
「SkyWay Media Pipeline Factory」の音声認識と翻訳のセットアップ

先日、「SkyWay Media Pipeline Factory」のトライアルを申し込んでドキュメントのチュートリアルを試してみました。
SkyWay(WebRTC)の音声をwavファイルに変換してAWSのS3に保存する機能と、GCPのAPIを使った音声認識と翻訳のコンポーネントを試しました。備忘録と答え合わせを兼ねてnoteに書いておこうと思います(間違いなどがあればご指摘頂けると助かります)。

AWSのCognito APIのセットアップ
WebRTCの音声ストリームをwavファイルに変換してAWSのS3に保存する手順です。
AWSを利用するための準備として以下の指示があります。
なお、本チュートリアルで作成される録音ファイルは、AWS S3に保存されますので、事前に AWS アカウント、S3の設定(Bucket設定)および Cognito API による ID プール設定が必要となります。
具体的には次のような設定が必要です。
Cognito APIを用いた IdentityPoolId のセットアップ
"Unauthenticated Identities" として設定ください。
また、"AmazonS3FullAccess" の権限が必要です。
AWSのコンソールにログインして、Cognito APIの画面から「IDプールの管理」をクリックします。

次に「新しいIDプールの作成」をクリックします(画像ではすでにセットアップ済みのIDプールが表示されています)。
「新しいIDプールの作成」の画面が表示されるので、適当な「IDプール名」を入力して「認証されていないIDに対してアクセスを有効にする」のチェックを入れます。「"Unauthenticated Identities" として設定ください」の指示がこれに該当します(おそらく)。

