各証券会社の日経225先物取引を予測

1.初めに
50歳目前に約20年勤務した会社を退職、これから先どうしようか、自分は何がしたいのか、何ができるのか、これまでの自分を振り返り、考えながらほんの少し人生の休暇を過ごすことになりました。
「Python」やってみない?株式投資や新しい仕事でも使えるかも?という友人の一言からまず「python」について色々検索することから始まりました。せっかく時間もあるし、集中して勉強してみようと学校選びをして、Aidemyのデータ分析講座の受講を決めました。
2.記事の対象者
何か新しいこと始めようという人や機械学習を始めてみようという人にお読みいただき、励みになればと思います。
3.使用した環境
Mac Book Air(M1)
GoogleColaboratory
Python 3.7.12
4.手順
最終的に何を分析するか?課題を決めるところから始めました。シンプルでもいい、機械学習を始めるきっかけとなった株価予測をしてみることに決めました。友人にも相談し、過去3ヶ月分蓄積した各証券会社の日経225先物取引の売買実績から売買予測を立ててみることにしました。
予測したい値に対して、直近3日間の売買データを特徴量として予測を行いました。モデルは、ロジスティック回帰、SVM、ランダムフォレストを使用しました。
4-1.データの収集
まずはデータを用意し、手動でフォーマットを整えました。
GoogleColaboratoryセッションストレージに取り込みました。

コードを書いていきます。
4-2.環境構築
GoogleColaboratoryにはデフォ流で入っていないmecabのインストールを行います。
#mecab環境構築
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.74-3.ライブラリのインポート
以下のライブラリをインポートします。
import MeCab
import re
import numpy as np
import pandas as pd
from io import StringIO
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC4-4.データの読み込み
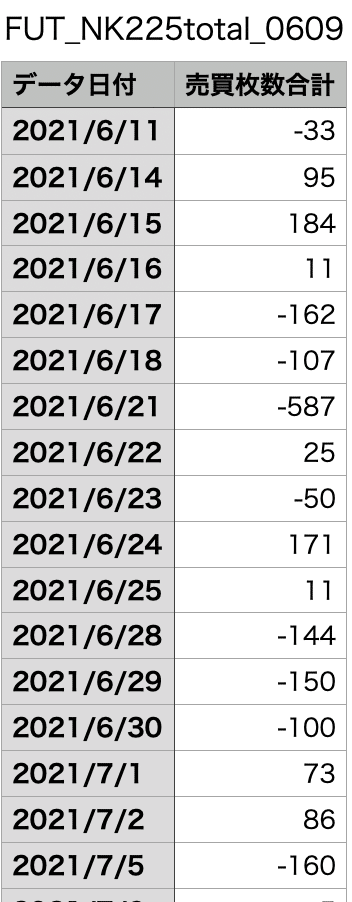
収集したデータを読み込みます。
#データの読み込み
df = pd.read_csv('/content/FUT_NK225total_0609.csv')
df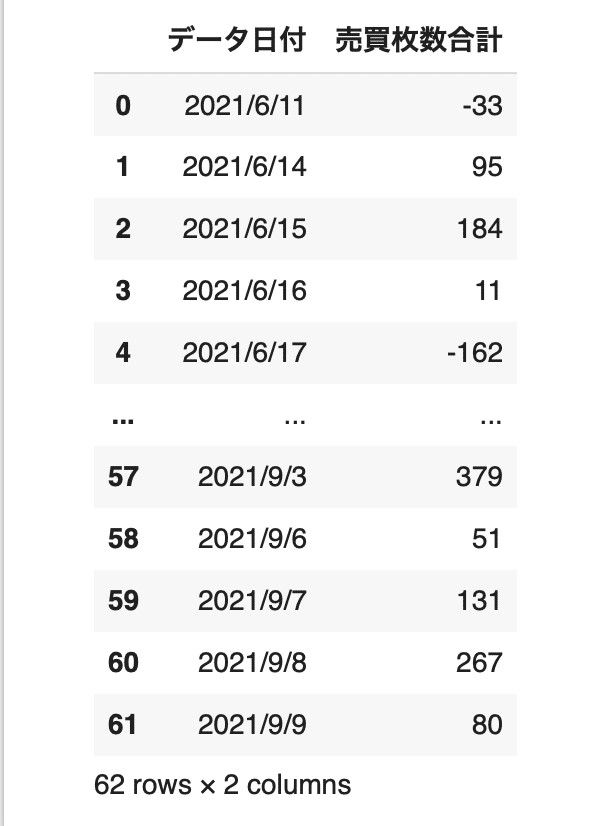
4-5.データの前処理
indexを日付に変換します。
# indexを日付にした後、時系列にする(データの前処理)
df["データ日付"] = pd.to_datetime(df["データ日付"], format='%Y/%m/%d')
table = df.set_index('データ日付')
table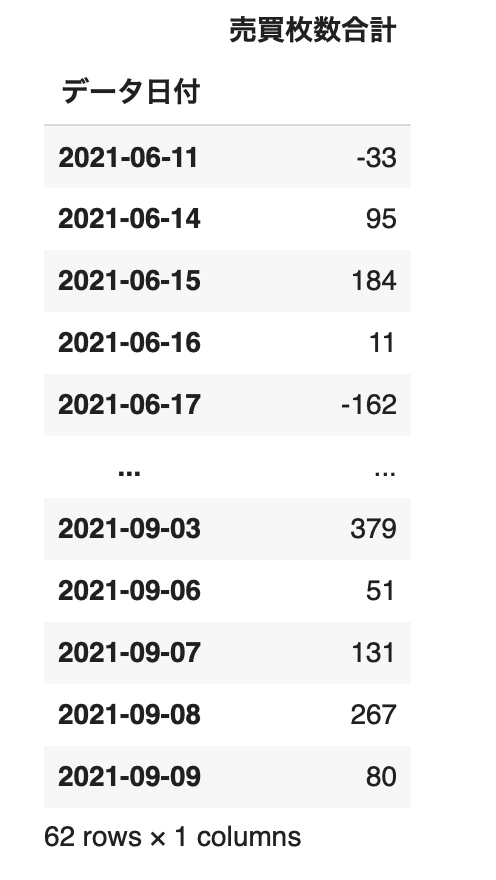
学習データとテストデータに8:2の割合で分割します。
#トレーニングデータとテストデータに分割
X = table.values[:, 0]
X = X.astype(int)
X_train, X_test = train_test_split(X, test_size=0.2, random_state=0, shuffle=False)
X_train
学習データ及びテストデータをdataframeに格納します。
# df_trainというテーブルを作りそこにindexを日付、カラム名を売買にしてdf_train.csvという名前で保存
df_train = pd.DataFrame(
{'売買': X_train},
columns=['売買'],
index=table.index[:len(X_train)])
df_train.to_csv('./df_train.csv')
# テストデータについても同様にdf_testというテーブルを作り、df_test.csvという名前で保存
df_test = pd.DataFrame(
{'売買': X_test},
columns=['売買'],
index=table.index[len(X_train):])
df_test.to_csv('./df_test.csv')売買の各日のデータについて、前日との差を算出します。
#売買の各日のデータについて、前日との差を算出
rates_fd = open('./df_train.csv', 'r')
rates_fd.readline() # 1行だけ読み込む
exchange_dates = []
exchange_rates = []
exchange_rates_diff = []
prev_exch = df_train['売買'].mean()
