【UTAU】推しにVCCVが実装されたので使ってみた(Lyric Parserクイックスタート)

こんにちは、八歌です。先日、推し(凶街モルテ)のVCCVが配布されました。英語はやはりかっこいいですね。
これまでなんとなくハードルが高いと感じていたVCCVですが、せっかくですし、触って自分なりに使い方をまとめておこうと思います。VCCVが気になっている方の参考になれば幸いです。
VCCVとは
VCCVとは、Czさんが提唱するUTAU向けの録音形式です。CVVCのような仕組みで、特に英語のような連続音化が難しい言語の再現に向いています。公式としては、Czさんによる使い方動画が投稿されています。
これらの関連動画と情報はUTAU.usさんでまとめられています。
日本でも配布例があり、塩釜さんや炭酸水さんが解説されています。
ダウンロードとセットアップ
UTAU、歌詞、メロディ(ustなど)
ここは日本語曲と同じです。UTAUは予めインストールを済ませておきます。歌詞とustは当記事で使用したものを載せます。良ければ参考にどうぞ。
VCCV音源
キャラクターの声のことです。DL後、UTAU.exeと同じ場所のvoiceフォルダーに入れます。(今回は「凶街モルテ」の他に「竜音闇」「平田翔」をお迎えしました)
Lyric Parser
Snowphonesさんによる、ustの歌詞をVCCVに変換するプラグインです。DL後、UTAU.exeと同じ場所のpluginフォルダーに入れます。(恐らくVCCV公式のプラグインではないんですが、それはそれとして、めっちゃ便利でした)
英語を学ぼう
英単語を入力すると、X-SAMPAの発音記号に変換してくれるサイトです。Lyric Parserに新しい単語を登録するときに使います。ダウンロードは不要です。
VCCV English UTAU Lexicon Guide
Czさんが公開されている発音の対応表です。X-SAMPA→VCCVを調べるときに使います。
おま☆かせ2020
まいこさんによる、調声支援プラグインです。DL後、UTAU.exeと同じ場所のpluginフォルダーに入れます。
VCCVの使い方(Lyric Parserの場合)
では実際に使っていきます。曲はイギリスの童謡「Under the spreading chestnut tree(大きな栗の木の下で)」です。
歌詞を入力する
まず、歌詞をコピーするために、原文をテキストなどで表示しておきます。
Under the spreading chestnut tree
There we sit both you and me
Oh how happy we will be
Under the spreading chestnut tree
次に、歌詞の単語を音節ごと、ざっくり言うと、母音ごとに分けて入力します。この作業は、原曲を聞きながら行うと分かりやすいと思います。
ルールは次の通りです。
①1単語を「-」で繋ぎます
初音ミク
→[Ha-][tsu-][ne-][mi-][ku]
Under the spreading chestnut tree
→[Un-][der][the][sprea-][ding][chest-][nut][tree]
②母音の途中で音程が変わるときは「-」を単体で入力し、他の文字は変えません
[chest-][-][nut]→〇
[we][-]→〇
[we-][-]→×
③単語の最初は大文字でも小文字でも大丈夫です


プラグインを使う
使用したいVCCV音源を読み込み、ust先頭のノートの前に、プラグインを動かすための休符を入れます。次に、始音から終音まで選択(Ctrl+W)します。途中から選択する場合は休符を入れなくても良いのですが、プラグインは選択範囲の前に何かしら音符がないと動かないので、全選択(Ctrl+A)は使いません。

