
便利ライブラリ Pandas① 基本操作とデータ抽出

Pandasについて
公式ドキュメント
データの読み込み
ライブラリの回の後半で、Pandasを用いてcsvファイルを読み込みました。今回も同じデータを使用し、Pandasの基本操作を紹介します。前回のようにcsvファイルをuploadして使用する方法でも良いですし、Googleドライブ上にcsvファイルを保存し、そのファイルを読み込んで使用することも出来ます。
from google.colab import drive
drive.mount('/content/drive')上記を実行すると、Googleドライブへのアクセス許可を求める画面が表示されます。画面の指示に沿って操作(アクセスを許可)すると、Googleドライブ上のファイルを使用することが出来ます。
Google Colabの左端のフォルダアイコンをクリックすると、driveフォルダが表示され、その下の階層にMyDriveが出来ています。このフォルダはご自身のGoogleドライブを表しており、ドライブ上の目的のファイルで右クリックし「パスをコピー」しておきましょう。
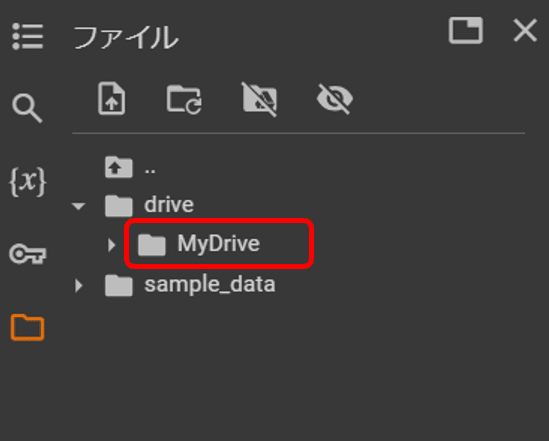
import pandas as pd
file_path = '*********************' #コピーしたファイルパスをペースト
df = pd.read_csv(file_path)今回はcsvファイルでしたが、Excelファイルを使用することもあります。excelを読み込むときは、read_excel()を使用します。第一引数にはファイルパスが入り、第二引数以降に複数シートが存在する場合はシート名を指定したり、列名に使用する行を指定したりすることが出来ます(第二引数以降は省略可能)。
df = pd.read_excel(file_path,
sheet_name='****', #シート名(文字列)
header=0 #列名とする行番号(整数)←1行目=0 という具合にゼロからカウントします
)これで、複数シートが含まれるExcelファイルも、1行目から始まらない表も自由に読み込むことが出来ます。
読み込んだデータは、df.head()もしくはdf.tail()で確認してみましょう。

カラム(列)名の取得→必要な列のみ抽出
カラム(列)名を確認します。
df.columns上記を実行すると、
Index(['Date', 'ALL', 'Hokkaido', 'Aomori', 'Iwate', 'Miyagi', 'Akita', 'Yamagata', 'Fukushima', 'Ibaraki', 'Tochigi', 'Gunma', 'Saitama', 'Chiba', 'Tokyo', 'Kanagawa', 'Niigata', 'Toyama', 'Ishikawa', 'Fukui', 'Yamanashi', 'Nagano', 'Gifu', 'Shizuoka', 'Aichi', 'Mie', 'Shiga', 'Kyoto', 'Osaka', 'Hyogo', 'Nara', 'Wakayama', 'Tottori', 'Shimane', 'Okayama', 'Hiroshima', 'Yamaguchi', 'Tokushima', 'Kagawa', 'Ehime', 'Kochi', 'Fukuoka', 'Saga', 'Nagasaki', 'Kumamoto', 'Oita', 'Miyazaki', 'Kagoshima', 'Okinawa'], dtype='object')
列名のリスト(正確にはインデックスオブジェクト)が取得できます。
データが多いので、扱いやすくするために以下のように必要な列を指定して、別のデータフレーム(df_tohoku)にします。
df[●●●●] ←●●●●には必要な列名のリストが入ります。
df.columnsで取得したリストを使用すれば、簡単に必要列名のリストを作成できます。順番を変えることも出来ます。
# 必要な列のみ抽出
df_tohoku = df[['Date', 'ALL', 'Aomori', 'Iwate', 'Miyagi', 'Akita', 'Yamagata', 'Fukushima']]
カラム名の変更
カラム名の変更には、rename()メソッドを使用します。columns=以降に現在の列名と変更後の列名を辞書形式で渡します。辞書については以前の投稿をご参照ください。
列名変更後のデータフレームを別の変数に格納するか、第二引数にinplace=Trueと入れて現在のデータフレームに上書きします。
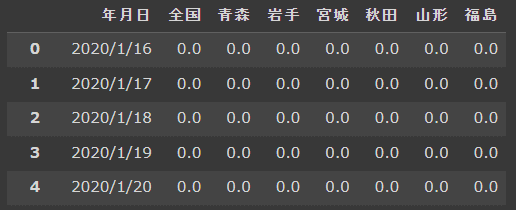
df_tohoku.rename(columns={'Date': '年月日',
'ALL': '全国',
'Aomori': '青森',
'Iwate': '岩手',
'Miyagi': '宮城',
'Akita': '秋田',
'Yamagata': '山形',
'Fukushima': '福島'},
inplace=True #df_tohokuに変更が上書きされます
