
Django×Tweepy_テンプレートに渡すコンテキスト変数はリスト形式でなければならない #124日目

tweepyを活用したアプリ作りをしていて、以下のようなグラフを作成しました。

グラフの作成ついてはこちらをご参照ください。
このグラフを見ると次に気になるのが、3/12の週はいいね&リツイートがとても多かったですが、これはどういう内容のツイートだったのか、という点です。
これを解決するために以下の機能を実装しました。
モデルから特定条件のレコードのみ取得
対象期間のツイートを「いいね数」でランキング化
順番に解説させていただきます。
ただビュー全体は少し長いので該当部分だけ抜粋し、最後に全体を記載させていただきます。
モデルから特定条件のレコードのみ取得
前提として、グラフと一緒にその時にバズッたツイートを表示したいので、グラフを作成するための「TweetAnalysis(FormView)」の中に定義しています。
そしてこのビューでは「AnalysisForm」から分析用のキーワードと対象期間(開始日と終了日)を受け取っています。この条件に合致するようにモデルからレコードを抽出しているのが以下の部分です。
[views.py]
class TweetAnalysis(FormView):
form_class = AnalysisForm
template_name = 'tweepy_test/twitter_analysis.html'
def form_valid(self, form):
criteria = form.cleaned_data
keyword = criteria['keyword']
start_day = criteria['start_day']
end_day = criteria['end_day']
# キーワードに完全一致して、かつツイート日時が指定期間のツイートだけを抽出してくる
qs = Tweets.objects.filter(keyword=keyword, created_at__range=[start_day, end_day + timedelta(days=1)])「モデル名.object.filter(フィールド名='条件')」といった形でフィルタリングできます。日付の範囲指定は「フィールド名__range=[開始日, 終了日]」で可能です。ただ、この終了日の1日前までしか抽出されないので、例えば3/14までのデータが欲しいのであれば3/15と入力する必要があります。Pythonではよくある設定ですね。ここではtimedeltaを使って1日足しています。
対象期間のツイートを「いいね数」でランキング化
ちなみに、時短のため変数名は超適当なのでご容赦ください。。笑
抽出してきたレコードのうち、いいね数、ユーザー名、ツイート内容だけを使います。そしてランキング作成用に空のリスト(good_ranking)を作り、そこに順次インサートしていく形です。
ここで各ツイートの「いいね数」を1番目に格納しています。これはランキング化のためにsortするとき、1番目の要素が最初のキーになるのでこの順番にしました。2番目にはテンプレートに表示するための「いいね数&ユーザー名」を、3番目には今回の本命であるツイート内容を格納しています。
そしてtop_tweetという名前でテンプレートに渡す用のリストを作っているところがポイントです。リスト型にしておかないとテンプレート側で扱うことができませんでした。
[views.py]
class TweetAnalysis(FormView):
form_class = AnalysisForm
template_name = 'tweepy_test/twitter_analysis.html'
def form_valid(self, form):
~ 中略 ~
qs = Tweets.objects.filter(keyword=keyword, created_at__range=[start_day, end_day + timedelta(1)])
~ 中略 ~
# いいね数でランキングして上位5つのテキストを表示する
good_ranking = []
for i in range(len(qs)):
tweet_data2 = qs[i]
good_ranking.append([tweet_data2.favorite, "【{0}いいね】 / {1} / {2}".format(tweet_data2.favorite, tweet_data2.user_name, localtime(tweet_data2.created_at).strftime('%Y-%m-%d %H:%M')), tweet_data2.text])
# リストの1番目にある「いいね数」で降順に並び替える=ランキング化
good_ranking.sort(reverse=True)
# テンプレートに渡すのは5つだけにするため新たにリストに格納する(リスト形式にしないとテンプレート側で扱えない)
top_tweet = []
for i in range(5):
top_tweet.append([good_ranking[i][1], good_ranking[i][2]]))
ctxt = self.get_context_data(chart=chart, form=form, top_tweet=top_tweet)
return self.render_to_response(ctxt)
これでテンプレート側で以下のように表示すれば、いいね数トップ5のツイートが表示されます。
[twitter_anaylsis.html]
~ 中略(グラフ表示部分) ~
{% for tweet in top_tweet %}
<div>
{% for ele in tweet %}
<p>
{{ ele }}
</p>
{% endfor %}
-----------------
</div>
{% endfor %}↓こんな感じです。全然整えていないですが、表示したいものは出てきました。
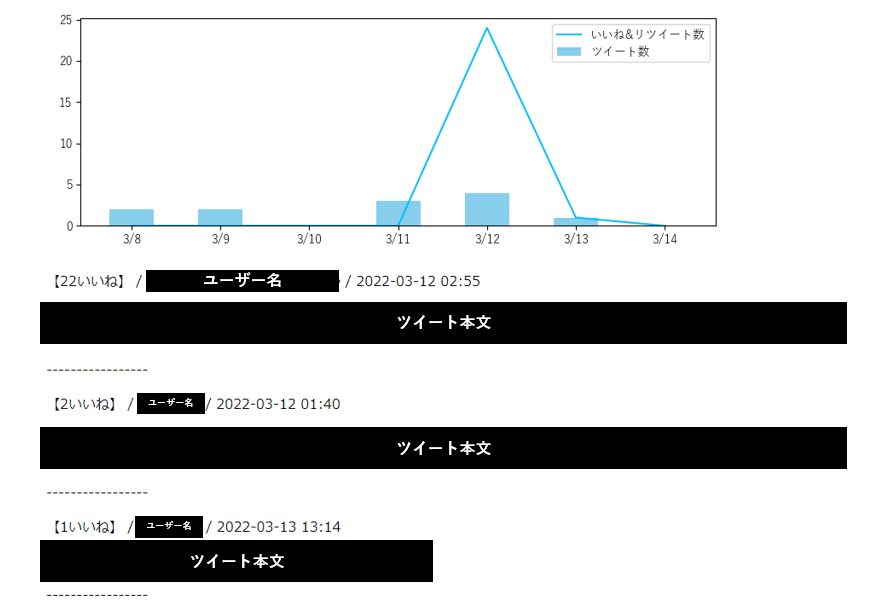