選択したら、プラグイン一覧からLyric Parserを開きます。
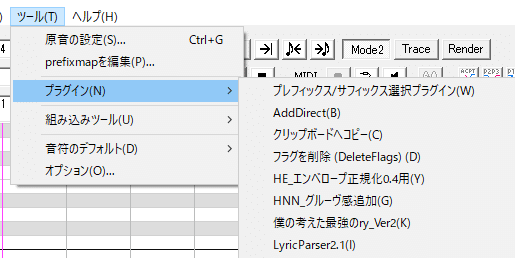
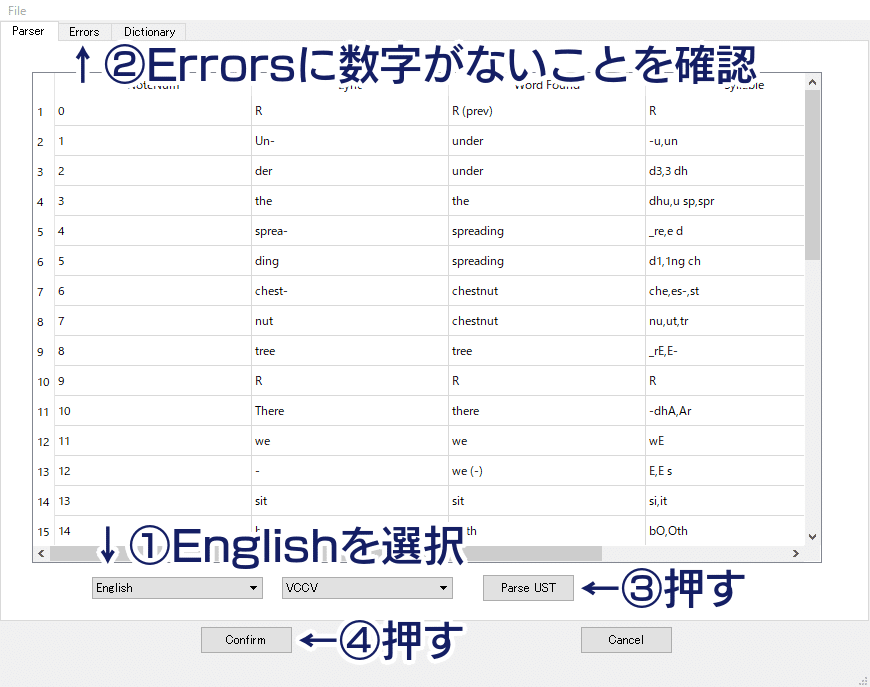
開いたら、画面下の「(Select Language)」から「English」を選びます。すると、歌詞がVCCVの発音記号に変換されます。このとき、プラグイン上の「Errors」に数字が入っていないことを確認します。数字がなければ「Parse UST」→「Confirm」の順に押し、結果を反映します。
ustが変換されたら、そのまま右上の「p2p3」を押してクロスフェードします。

最後に、プラグイン一覧から「おま☆かせ2020」を開きます。画像のようにチェックを入れ、実行します。


できました! 基本的な流れは以上です。
Errorsが出たら
もし音節を「-」で分けているのに、Errorsが出ている場合、考えられる理由は「音節の数が合わない」か「単語が辞書に登録されてない」かです。まず、前者から確認します。
音節の数が合わない
プラグインの一番右にあるタブ「Dictionary」に移ります。ここでは、選択中の辞書で検索と編集ができます。
単語を検索します。一番下の空欄に単語を入力して「Search」を押します。もし画面が変われば、単語は登録されているものの、音節の数が合わないために変換できなかったという意味です。

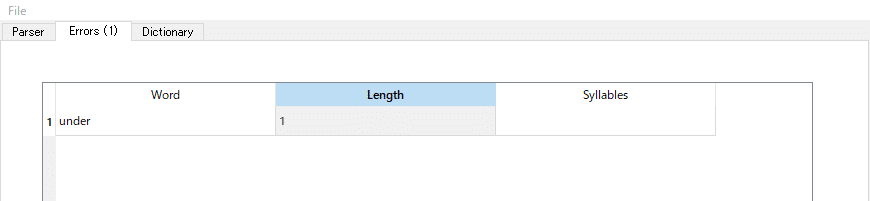
DictionaryとErrorsを比較してみます。見るのは「Length」です。画像では、Dictionaryが2、Errorsが1になっています。これは「本来2音節で入力するところを、1音節で入力している」という意味です。この場合「Cancel」からプラグインを閉じて、音節数が合うようにustを修正します。再びLyric Parserを起動してEnglishを選び、ErrorsになっていなければOKです。ちなみに、伸ばす音に使う単体の「-」は音節数に含まれません。メロディーが変わってしまう場合はこちらを使います。
辞書に単語が登録されていない
もし単語を検索して何も出なければ、辞書に登録されていないということです。この場合、発音記号を調べて登録します。
発音記号を調べる
まず、発音記号を調べます。変換サイト「英語を学ぼう」さんを開き、単語をX-SAMPAに変換します。例えば「chestnut」と入力すると「tS"estn%Vt」と出ました。"と%はアクセント記号なので、登録では使いません。そのため、結果は「tSestnVt」になります。
X-SAMPA→VCCVの検索
後はCzさんの対応表を見ながらVCCVに置き換える……でも良いのですが、個人的にはExcelを使うと探しやすかったので、この方法をまとめます。私はディスクトップ版を使っていますが、無料のアプリ版(Android&iOS)やweb版からもこの機能は使えます。
①セットアップ
まず、VCCV English UTAU Lexicon Guide(Czさんが公開されている対応表)を用意します。
パソコンのGoogleChromeから上記リンクをクリックし、「ファイル→ダウンロード→Microsoft Excel(.xlsx)」でダウンロードします。

