
競馬予想支援システム データベース設計の紹介

こんにちは、ようへいです。
以下の記事で、運用中の自作システム「競馬予想システム」の概要をお伝えしました。
今回の記事では、この競馬予想システムを実現するために自ら設計したデータモデルを簡単に説明をしながら公開したいと思います。
記事の最後に、PDFのERDとテーブル定義書、テーブル定義書を読むのに必要なコード定義書がダウンロードできます。
僭越ながら、ERDやデータベース設計の参考にして頂けると幸いです。
前提読者
ERDの読み方がわかる方
テーブル定義書の読み方がわかる方
こんな人にオススメ
IT技術者の方
データベース設計に興味のある方
データベース設計でアイディアとして見てみたい方
データモデル解説
DBMSにはMySQLを採用しています。
オープンソースなのと、高性能なためです。
ERDは、SQL開発ツールであるA5M2を使用して描いています。
データモデルは、一般的なサロゲートキーのメリットを踏まえ、開発生産性を上げるため、サロゲートキー方式を採用しています。
ナチュラルキーは、ERDには赤字で表現しており、データベースの物理設計時にはユニークキーを設定しています。
ERDでは省略していますが、以下の属性が共通属性として各テーブルに存在します。
バージョン(データの更新回数。楽観ロック用。使うのは自分だけなのでロックも何もないですが・・・・)
登録日時
登録ユーザーID
更新日時
更新ユーザーID
削除番号(論理削除を示すデータで、"0"が生存、それ以外が論理削除)
ワークテーブル
レース結果や出馬表の取り込みにおいて、マスターやトランザクションにデータを作るための手段として、一時的に作られるテーブル群。
このテーブル群にデータを蓄積する場合、事前にデータをクリアしてからデータを蓄積する。
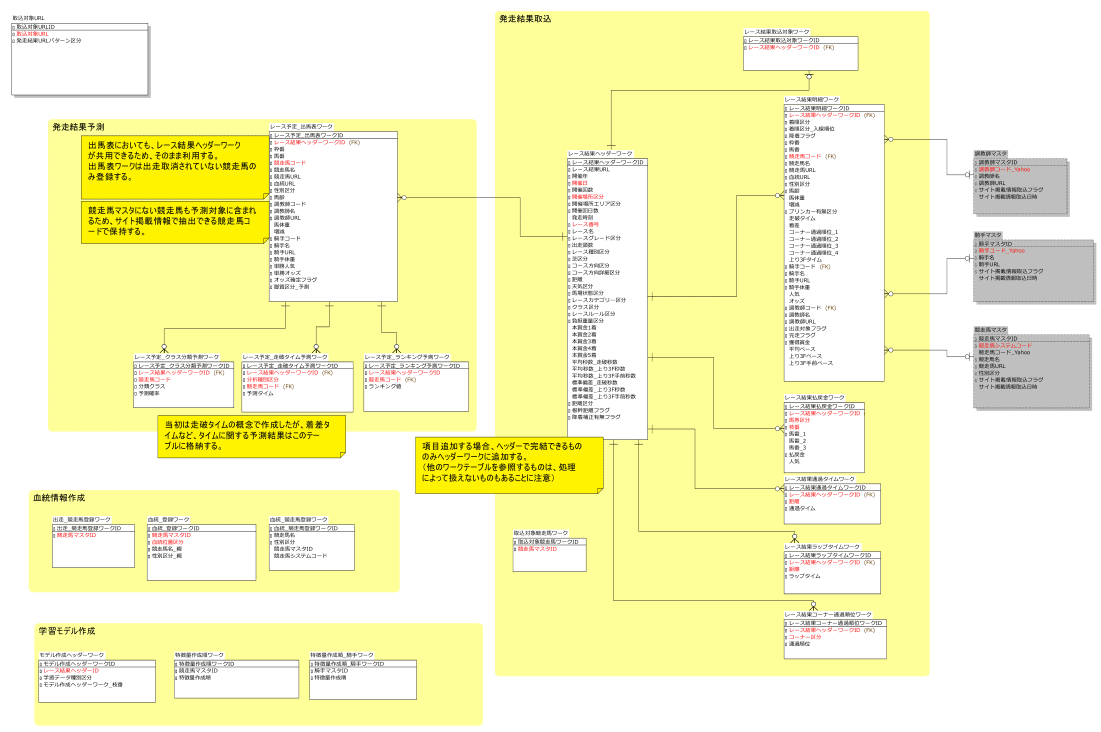
発走結果予測(AIで利用する出馬表の情報)
出馬表の取込み時に使用するテーブル群です。
出馬表取込み時はレース結果ヘッダーワーク、レース予定_出馬表ワークの2テーブルにだけデータを書き込みます。
AIによる予測を行うとき、出馬表ワーク(つまり、競走馬)に対し、AIの予測結果が紐付きます。
AIの機械学習アルゴリズムにより、どの予測用ワークテーブルに予測結果が書き込まれるかが決まります。
発走結果取込み(レース結果取込み)
レース結果の取込み時に使用するテーブル群です。
レース結果をトランザクションテーブルやマスタに書き込む前の中間データで、レース結果のヘッダ情報、明細情報、払戻金、距離ごとの通過タイム、ラップタイム、コーナー通過順位を、一度ワークテーブルに書き込みます。
その後、トランザクションテーブルに反映されていないデータだけを書き込みます。
血統情報作成
とあるサイトから読み取った血統情報をシステムに登録させる前に、中間情報として蓄積するテーブル群です。
まとめて書き込んだ方が処理性能が出るので、一時的に蓄積するためにワークテーブルを作っています。
学習モデル作成
AIモデル作成時に使用するテーブル群です。
AIモデルを作るとき、大量の学習データを読み込ませて学習させます。
学習し終わったデータはAIモデルとして物理ファイルが作成されます。
その時、作成された物理モデルの情報を一時的に記憶しています。
最終的にはマスターに書き込まれます。
マスター
システム全体で使用されるマスターテーブルです。

