
便利ライブラリ Pandas② 日付データの処理とiloc

Pandasについての第2回目です。
Pythonの基本⑤ ライブラリで扱ったcsvファイルを使用してデータ処理を行っていきます。csvをダウンロードし、ご自身のGoogleドライブ上に保存してから進んでください。
以下のコードで、csvファイルをPandasを用いて読み込んでデータフレームを作成します(説明の都合上、インデックスの設定はしていません)。Pandas①で扱ったコードなので、前回の投稿をご覧になってない方はそちらもご参照ください。
import pandas as pd
from google.colab import drive
drive.mount('/content/drive')file_path = "******************" # ←マウントしたGoogleドライブ上のファイルパスをコピーしペーストしてください
# ファイルの読み込み
df = pd.read_csv(file_path)
# データフレームの整形
df_tohoku = df[['Date', 'Aomori', 'Iwate', 'Miyagi', 'Akita', 'Yamagata', 'Fukushima']]
df_tohoku.rename(columns={'Date': '年月日',
'Aomori': '青森',
'Iwate': '岩手',
'Miyagi': '宮城',
'Akita': '秋田',
'Yamagata': '山形',
'Fukushima': '福島'},
inplace=True
)日付データの処理
to_datetime()
「〇年♢月~△年▽月のデータを抽出」して解析するなど、データの整形をする際に日付データの処理はマストのスキルです。
まずは、データフレームに入っているデータ型を確認してみましょう。
df_tohoku.dtypes
年月日は「object」と表示され、date型ではありません。その他のcolumnsにはfloat型(浮動小数点型)のデータが入っていることが分かります。このままでは、上手く期間抽出が出来ないので、Pandas(pdと省略表示)のto_datetime()メソッドでdate型に変換します。
ちなみに、df['列名'] にリストもしくはseries(1列だけのデータフレーム)を渡すことで、データフレームに新たな列を追加することが出来ます。
df_tohoku['date'] = pd.to_datetime(df_tohoku['年月日'])先程と同様に、df_tohoku.dtypesでデータがを確認すると、
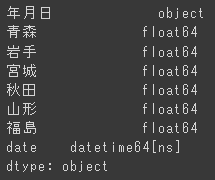
最終列に「date」列が追加され、datetime型であることが分かります。今回は説明のために、「date」という列名を作成しましたが、上記コードでdf_tohoku['年月日']とすると、「年月日」列にdatetime型のデータが上書きされるので、列整理する手間も省けます。
(余談)str型 ⇒ datetime型 ⇒ date型
データフレームに限らず、日時の扱いにはしばしば悩まされるので覚え書です。
from datetime import datetime as dt
import datetime
date = '2024年2月11日8時30分'
date1 = dt.strptime(date, '%Y年%m月%d日%H時%M分') # dateのフォーマットに合わせてY、m、d、H、Mを指定
date1実行すると、
> datetime.datetime(2024, 2, 11, 8, 30) とstrptime()を使用することで、datetime型に変換できます。
date1.yearとすると、2024が取り出せます。同様に、monthやdayで各要素を取り出すことが出来ます。
date2 = datetime.date(date1.year, date1.month, date1.day)
print(date2)分解した要素を使用し、datetime.date()でdate型のデータとして再構成することができます。
(ついでに)datetime型 ⇒ str型