次の画面では「IAM roleを割り当ててください」というニュアンスの警告が表示されます。ひとまずデフォルトのままでも良さそうなのでそのまま進めます。「As a best practice,...」とあるのでそこに書いてある通りにやるのが良さそうです、各自の判断で適切に設定してください。

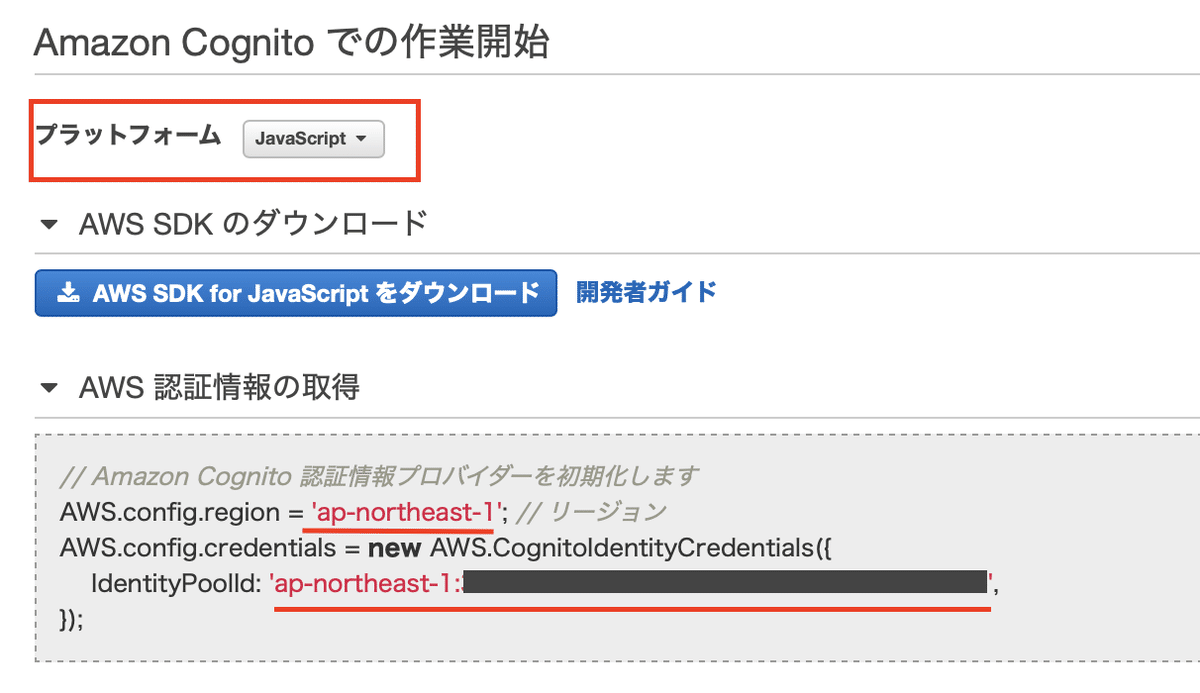
次の画面でIdentity Pool IDのクレデンシャルが表示されます。表示をわかりやすくするために「プラットフォーム」を「JavaScript」に変更します。赤線のアンダーラインを引いた部分が後で必要になるのでメモしておきます(IdentityPoolIDは認証情報なので安全な場所で管理します)。
管理画面のトップに戻ると、先ほど作成したIDプールが表示されています。

以上でCognito APIを用いた IdentityPoolId の作成は完了です。
