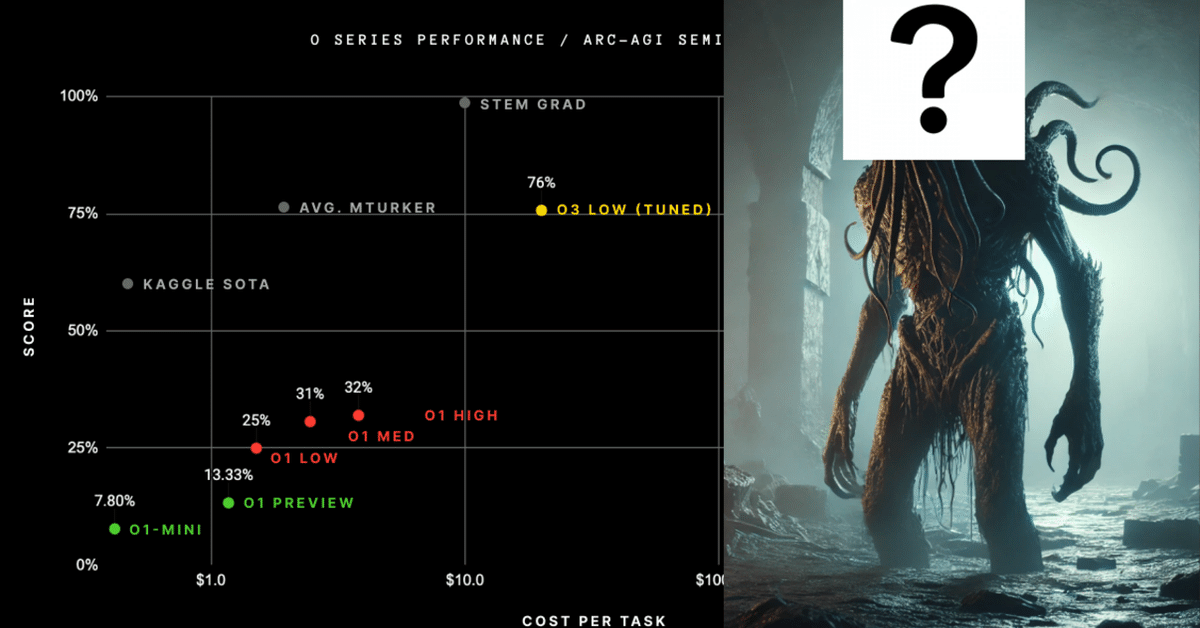
OpenAI o3は,人間とは全く異質の汎用知能である危険性【東大解説】

追記1:チップをお送りいただいたかたがた,ありがとうございます!
追記2:
このような話題に興味があるかたへ…関連するコミュニティはこちら↓
非専門家向け:https://discord.gg/shingiyurariteisaba-1125096939344625684
専門家向け(分野問わず):https://www.aialign.net/contact
OpenAI o3は,人間とは全く異質の汎用知能である恐れがある.
競技プログラミングCodeforcesで,人類に混じってo3が全世界175位となったのはすさまじい.
ガチの数学者たちが全力で作ったベンチマークFrontierMathで,o1-previewでも2%しか正解しなかったところが,o3では25%も正解してしまった.
しかし,一番の問題はそこではない.
全く別次元のところにある.
ARC-AGIというベンチマークだ.
o1で25%だったところを,o3で75.7%と大幅に更新したが,これはただ点数が上がったという話では終わらないのだ.
ARC-AGIの公式アナウンスやその他様々な情報源を元に,ARC-AGIに取り組んだ経験のある東大在籍の研究者の卵が解説する.
ARC-AGIとは
大雑把に言うと,人間には簡単だが,従来のAIが無理矢理解くことはほぼ不可能なベンチマークである.
人間のIQテストをイメージしてもらうといいかもしれない.
いくつかの図形が並んでいて,法則を見つけよ,というものは見かけたことがあるだろう.
ARC-AGIはあれを手本にして作られている.
例えば↓こんな感じだ.