for line in rates_fd:
splited = line.split(",")
time = splited[0] # table.csvの1列目日付
exch_val = float(splited[1]) # table.csvの2列目売買価格
exchange_dates.append(time) # 日付
exchange_rates.append(exch_val)
exchange_rates_diff.append(exch_val - prev_exch) # 売買の変化
prev_exch = exch_val
rates_fd.close()
print("exchange_dates", exchange_dates)
print("exchange_rates", exchange_rates)
print("exchange_rates_diff", exchange_rates_diff)
print("prev_exch", prev_exch)
機械学習モデルに入力するために、データの整形を行います。
予測したい値に対して、直近3日間の売買データを特徴量としています。
#直近3日間の売買の上下をクラス分けし、トレーニングデータとテストデータを作成
INPUT_LEN = 3
data_len = len(exchange_rates_diff)
tr_input_mat = []
tr_angle_mat = []
for i in range(INPUT_LEN, data_len):
tmp_arr = []
for j in range(INPUT_LEN):
tmp_arr.append(exchange_rates_diff[i-INPUT_LEN+j])
tr_input_mat.append(tmp_arr) # i日目の直近3日間の売買の変化売買の変化
if exchange_rates_diff[i] >= 0: # i日目の売買の上下、プラスなら1、マイナスなら0
tr_angle_mat.append(1)
else:
tr_angle_mat.append(0)
train_feature_arr = np.array(tr_input_mat)
train_label_arr = np.array(tr_angle_mat)
# test_feature_arr, test_label_arrを同様に作成
rates_fd = open('./df_test.csv', 'r')
rates_fd.readline() # 1行だけ読み込む
exchange_dates = []
exchange_rates = []
exchange_rates_diff = []
prev_exch = df_test['売買'].mean()
for line in rates_fd:
splited = line.split(",")
time = splited[0] # table.csvの1列目日付
exch_val = float(splited[1]) # table.csvの2列目株価の売買
exchange_dates.append(time) # 日付
exchange_rates.append(exch_val)
exchange_rates_diff.append(exch_val - prev_exch) # 株価の変化
prev_exch = exch_val
rates_fd.close()
print("tr_input_mat", tr_input_mat)
print("tr_angle_mat", tr_angle_mat)![]()
INPUT_LEN = 3
data_len = len(exchange_rates_diff)
test_input_mat = []
test_angle_mat = []
for i in range(INPUT_LEN, data_len):
test_arr = []
for j in range(INPUT_LEN):
test_arr.append(exchange_rates_diff[i - INPUT_LEN + j])
test_input_mat.append(test_arr) # i日目の直近3日間の株価とネガポジの変化
if exchange_rates_diff[i] >= 0: # i日目の株価の上下、プラスなら1、マイナスなら0
test_angle_mat.append(1)
else:
test_angle_mat.append(0)
test_feature_arr = np.array(test_input_mat)
test_label_arr = np.array(test_angle_mat)
print("test_input_mat", test_input_mat)