作成したIdentityPoolIdを使ってAWS S3 にデータを保存するためには権限を追加する必要があります。AWSコンソールに戻って IAM の管理画面から「ロール」をクリックします。
先ほどIdentity Pool IDを作成した際に自動的にロールが作成されているので末尾が「...Unauth_Role」のものを選択します。
ロールの編集画面が表示されるので「ポリシーをアタッチします」をクリックします。
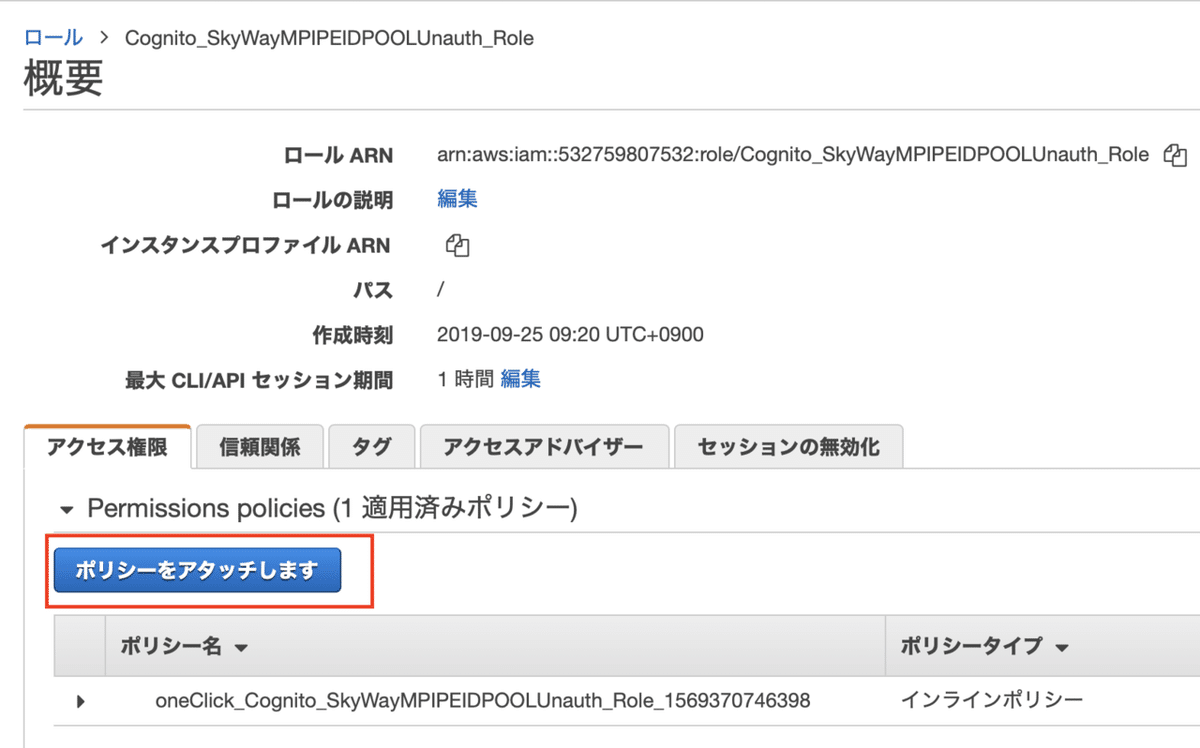
検索画面が表示されるのでフィルタに「S3Full」まで入力すると「AmazonS3FullAccess」ポリシーが表示されるのでチェックを入れてポリシーをアタッチします。
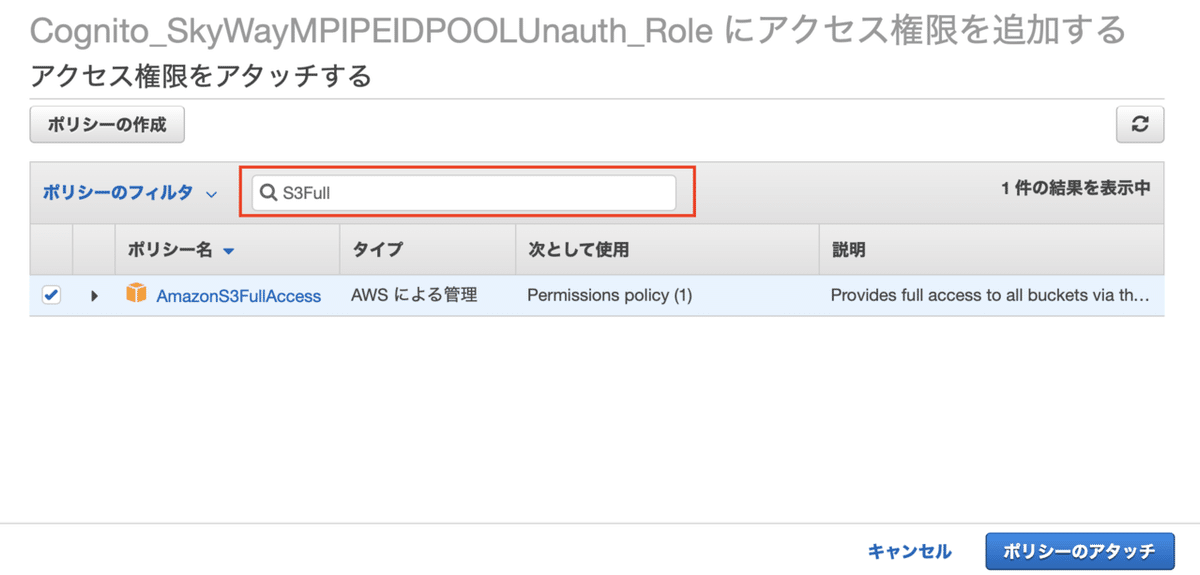
編集画面に戻ると先ほどアタッチしたポリシーがロールに適用されています。

以上でS3へ書き込みするための準備完了です。