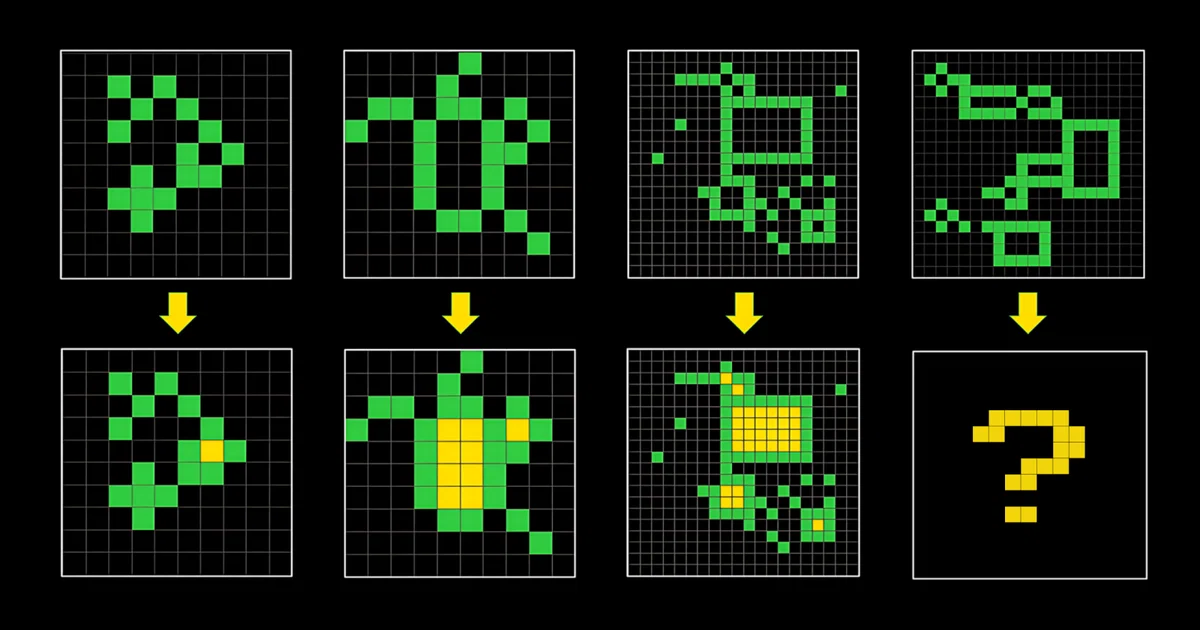
上下でペアになっており,ある法則にしたがって,上の図形が下の図形に変換されている.
今回の問題の場合は,「緑で囲まれた部分が黄色で塗りつぶされる」だ.
見ての通り,まぁ簡単な問題だ.
しかしこれが,従来のAIにはとても難しかったのである.
なぜか?
ARC-AGIが難しい理由
AIにとって難しい要因はいくつかある.
ARC-AGIが提案された論文から一部抜粋する.
まず,多様な未知のタスクに適応できることが求められる.
各タスクで独自の法則が適用されているためだ.
先行研究によっては,open-world problemという表現も使われているくらいである.
確かに,タスクが特定領域に限定されておらず,マス目を使って表現できれば何でもありのため,実世界のうちかなりの物事や現象を扱うことができる.
それから,各タスクが独自の法則であるにも関わらず,ヒントとなるデータ例が少ない.
もちろん人間はいくつかだけで十分だが,典型的なAIの学習方法ではご存知の通り大量のデータが必要となる.
御託ばかりでもアレなので,他のベンチマークとも難易度を比較しておこう.
