
便利ライブラリ Pandas④ pivotとmelt

サンプルデータの準備
Pandasについての第4回目です。
今回は、データの可視化を見据えたデータ整形についてまとめています。以下のコードから、オオムギ生産量のデータをサンプルとして取得して使用します。
import pandas as pd
from vega_datasets import data
source = data.barley()sourceという変数にデータフレームが格納されています。中身を表示すると、120行 x 4列のデータフレームになっていることが分かります。
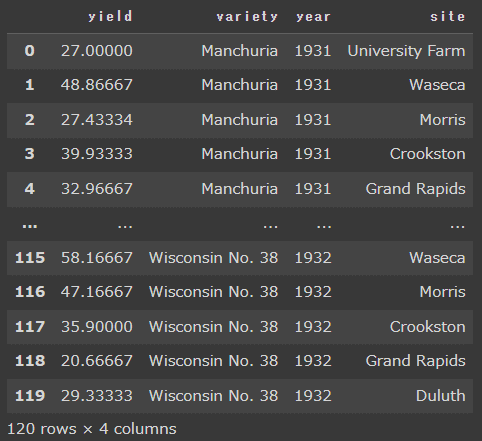
variety(品種)、year(年代)、site(産地)のカラムにどのようなデータが含まれているかunique()を使用して確認してみます。source['カラム名']で、そのカラムに含まれるデータが取得されます。unique()を使用することで、重複データを削除することが出来ます。
print(source['variety'].unique()) #品種
print(source['year'].unique()) #年
print(source['site'].unique()) #産地 品種:['Manchuria' 'Glabron' 'Svansota' 'Velvet' 'Trebi' 'No. 457' 'No. 462' 'Peatland' 'No. 475' 'Wisconsin No. 38']
年代:[1931 1932]
産地:['University Farm' 'Waseca' 'Morris' 'Crookston' 'Grand Rapids' 'Duluth']
以上のようなデータが含まれていることが分かります。
クロス集計 pivot_table()
生データのままだと分かりにくいので、クロス集計します。Excelで行うピボットテーブル作成と基本的には同じで、pivot_table()を用いてクロス集計する行(index)、列(columns)、値(values)と値の集計方法(aggfunc)を指示してあげるだけです。
source.pivot_table(index="variety",
columns="site",
values="yield",
aggfunc='sum'
)
実行すると、行名には品種、列名には産地が入り、1931年と1932年の生産量の合計値が表示されました。値の集計方法は合計以外にも指定することが出来ます。
sum: 合計
mean: 平均
median: 中央値
max: 最大値
min: 最小値
count: データの個数
また、indexにリストを渡すことで、より詳細な集計を行うことも出来ます。indexに品種に加え、年代も追加してみましょう。
source.pivot_table(index=["variety", "year"],
columns="site",
values="yield")
このようにクロス集計(=ワイドデータ形式)することで、データを分かりやすく加工することが出来ました。
melt()
Excelでもクロス集計→グラフ化という流れでデータを可視化することがよくあるので馴染みがあるかもしれませんが、クロス集計されたデータを生データのようなロングデータ形式に再構築する必要がある場合があります。そのような場合には、melt()を使用します。pivot_table()と逆のことをするのがmelt()です。
まずは、先ほどのpivot_tableをdfという変数に格納します。
df = source.pivot_table(index=["variety", "year"],
columns="site",
values="yield")meltするときに、どの変数(カラム)をキーにして再構築するか指定する必要があります。この時、indexになっているデータは指定できないので、reset_index()を用いてindexをリセットしておく必要があります。
df.reset_index(inplace=True)melt()は以下のように引数を指定します。
pd.melt(df, #対象のDataFrame
id_vars=None, #キーとして残すカラム
value_vars=None, #meltする変数(指定しなければ、id_vars以外のすべて)
var_name=None, #項目名
value_name='value' #値列のカラム名
)例として、品種と年代をキーとして再構築します。
df_melt = pd.melt(df,
id_vars=['variety', 'year'],
var_name='site',
value_name='yield',
)
df_melt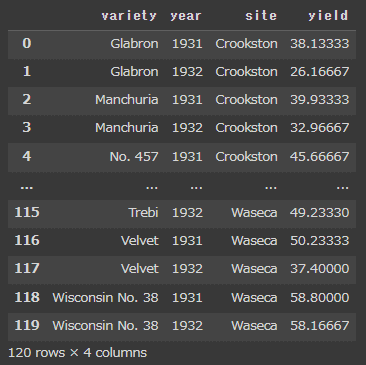
meltすることで、キーとして指定した「品種+年代」はそのまま残り、それらの項目に対し産地と生産量が再構築されたデータとなりました。クロス集計する前の生データと同じ120行 x 4列のデータに戻っています。

melt()は馴染みがなく分かりにくいですが、どの列をキーとして残すか(id_varsとするか)を意識するとよいかもしれません。
4回にわたりPandasについてまとめてみました。よく使うメソッドは入れたつもりですが、まだまだたくさんの機能が備わっています。Excelでできることは大抵できます(…と思います)。今後投稿する可視化や自動化などの機能を加えれば、Excel以上に役に立つツールとなります。今後の投稿もお楽しみに!