私が試した際にはS3のバケットを作成しておく必要がありました。バケットが存在しない状態で録音を行うと以下のエラーが表示されました。

S3の管理画面から適当な名前でバケットを作成しておきます。バケットは動作確認用途であればデフォルト設定のままで問題なさそうですが、各自のセキュリティ要件に合わせて適切に設定してください。
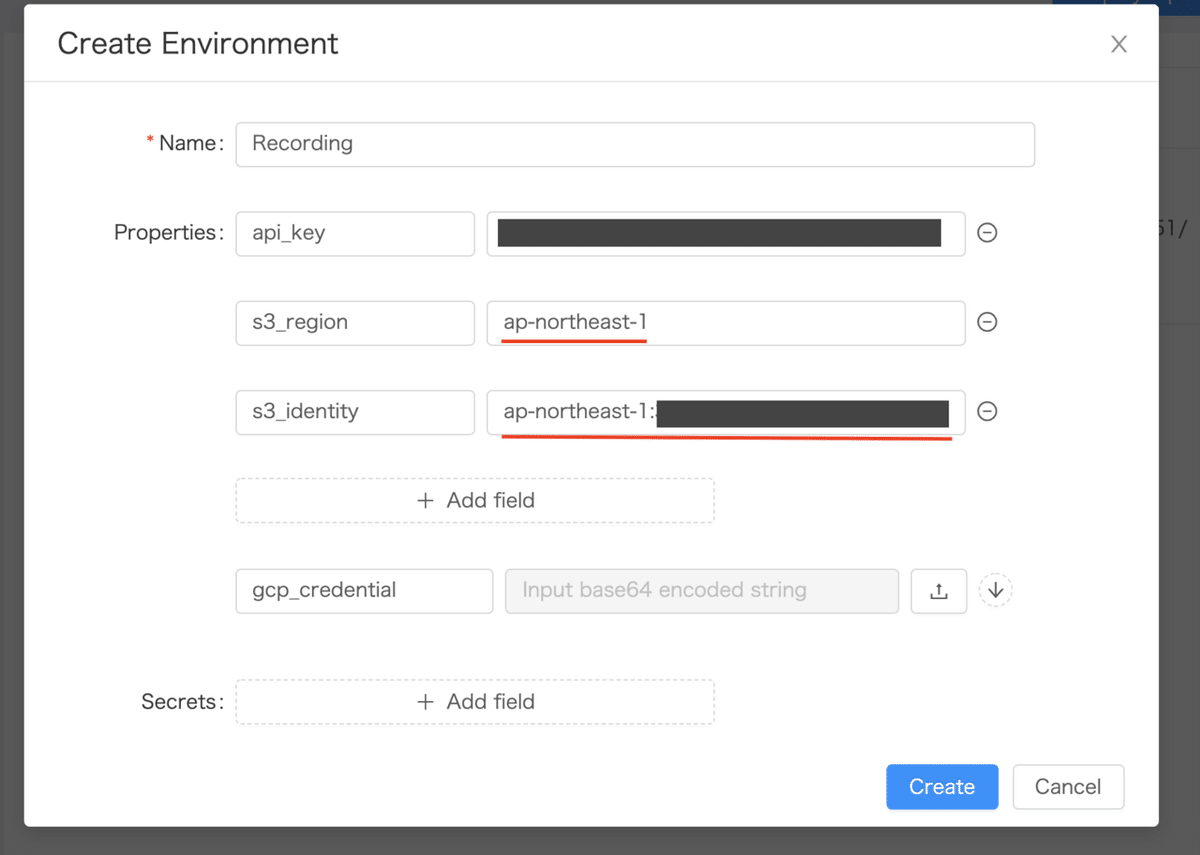
その後、ユースケースに従って「環境の新規作成」を行います。その際に、先ほどメモしておいたIdentity Pool IDの情報を入力します。
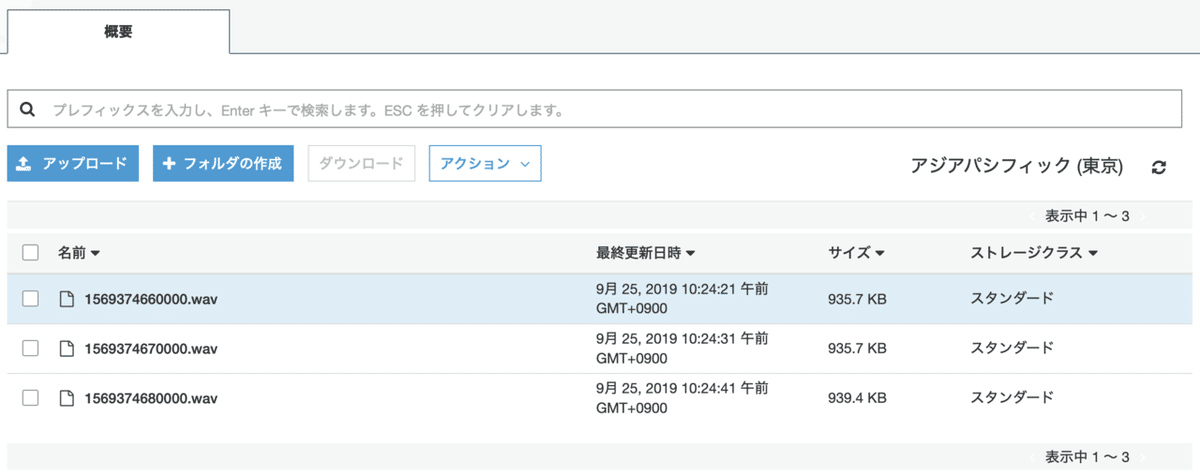
パイプラインをデプロイしてテスト画面から動作を確認します。設定に問題がなければS3にwavファイルが保存できるようになります。
GCPのAPIを利用するための設定