str型をdate型にしたいときもあれば、その逆もあります。例えば、毎日決まった時間にExcelファイルを自動集計するプログラムを作成したとします。集計結果を保存するファイル名が毎回同じだと、過去のファイルに上書きされてしまうのでデータが残りません。そんな時、strftime()を使用し日時を文字列にして、f-stringsでファイル名に組み込むことで解決できます。
※datetime.now()だけでも年月日は取得できますが、日本時間ではないので時間がズレます。タイムゾーンを設定するためにZoneInfo()を使用しています。
from datetime import datetime
from zoneinfo import ZoneInfo
now = datetime.now(ZoneInfo("Asia/Tokyo")) # datetime.datetime(2024, 2, 11, 8, 33, 28, 430304, tzinfo=zoneinfo.ZoneInfo(key='Asia/Tokyo'))
today = now.strftime('%Y年%m月%d日') # '2024年02月11日' ※文字列
df.to_excel(f'集計{today}.xlsx')上記を実行することで、データフレームを「集計2024年02月11日.xlsx」というファイル名で保存することが出来ます。もちろん時間(%H)や分(%M)を組み込むことも可能です。
期間を使用したデータフレームの抽出
date型(datetime型)に変換できれば、前回の投稿と同様にqueryを使用することが出来ます。
# 不要な「年月日」列は削除し、「date」列の位置を変更
df_tohoku = df_tohoku[['date', '青森', '岩手', '宮城', '秋田', '山形', '福島']]
df_tohoku2 = df_tohoku.query("'2021-08-01' <= 年月日 <= '2021-08-05'") # queryで日付を扱うときは文字列と同様にクオテーションで囲う
df_tohoku2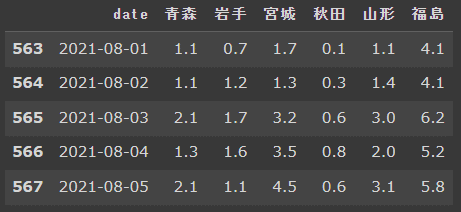
query()の引数で指定した期間のデータが抽出され、df_tohoku2という変数に格納されています。queryで日付を扱うときは文字列と同様にクオテーションで囲う必要があるので注意してください。
データフレームから個々のデータを取り出す iloc
ilocを用いることで、データフレームから行・列を指定して、データを取り出すことが出来ます。
df.iloc[行, 列] というように記載し、行全体や列全体を取得したい場合は「:」を入力します。また、行番号や列番号は0から始まるので注意してください。
# 例①
df_tohoku2.iloc[1, 1]
# 例②
df_tohoku2.iloc[3, :]
# 例③
df_tohoku2.iloc[:, 4]
# 例④
df_tohoku2.iloc[1:3, 6]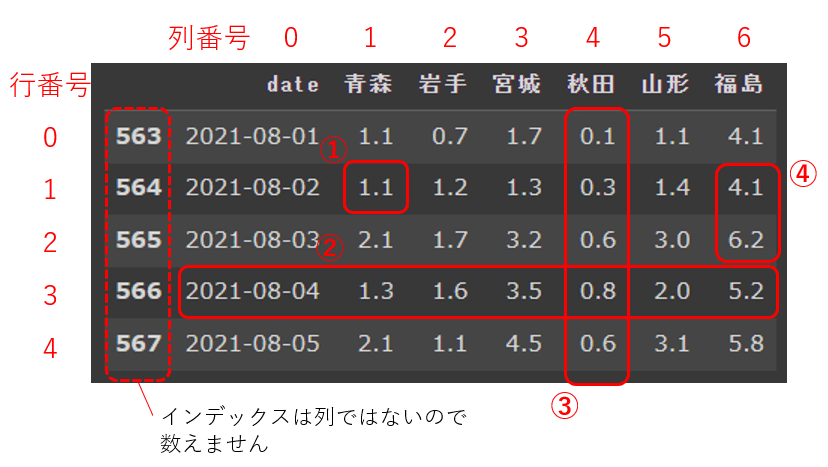
例①~④を実行すると上記の範囲が取得できます。例④のように「1:3」という表現を使用することもあります。少しわかりにくいですが、図のように要素の区切り位置を指定しているとイメージした方が理解しやすいかもしれません。

ilocは数字でデータフレームを切り取ってくることが出来るので、for文と組み合わせてデータフレームのデータを順番に取り出して処理をする場面でも役立ちます。
例えば、df_tohokuは人口10万人あたりの新型コロナウイルス感染者数なので、秋田県下の感染者数を日ごとに計算することも出来ます。
akita = 96.6 # 秋田県人口=96.6万人
for i in range(len(df_tohoku2)):
date = df_tohoku2.iloc[i, 0].strftime('%Y年%m月%d日')
morbidity = df_tohoku2.iloc[i, 4] * akita/10
print(f'{date}の新型コロナ感染者数は{morbidity:.0f}名です。')今回はだいぶ脱線しましたが、Pandasについてまだまだ続きます!