コードマスタと採番マスタは汎用的なマスタの位置づけです。
騎手、競走馬、調教師はそれぞれマスタ化。
系統マスタは、サンデーサイレンス系、ヘイルトゥリーズン系といった系統を管理するマスタです。
血統は5世代までを管理しています。
本来のテーブル設計としては、親子関係を持った自己参照型のテーブルが望ましいですが、血統は一度データを作ってしまえば変わらないという性質なので、あえて正規化せず、使いやすいように5世代分を横持ちデータとして定義しています。
サロゲートキー用のテーブルと、内部コード用のテーブルの2つがあります。
3世代のテーブルは1つありますが、旧仕様の名残で、現在は使っていません。
学習モデル
AIモデルの情報と、その評価情報や特徴量毎の重要度を管理するテーブル群。

AIモデル1つにつき、予測精度の評価結果や特徴量毎の重要度の情報が複数付くテーブル構成です。
AIモデル作成過程で、(当時の自身のスキルで)必要な特徴量を一度全て作成しています。
そのうえで、特徴量選択によって削除された特徴量を記憶しているテーブルが削除特徴量のテーブルです。
削除する特徴量は何か?を管理することで特徴量の設定が汎用化でき、AIモデル作成時でも、予測時でも同じフォーマットでデータが使えることになります。
トランザクションデータ
システムが管理するレース結果のデータ群です。
属性が多いテーブルは、本来は正規化して分割することが望ましいですが、発生データ量は10年使ってもたったの数十万件程度と見積もっており少なめなので、あえて正規化せず、使いやすい形式で設計しています。
ここからがこのデータモデルの本丸です!
ここから先は
¥ 300
この記事が気に入ったらチップで応援してみませんか?