ビルトインの音声認識・翻訳はGCPのAPIを利用しているのでGCPのセットアップが必要です。
GCPのコンソールにログインしたら適当なプロジェクトを作成します。
プロジェクトを作成したら次にAPIを有効化します。今回は音声認識と翻訳を利用するので Cloud Speech-to-Text API と Cloud Translation API を有効化する必要があります。左上のメニューから APIとサービス => ライブラリ を選択します。検索画面に speech と入力して「Cloud Speech-to-Text API」を選択して「有効にする」をクリックして完了です。
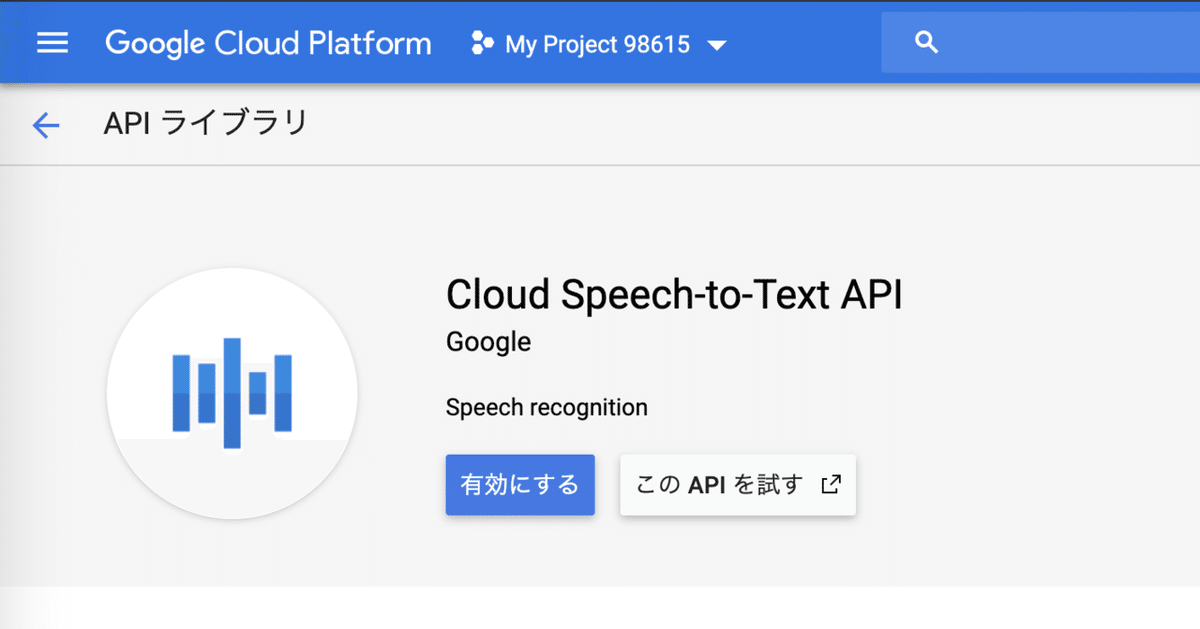
同様の手順で Cloud Translation API も有効化します。
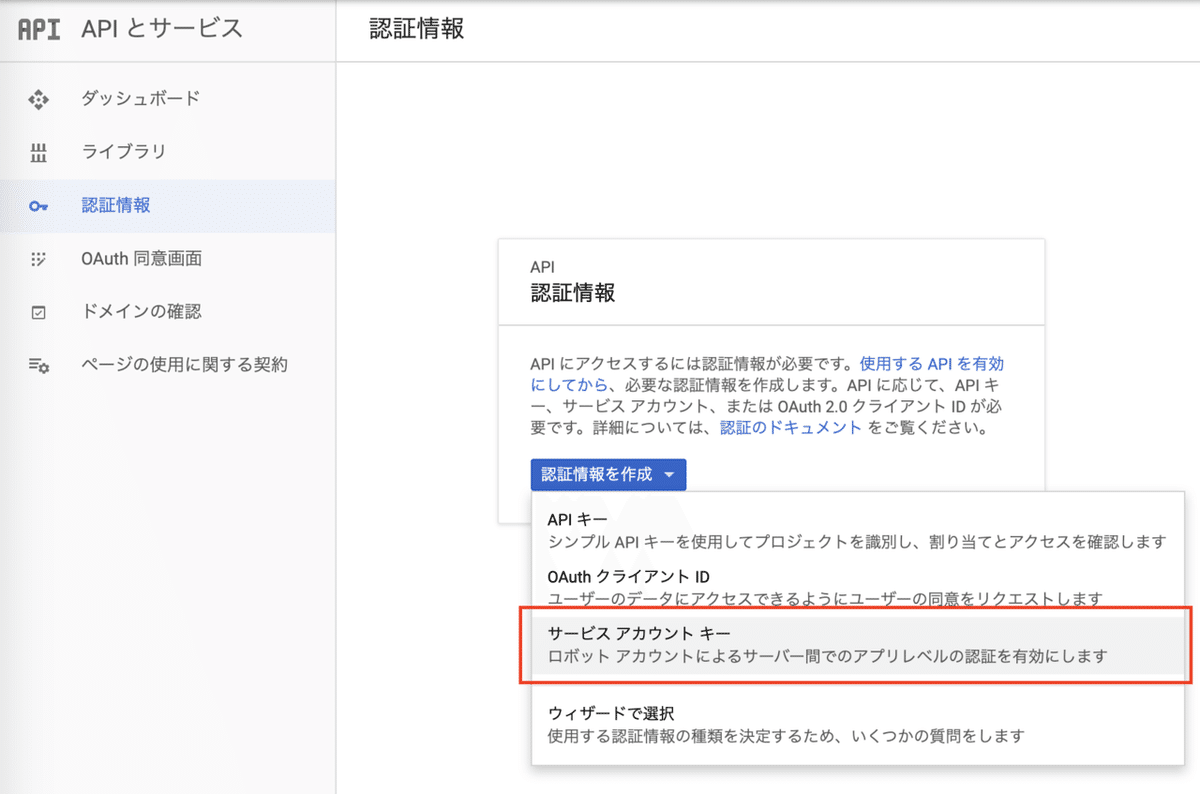
