Amazon ConnectとAmazon Transcribeの組み合わせ

こんにちは。
今回は、前回までに作ったAmazon Connectのフローと、Amazon Transcribeを組み合わせて、Amazon Connectでの通話内容をテキスト化してみようと思います。
Amazon Transcribeとは
Amazon Transcribeは、AWSが提供する音声文字起こしサービスです。ユーザが用意した音声ファイルを、自動でテキスト化してくれます。
基本的な処理の流れとしては、まず音声ファイルをS3(AWSが提供するオブジェクトストレージサービス)にアップロードします。その後Amazon TranscribeでJOBを作成し、アップロードした音声ファイルの文字起こしを行います。
Amazon Transcribeの詳しいサービス内容は、公式サイトをご覧ください。
Amazon Connectでの通話内容をテキスト化
それではAmazon Connectでの通話内容を、Amazon Transcribeを使ってテキスト化していきます。
今回の処理の流れはこんな感じです。
・Amazon Connectで通話終了→S3に通話内容アップロード
・S3にアップロードされたのをトリガーにLambda処理開始
・LambdaでAmazon TranscribeのJOBを作成する
・通話内容をテキスト化
Amazon S3(Amazon Simple Storage Service)というストレージサービスを使います。Amazon Connectではあらかじめ設定をしておくと、通話内容が記録された音声ファイルを自動的にS3にアップロードしてくれます。
※通話内容を自動で記録するためには、「記録と分析の動作を設定する」ブロックを問い合わせフローに配置する必要があります。「エントリポイント」ブロックのすぐ後ろに配置し、通話記録設定をオンにする必要があります。
例)エージェント(オペレータ)と顧客両方の通話内容を記録する場合
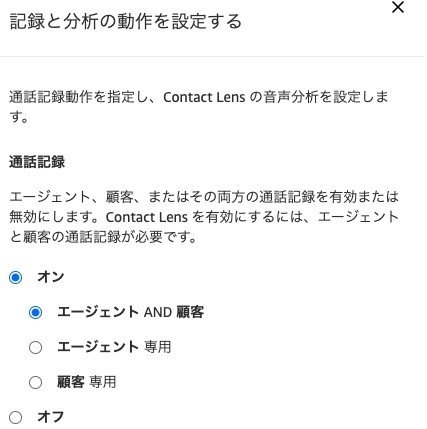
このように設定しておけば、通話終了後に通話内容(エージェントと顧客)がS3にアップロードされます。自分の場合、「connect」から始まる名前のパケットが自動作成され、その中に日付別に通話内容の音声ファイルが保存されていました。
この音声ファイルのアップロードをトリガーに、テキスト化までの処理を行うという流れです。
LambdaとS3の連携設定
S3をトリガーにLambdaを起動させる設定をします。
Lambdaで新しく関数を作成します(言語はNode.js)。
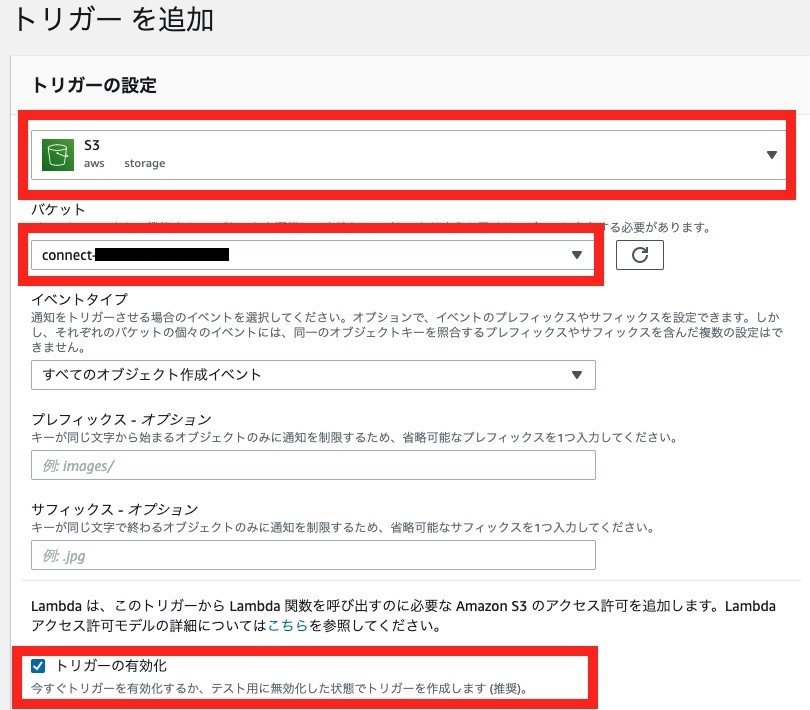
関数が作成できたら、次のような画面が出てくるので、「トリガーを追加」を選択します。

そしてトリガーの設定を「S3」で選択し、パケットで通話記録が保存されているパケットを選択します。「トリガーの有効化」にチェックを入れ、以下のようになっていれば大丈夫です。
Transcribeへのアクセス
次にLambdaからTranscribeにアクセスする事前設定を行います。
Lambda関数編集画面の「アクセス権限」タブを選択し、ロール名をクリックしてロールの編集画面を開きます。
「ポリシーをアタッチします」と書かれた青いボタンを押すと、アクセス権限追加の設定画面が開かれます。「AmazonTranscribeFullAccess」をチェックし、「ポリシーのアタッチ」を押してアクセス権限を追加します。

「AmazonTranscribeFullAccess」が追加されているのを確認できればOKです。
Lambda設定
それでは、Lambdaにコードを書いていきましょう。ここまで出来れば設定は完了です。
const AWS = require('aws-sdk');
const transcribeservice = new AWS.TranscribeService({apiVersion: '2017-10-26'});
exports.handler = async (event, context) => {
const Bucket = event.Records[0].s3.bucket.name
const ObjKey = event.Records[0].s3.object.key
const FilePath = "https://s3-ap-northeast-1.amazonaws.com/" + Bucket + '/' + ObjKey
const FileType = ObjKey.split(".")[1]
const jobName = context.awsRequestId
console.log('BucketName : ' + Bucket);
console.log('ObjKey : ' + ObjKey);
console.log('FilePath : ' + FilePath);
console.log(FileType)
const params = {
LanguageCode: "ja-JP",
Media: {
MediaFileUri: FilePath
},
TranscriptionJobName: jobName,
MediaFormat: FileType,
};
try{
const response = await transcribeservice.startTranscriptionJob(params).promise()
console.log(response)
return response
}catch(error){
console.log(error)
}
};動きを確認
実際にAmazon Connectで通話をし、Transcribeが動いているか確認しましょう。問題なく設定できていれば、このように通話終了後にTranscribeに新規jobが追加されます。

StatusがCompleteになったら完了です。テキスト化出来ているか確認してみてください。
まとめ
今回は、S3に音声ファイルアップロード→Lambda起動→Transcribeでテキスト化、と言う流れで通話内容のテキスト化を行いました。
今回はテキスト化して終わりでしたが、テキスト化した内容を別のS3のパケットに保存して、それをトリガーにチャットアプリで通話内容が従業員に通知される、みたいな仕組みも作れたら良いですね。
今回も最後まで読んでいただきありがとうございました。