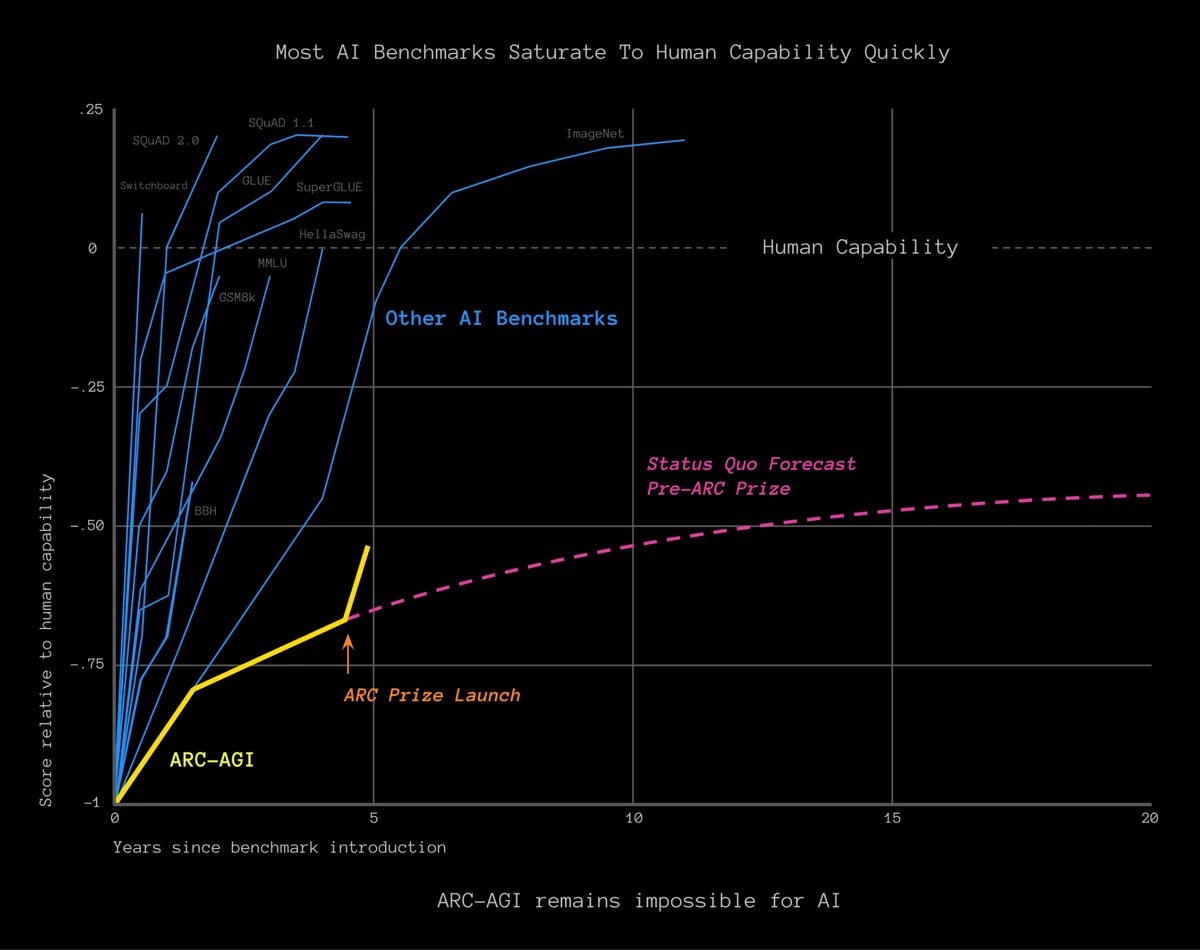
この図は,様々なベンチマークがどのくらい早く攻略されたか,を示している.
横軸が年数で,縦軸がベンチマークのスコア(SotAの推移)だ.
黄色のARC-AGIは明らかに伸びが遅い.
次に遅いImageNetについては,そもそも当時は今ほどAIの注目が集まっていなかったという背景もある.
一方でARC-AGIは提唱が2019年と新しいにも関わらず,ImageNetよりも攻略に時間がかかっている.
また後でも説明するが,ARC-AGIを解かせるのは本当に難しいのだ.
o3が見せたARC-AGIの結果
ARC-AGIのベンチマークの内容を踏まえた上で,結果を検討していく.
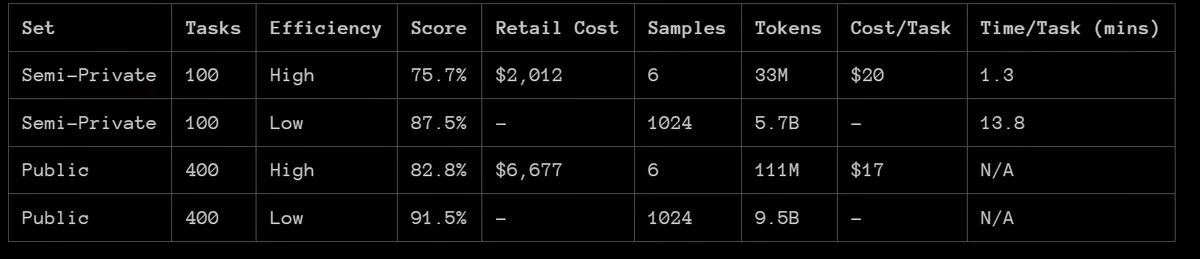
結果の表は4行ある.