次に、これらのAPIを Media Pipeline から利用するために必要な認証情報を作成します。左上のメニューから APIとサービス => 認証情報 を選択します。「認証情報を作成」をクリックしてサービスアカウントキーを選択します。
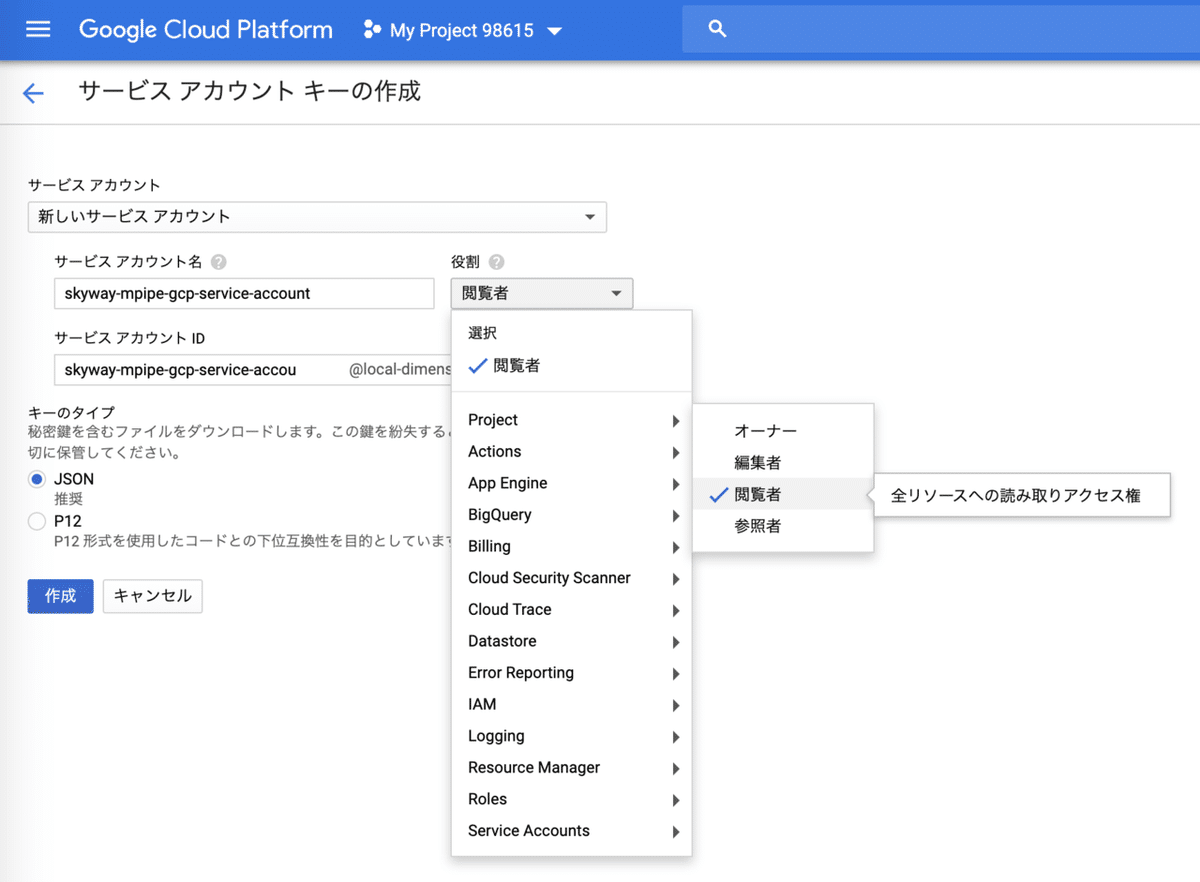
「サービスアカウントキーの作成」の画面が表示されるので情報を入力します。「役割」については必要最低限の権限を付与すれば良さそうですが、良く分からなかったので Project => 閲覧者 を選択しました。役割については正確に把握していないのであまり自信がありません。設定が終わったら「キーのタイプ」にJSONを選択して「作成」を押すとjsonファイルがダウンロードされます。ダウンロードしたjsonファイルはパイプラインで gcp credential として利用します。