もっといいやり方はある気がしますが。。
一先ずパッと思いついたのがこの方法でした。
↓最後に、分析ページのビューのコード全体です
[views.py]
from django.views.generic import FormView
from .models import Tweets
from .forms import AnalysisForm
from datetime import timedelta
from django.utils.timezone import localtime
import pandas as pd
from .graphs import Plot_Graph
from datetime import timedelta
class TweetAnalysis(FormView):
form_class = AnalysisForm
template_name = 'tweepy_test/twitter_analysis.html'
def form_valid(self, form):
criteria = form.cleaned_data
keyword = criteria['keyword']
start_day = criteria['start_day']
end_day = criteria['end_day']
# キーワードに完全一致したツイートだけを抽出してくる
qs = Tweets.objects.filter(keyword=keyword, created_at__range=[start_day, end_day + timedelta(1)])
# 該当キーワードのツイート情報を一時的に格納し、日付情報などを整理する
dataf = pd.DataFrame({
'tweet_time':[],
'tweet_count':[],
'favorite':[],
'retweet':[],
})
# データフレームに1行ずつインサートしていく(1はツイート数。1行1ツイートのため1としている)
for i in range(len(qs)):
tweet_data = qs[i]
dataf.loc[i] = [localtime(tweet_data.created_at), 1, tweet_data.favorite, tweet_data.retweet]
# ツイート日時の情報を日付に直す
dataf['tweet_time'] = pd.to_datetime(dataf['tweet_time']).dt.date
# グラフに表示する「対象期間の日数」を指定する
N = (end_day - start_day).days + 1
# 指定期間の日付をキーに辞書を作り、ツイート数といいね&リツイート数をリストで格納する → ('日付':(ツイート数, いいね&リツイート数))
tweet_days = {}
for i in range(N):
date = start_day + timedelta(i)
tweet_days[date] = [0, 0]
# tweet_daysの日付に合致するところの[ツイート数, いいね&リツイート数を更新する]
# iterrowsにするとデータフレームを1行ずつ繰り返し処理できるようになる
# (インデックス番号, (tweet_time, tweet_count, favorite, retweet))という構造になる
for data in dataf.iterrows():
if data[1][0] in tweet_days: # 上記のtweet_timeがtweet_daysの中にあるかで条件分岐
# data[1][0]でようやくtweet_timeに行きつく→リストになっているため、そのうち1番目と2番目を更新する
tweet_days[data[1][0]][0] += data[1][1]
tweet_days[data[1][0]][1] += (data[1][2] + data[1][3])
# グラフのx軸とy軸を作る
tweet_date = []
tweet_count = []
favorite_retweet = []
for key, value in tweet_days.items():
value = list(value)
tweet_date.append(key)
tweet_count.append(value[0])
favorite_retweet.append(value[1])
# グラフを作成する関数を呼び出す
chart = Plot_Graph(tweet_date, tweet_count, favorite_retweet)
# いいね数でランキングして上位5つのテキストを表示する
good_ranking = []
for i in range(len(qs)):
tweet_data2 = qs[i]
good_ranking.append([tweet_data2.favorite, "【{0}いいね】 / {1} / {2}".format(tweet_data2.favorite, tweet_data2.user_name, localtime(tweet_data2.created_at).strftime('%Y-%m-%d %H:%M')), tweet_data2.text])
# リストの1番目にある「いいね数」で降順に並び替える=ランキング化
good_ranking.sort(reverse=True)
# テンプレートに渡すのは5つだけにするため新たにリストに格納する(リスト形式にしないとテンプレート側で扱えない)
top_tweet = []
for i in range(5):
top_tweet.append([good_ranking[i][1], good_ranking[i][2]]))
ctxt = self.get_context_data(chart=chart, form=form, top_tweet=top_tweet)
return self.render_to_response(ctxt)ここまでお読みいただきありがとうございました!!