Publicは公開データセットであり,o3が既に学習してしまっている可能性がある.
Semi-Privateが実質的な非公開セットと思えばよい.
(なおSemiの接頭辞は,多少の流出を前提として設計しているからである.
前提として,少し前に行われていたARC-AGIのKaggleコンペティションのPrivateセットはKaggle内で完結するため流出しないが,
Semi-Privateセットは,ARC Prize側で評価するものの,APIを使う前提のため,OpenAIなどAPIを提供する企業には流出してしまう.データセットの定期的な更新はされるそうである)
Semi-Privateのうち,Samplesが1024のほうは,(推論中に内部で)数を打ちまくっているだけなので,スコアは上がってもおかしくない.
より重要なのは6のほう,すなわち1行目だ.
この1行目の75.7%はどの程度のものなのか.
平均的な人間は73.3~77.2%程度という調査結果がある.
すなわち人間相当に,未知タスクに対応できると考えていい.
(もう少し語ることもできるが枝葉なので省略.反響次第では追記するかもしれない)
(先ほどもARC-AGIの難しさについて述べたが)この数字は本当にすごいのだ.
これまでARC-AGIに対しては様々な手法が試されてきた.
LLMプロンプティング,マルチモーダル入力,ファインチューニング,メタエージェント探索,データ合成,Vision Transformer派生,分割統治法の派生,MCTS派生,複数レベルでの推論,潜在関数推論,PPOによる強化学習,遺伝アルゴリズム,進化的アルゴリズム,抽象化グラフ,エキスパートシステム,リレーショナル表現,DreamCoder派生,ドメイン固有言語,テスト時計算,テスト時訓練などだ.
少し変わったところでは,Language of Thought Hypothesisやカオス理論に基づくアプローチなどもあった.
総額一億円の賞金と共にこれら以上の試行がなされてきたが,これまではせいぜい50%超えだった.
生のo1はもっとひどく,25%であった.
それがo3の場合は,一気に75%超を達成してしまったのだ.
自分も,既出ではない真新しいアイディアがあったため検討したことがある.
しかしアイディアはシンプルでも実装が困難(仕様が複雑になるか,不安定になり調整が大変かの二択)であるのと,実行コスト(時間も費用も)がルール制限を超えることが想定され,断念した.
実際の手法がどうであれ,やり遂げたo3開発者陣はあまりにすごい.
定性的な結果
一方で興味深いのは,簡単な問題に失敗することもあるということだ.
例えば以下のような問題である.
