呼ばれています。
このテーマが難しいのは、性別や国籍などの属性別にスコアや正解率を集計して比較した際になんらかの差があったとしても、それがDIFによるものなのか、グループ間の本来の水準の差によるものなのかが通常は区別できないところです。このため、DIFの影響のある問題項目をデータから発見するには様々な工夫が必要になってきます。
ここでは、比較的計算しやすく、手順もDIFの定義自体に沿っていてわかりやすい『分散分析によるDIF分析』について、そのイメージをまとめます(DIF分析の方法は、いくつか提案されており、併用するのが望ましいと言われています。興味のある方は是非書籍などを確認してください)。
分散分析によるDIF分析
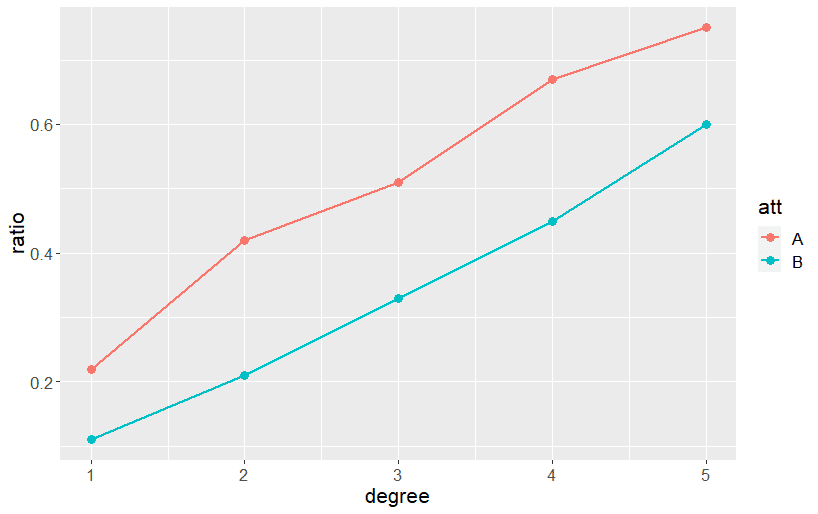
『分散分析によるDIF分析』では、テスト(もしくは心理尺度)を構成する各問題項目について下のようなグラフを作ります。
横軸は、テストのスコアを適当な区切り位置を設定して段階化したものです。縦軸は、この項目に対する各段階に所属する回答者の正解率です。
2つの線は属性を表してます。
手順をレシピ風にまとめると、次のようになります。
1)各受検者についてテストのスコアを計算する
2)段階化のための区切り位置を決める
3)各受検者のテストのスコアを段階に変換する
4)各段階に所属する受検者について、属性別に項目毎の
正解率(平均)を計算する
5)横軸を段階、縦軸を正解率として属性毎の値をグラフにする
横軸を段階に変換するのは、連続値のスコアのままだと、各スコアに所属する受検者の人数が小さくなって正解率が安定しないためです。
グラフの横軸は、スコアを段階化したものですが、仮にテストを構成する項目が十分に多く、DIFを有する項目が比較的少なかったとすると、段階は受検者のレベルを表していると見なすことができます。
DIF分析が難しいのは、属性による項目単位での正解率の差が、受検者のレベルがもともと属性間で異なることによるのか、それ以外の要因によるのか分離する必要があるためですが、この方法ではテスト全体のスコアを近似的に受検者のレベルだと見なして、段階毎に正解率を求めることで、レベルによる影響をコントロールします。
同じ段階≒(能力)レベル内で正解率を比較することで、各属性でレベルの分布が異なっていたとしても、正解率に対する属性の影響を議論できるようになるわけです(したがって、テストを構成する項目の大半にDIFの影響があると考えられる場合には、注意して利用する必要があります)。

上のグラフ(再掲)のように、属性Aと属性Bで各段階の正解率が大きく異なっている場合、この項目には何らかの理由でDIFが生じている可能性があると考えます。
DIFが存在しない場合には、下のグラフのように段階別の正解率は、どちらの属性でもほぼ同じになります。

もちろん『分散分析によるDIF分析』では、実際にはグラフを作成するだけではなく、分散分析を行って属性によって正解率が異なることを統計的に検定していくわけですが、『分散分析によるDIF分析』の考え方は概略上記のようなものです。グラフを検討するだけでも、かなり多くのことが把握できます。
DIF分析が使える場面は幅広いので、テストの分析手法の一つとして知っておくと役に立つ機会があると思います。
この記事が何かの参考になりましたら幸いです。
[参考]
田崎, 2008, 『社会科学のための文化比較の方法:等価性とDIF分析
普段、テスト理論とよばれる統計的な手法を応用した学力テストや心理尺度の開発、マーケティングデータの分析、社会人の方向けの統計の教育などに取り組んでいます。こちらのページに、統計やデータサイエンス、テストの開発についてよくいただくご質問に対する説明や、自分自身が疑問に感じた事柄を少しずつシェアしていきたいと思います。