
Pandasの備忘録① resample()

Pandasは、最もよく使うライブラリの1つです。様々な機能があり覚えきれないので、自分用の備忘録としてまとめました。今回はresample()について。
resample()とは
resample()は、時系列データを月ごとや週ごとに集計するメソッドです。時系列データを扱うので、インデックスもしくは引数onで指定する列にDate型などの時系列データが入っている必要があります。
基本的な使い方は以下の通り。
DataFrame.resample(rule, on=None).sum()
rule: 集計する間隔を表す文字列(Y: 年、M: 月、W: 週、D: 日、Q: 四半期など)
on: 集計に使用する時系列データが入った列を指定。時系列データがindexになっている場合は省略可能。
closed: {‘right’, ‘left’}, default None leftにすると期間に開始日時を含め、rightにすると期間に終了日時を含めるようになる。上記のruleではW以外はデフォルトはleft。
label: {‘right’, ‘left’}, default None ラベルの指定。leftにすると開始日時をラベルに指定できる。closed同様に上記のruleではW以外はデフォルトはleft。
DataFrame.resample()の後にどのような値を返すか指定します。
sun(): 合計
mean(): 平均
median(): 中央値
count(): データ数
max()/min(): 最大値/最小値
first()/last(): 先頭の値/末尾の値
ohlc(): 始値Open、高値Hight、安値Low、終値Close
agg(): 引数に上記をリストとして渡すと、複数の集計結果が得られる
使用例
サンプルデータ
例として、以下の厚労省のHPからダウンロードできる新型コロナウイルス感染症情報(新規陽性者数の推移(日別))を使用します。得られたcsvファイルを作業ディレクトリに保存します。
分かりやすいように、東京と大阪のデータのみに絞ります。
df = pd.read_csv('newly_confirmed_cases_daily.csv')
df = df[['Date', 'Tokyo', 'Osaka']]
df['Date'] = pd.to_datetime(df['Date']) # Date列をDatetime型に変換
df.set_index('Date', inplace=True) # Date列をindexに設定
df.head()
元データには日ごとのデータが入っていることが分かります。
月ごと集計
月ごとの合計を集計します。
df1 = df.resample('M').sum()
df1.head()
月ごとの合計が集計できました。'M'で集計すると、indexは月末日になることに注意してください。ちなみに、label='left'としても前月の月末日となってしまいます…。
agg()を使用し、複数項目を一気に出力することも出来ます。
df2 = df.resample('M').agg(['count', 'mean', 'sum'])
df2.head()
東京、大阪それぞれに対し、個数、平均、合計の値が集計できました。
週ごと集計
今度は週ごとに集計します。rule='W'とすれば良いですが、labelとclosedはデフォルト設定ではrightとなっています。

df3 = df.resample('w',
label='right',
closed='right'
).sum()
df3.head()
デフォルト(上記コードでは明示的に記載しています)では、月~日曜日で集計され、最終日の日曜日がラベルとして使用されています。
df4 = df.resample('w',
label='left',
closed='left'
).sum()
df4.head()
labelとclosedをleftに変えると、日~月曜日で集計され、最初の日曜日がラベルとして使用されます。引数の設定の仕方によって、同じ'2020-01-19'のラベルでも集計範囲が異なるため注意してください。
df4 = df.resample('w-mon',
label='left',
closed='left'
).sum()
df4.head()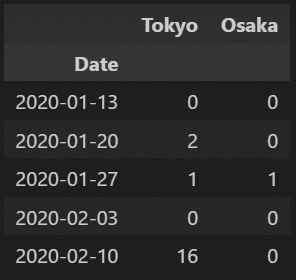
ちなみに、label='left', closed='left'のままで、ruleを'W-mon'とすると月~日曜日集計で月曜日がラベルとして使用されます。
rule='w', label='right', closed='right': 月~日曜日集計(終了日ラベル) ※デフォルト
rule='w', label='left', closed='left': 日~月曜日集計(開始日ラベル)
rule='W-mon', label='left', closed='left': 月~日曜日集計(開始日ラベル)
closedとlabelのあたりが分かりにくいですが、業務で使えそうな集計が簡単にできるので使いこなせるようになりたいです。