ダウンロードしたファイルをExcelで開きます。

Excelで開いたら、空いているセルに発音の種類(VOWELS、CCV、CV、VCC)を入力します。余裕があれば、色分けしておくと見やすくなります。終わったら、文字がある全てのセルを選択します。その状態で「データ」→「フィルター」をクリックします。すると1番上に「▼」が付きます。セットアップは以上です。


②検索
「X-SAMPA」の「▼」ボタンをクリックします。検索欄に、調べた発音記号を検索結果が表示されなくなるまで入力します。その一つ前の状態の発音(tSeで該当しないならtS)にチェックを入れ、反映ボタン(OK/適用/完了)を押します。


反映すると、一覧が出てくるので、最も近いものを選びます。

例えば上の画像のように「tS」にあたる発音は2種類あります。CV(子音→母音)と、VCC(母音→子音子音)です。今回tSの前に母音は無いので、VCCではなく、CVのchだと分かります。こうして調べていくと「tSestnVt」は「ch/e/s/t/n/u/t」になることが分かりました。
単語を登録
Lyric Parserに単語を登録します。登録はプラグイン内で行う方法と、テキストを直接更新する方法があります。今回は後者を使います。
もしLyric Parserを開いているなら「Cancel」で閉じ、プラグイン選択画面から、プラグインフォルダーを開きます。

開いたフォルダーから「Lyric Parser」→「dictionary」と開くと、English.txtがありますので、これを開きます。念のため、English.txtを複製&改名してバックアップをとっておくと良いと思います。
テキストの一番下に、既に書かれている形式にならって単語を追加します。例えば今回の「chestnut」なら、次のように入力しします。
_chestnut: ch(e)st:n(u)t
ルールは次の通りです。
「_単語: 1音節目:2音節目」の順で書きます。単語以外はVCCVの発音記号で書きます。
音節は「:」で区切ります。
母音は1音節1つ、「( )」で1文字だけ囲みます。例えば1ngなら、(1)ngと書きます。
追加したら、テキストを上書き保存します。UTAUに戻り、プラグインをリロードします。

再びLyric Parserを実行し、Errorsが起きなければOKです。
TIPS
最後にTIPSをまとめます。
発音の長さが合わない
子音速度、もしくは音の長さを変更すると改善される場合があります。この作業はある程度プラグイン側でしてくれるのですが、違和感がある場合は、次のように調節します。
・発音がもたつくor最後まで発音しない→子音速度を上げるか、音の長さを伸ばす
・発音の長さが短いor関係ない発音が再生される→子音速度を下げるか、音の長さを縮める
この作業に関しては、Czさんの使い方動画で触れられていたり、その動画の説明欄でサンプルustが配布されていたりするので、参考になります。
日本語で歌ってほしい
先程はEnglish.txtを辞書として使いましたが、このときJapanese.txtにすると、日本語で歌わせることができます。余談ですが、母音が少し使いやすくなる(かもしれない)素材を作りましたので、良ければ参考にどうぞ。
その他
その他の遭遇したケースです。長いので、関係なさそうな所は読まなくて大丈夫です。
・音源に存在しない音素へ変換される→辞書に問題があるか、収録されていない場合がある
・スペルミスがないのに「English」を選択しても変換されない→黒い画面に注目、稀に空のoto.iniに問題があると動かないことがある、あと読み込めなかったフォルダーとか、何かあると黒い画面に書かれていることがある
・CVの子音が聞こえづらい→直前の音が短すぎて先行発声が十分に再生されていない場合がある、Lyric ParserのREADME.txt曰く、ノート長は読み込まれた音源に合わせて分割されるらしい
・発音がイメージと違う→音の長さや子音速度を変える、発音が似てそうな音素に差し替える、音素を省略する、一部の尾子音を目立たなくしてみるetc……プラグインはあくまで最初の労力を減らすものなので、後は聞こえ方を優先して修正する
・もっと楽に歌詞入力したい→歌詞入力はVOCALOIDと同じ仕様、英語ボカロを持っていれば、聞きながら単語を入力したり、自動で音節ごとに分けたりしてくれる
・登録する単語の発音を聞きたい→Google翻訳か他の合成音声で聞こう
・Lyric Parserについてもっと知りたい→README.txtを自動翻訳して読もう、てかそうじゃなくてもちゃんと読もう、今回触れなかった機能も沢山あるよ
・X-SAMPAに変換できない→Synthesizer Vの英語がほぼArpasingのため、Arpasing用の音素表が使える、英語の歌声データベースは(記号出すだけなら何でもいいけど、無料で聞ける発音の参考が欲しいなら)AIって書いてないほうのEleanor Forteがおすすめ
とりあえずここまで調べておけば大丈夫そう……かな? 実際に調声してみると新しいことも見えてきそうですが、今回はここまでとします。良いUTAUライフを!
八歌