GCPの設定は完了したのでPipelineにパラメータを設定してデプロイします。db_identityとs3_identityはIdentity Pool IDを指定します。db_regionとs3_regionは同じ値です。gcp_credentialにダウンロードしたjsonファイルをアップロードします。
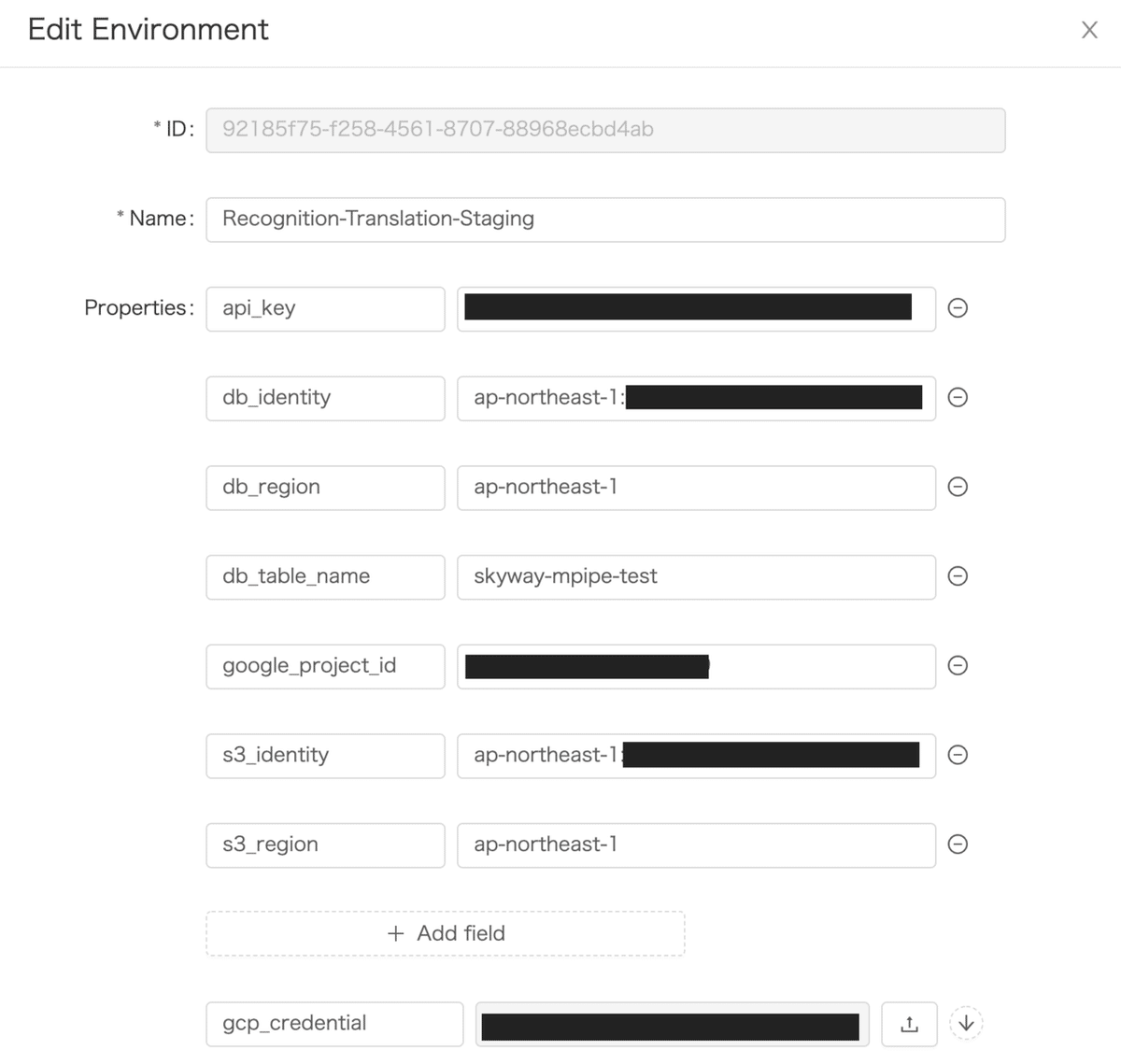
DynamoDBへ書き込みするためには AmazonDynamoDBFullAccess のポリシーが必要なので、先ほどと同様の手順でロールに追加します。
GCPのAPI利用状況はダッシュボードで確認できます。

まとめ
WebRTC Gatewayの運用をクラウド側で面倒を見てくれるのはとても有り難いように思いますし、SDKが用意されているので自分でパイプラインを拡張することもできそうです。
余談
Speech-to-Text APIの料金を調べてみました。
最も安い条件でも $0.004/15 秒 なので1時間で1ドル程度のようです、まあまあのお値段ですね。