)
インデックスの指定
現時点では、インデックス(行名)には番号(0~)が振られていますが、set_index()に列名を指定することで特定の列をindexとすることが出来ます。
df_tohoku.set_index('年月日', inplace=True)列・行の削除
drop()で不要な列や行を削除することも出来ます。列(行)名を文字列で指定します。複数ある場合はリストで指定します。第二引数のaxis=は、削除する方向を指定します。0は行、1は列を示します。
df_tohoku.drop('全国', axis=1, inplace=True)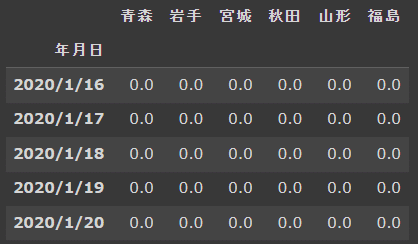
データ抽出(query)
①等号・不等号で抽出
query()を使用することで、データフレームから特定のデータを抽出することが出来ます。
例えば、「20よりも大きいデータ」など数字の大小で条件式を作成することで抽出できます。andやorを使用し条件式を複数組み合わせることも出来ます。
df_tohoku.query('青森 >= 20 and 岩手 >= 20')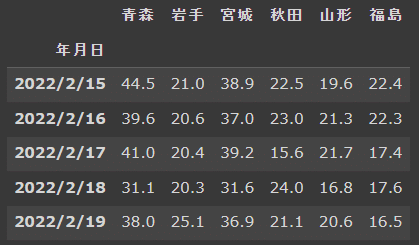
②リストに含まれるものを抽出
あらかじめリストを作成しておいて、そのリストに合致するものだけを抽出することも出来ます。
query()の引数は文字列なので、リストを格納した変数を使用する場合は、f-stringsを使用するか変数の前に@マークを付けます。以下の3パターンはいずれも同じデータフレームを返します。
# リストを直接入力
df_tohoku.query('青森 in [10, 20, 30, 40]')
list1 = [10, 20, 30, 40]
# f-strings
df_tohoku.query(f'青森 in {list1}')
# @マークを使用
df_tohoku.query('青森 in @list1')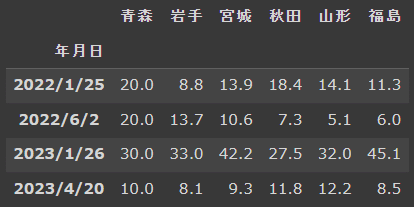
③文字列の抽出
今回のデータフレームは数字のデータが入っていましたが、文字列が入ったテーブルを読み込んで使用することもあります。
pd.DataFrame(二次元配列)でデータフレームを作成することができます。文字列を含む以下のデータフレームを作成します。
df_drug = pd.DataFrame([['ウィフガート点滴静注400mg', 'アルジェニクスジャパン', 388792],
['ウブレチド錠5mg', '鳥居薬品', 14.9],
['ソリリス点滴静注300mg', 'アレクシオンファーマ', 619834],
['ネオーラル10mgカプセル', 'ノバルティスファーマ', 52.3],
['ネオーラル25mgカプセル', 'ノバルティスファーマ', 114.8],
['ネオーラル50mgカプセル', 'ノバルティスファーマ', 192.9],
['プログラフカプセル1mg', 'アステラス製薬', 453.2],
['プログラフカプセル0.5mg', 'アステラス製薬', 245.5],
['ジルビスク皮下注16.6mgシリンジ', 'ユーシービージャパン', 69580],
['ジルビスク皮下注23.0mgシリンジ', 'ユーシービージャパン', 96347],
['ジルビスク皮下注32.4mgシリンジ', 'ユーシービージャパン', 135661],
['マイテラーゼ錠10mg', 'アルフレッサファーマ', 15.9],
['リスティーゴ皮下注280mg', 'ユーシービージャパン', 356392],
['ユルトミリスHI点滴静注300mg/3mL', 'アレクシオンファーマ', 699570],
['ユルトミリスHI点滴静注1100mg/11mL', 'アレクシオンファーマ', 2565090]
])
df_drug.columns = ['drug', 'maker', 'price']
等号(==)を用いて一致するものを抽出できます。query()の引数は文字列なので、引数全体を’(シングルクオテーション)で囲った場合、条件式内の文字列には"(ダブルクオテーション)を使用する必要があります。
df_drug.query('maker == "ユーシービージャパン"')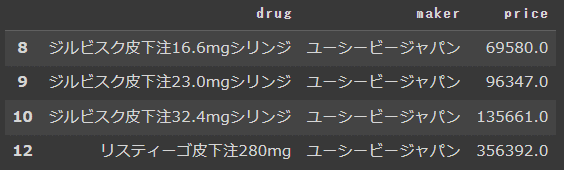
また、str.contains()を用いてあいまい検索をすることも出来ます。str.contains()の引数も文字列になるので、'と"を区別して使用するように注意してください。
医薬品名に「注」という文字列が含まれるものを抽出してみましょう。
df_drug.query("drug.str.contains('注')")
Pandasはよく使用します。今後、データの可視化についても書く予定ですが、可視化をする前にデータをきれいな形に整えるステップが最重要で、Pandasを使いこなす必要があります。データ分析をする場合、Pandasは基礎となるので頑張って習得していきましょう。
・・・と言っても忘れていくので、自分の覚え書としてまとめながら書いています。1回では書ききれないので何回かに分けて投稿していきます。