print("test_angle_mat", test_angle_mat)![]()
4-6.学習と評価
train_feature_arr, train_label_arr,test_feature_arr, test_label_arrを特徴量にして、予測モデルを構築し、予測精度を計測します。
予測モデルには下記の3つのモデルを使用します。
・ロジスティック回帰
線形分離可能なデータの境界線を学習によって見つけてデータの分類を行う手法です。境界線が直線のため、二項分類などクラスの少ないデータに用いられます。
・SVM(サポートベクターマシン)
サポートベクトルとよばれるベクトルを用いて境界線を作成し、データの分類を行う手法です。境界線が2クラス間の最も離れた場所に引かれるためロジスティック回帰と比べて一般化されやすく、データの分類予測が向上する傾向があります。
・ランダムフォレスト
前述の決定木の簡易版のモデルを複数作り、分類の結果をモデルの多数決で決める手法です。線形分離可能でない複雑な識別範囲を持つデータ集合の分類にも使えます。
評価指標には正解率を利用し、各モデルの比較を行います。
for model in [LogisticRegression(), RandomForestClassifier(n_estimators=200, max_depth=8, random_state=0), SVC()]:
model.fit(train_feature_arr, train_label_arr)
print("--Method:", model.__class__.__name__, "--")
print("scores:{}".format(model.score(test_feature_arr, test_label_arr)))--Method: LogisticRegression --
scores:0.6
--Method: RandomForestClassifier --
scores:0.7
--Method: SVC --
scores:0.7
5.結果
データ量が少なく、効果的な結果は出ませんでした。
上記は、日経225の売買合計値で行ったものです。他参加する証券会社3社についても同様に実行してみましたが、下記の通りの結果であり、同様に効果的な結果が出ませんでした。
1社目の結果
--Method: LogisticRegression --
scores:0.7
--Method: RandomForestClassifier --
scores:0.4
--Method: SVC --
scores:0.6
2社目の結果
--Method: LogisticRegression --
scores:0.8
--Method: RandomForestClassifier --
scores:0.6
--Method: SVC --
scores:0.6
3社目の結果
--Method: LogisticRegression --
scores:0.6
--Method: RandomForestClassifier --
scores:0.6
--Method: SVC --
scores:0.4
6.考察と今後の展望
データ数が少ないことによって正常な評価ができていない可能性が高いため、
もう少しデータが豊富な米国株のデータセットなどで検証してみることが必要です。
また、今回は基本的デフォルトパラメーターで評価を行いましたが、ハイパーパラメーター探索等で最適なハイパーパラメーターを決定することによって、精度が上がるか検証が必要でした。
今回は上がったら「1」下がったら「0」という設定で行いましたが、実際には取引手数料等も考慮してある一定以上上がったり下がったりした場合をクラスとして導入する必要がしました。今後自身のポートフォリオでカスタマイズして行けたら良いと思います。
また、今回は時系列を取り扱うものではありませんが、今後は時系列モデルであるSARIMAモデルやLSTMなども活用したものを作成していく必要があります。
7.あとがき
講座を進めていく中でプログラミングの経験もなければ、中学の数学もほとんど忘れいている私には無謀極まりないこととを始めてしまったと痛感しました。わからないなりにもなんとか講座を完了しなければと思い、カウンセリングを受けながら添削課題を提出し、最終ブログの準備に取り掛かりました。
カウンセリングでサポートしていただくと全くわからなかったことがぼんやりとわかるような気がしてきましたし、やる気も湧いてきました。全く知らない世界を知ることができ、優秀なチューターさん達とコミュニケーションを取ることができたことはとても有意義なことでした。
まだまだわからないことだらけですが、これをきっかけに継続的に学習を続けていきたいと思っています。6ヶ月間Aidemyで学び続けることができたことを心より感謝申し上げます。