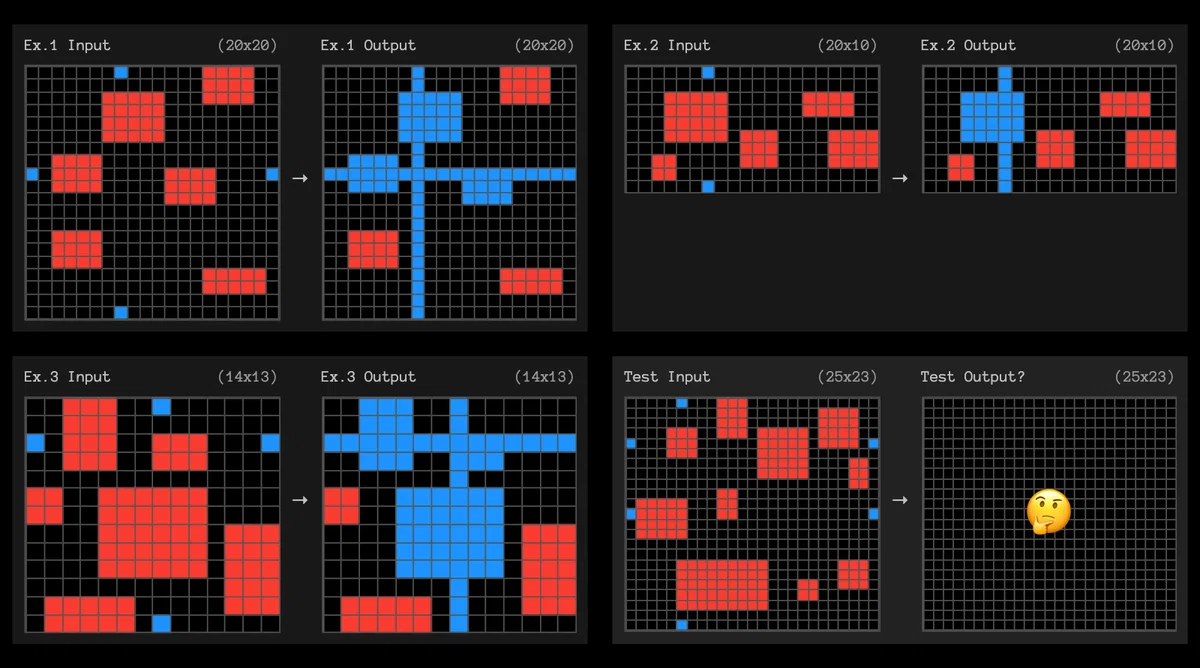
この法則は,対になる青点同士を青線で結び,線と被った長方形を青にする,というものである.
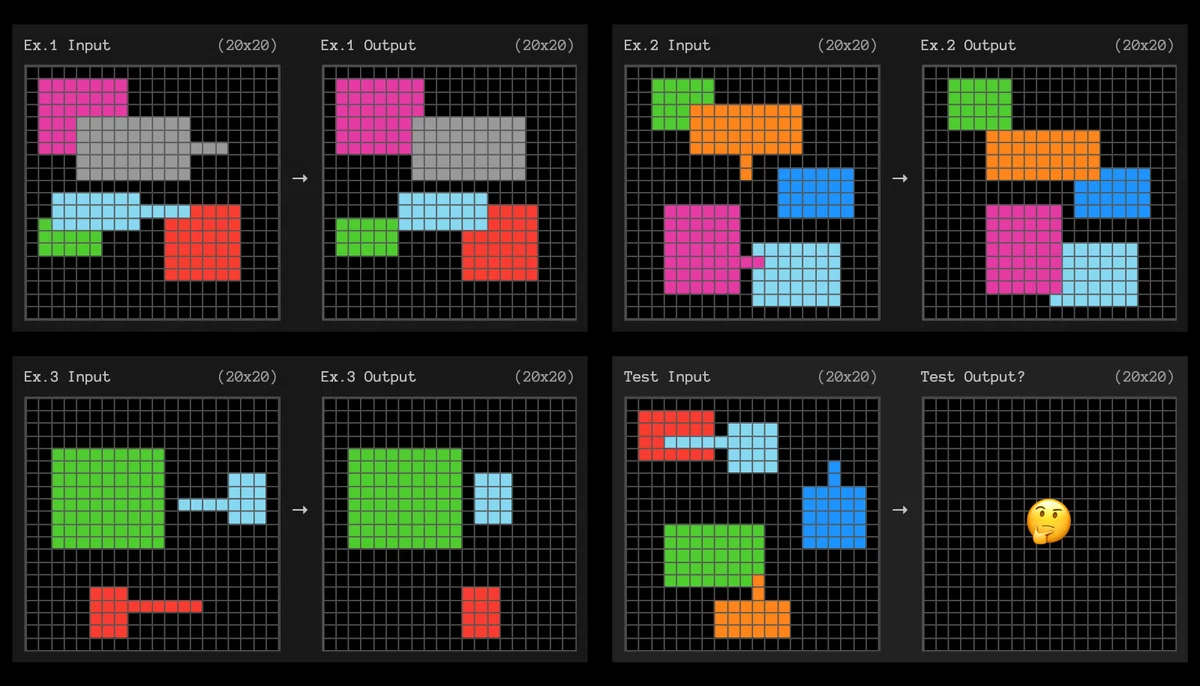
こちらは,長方形から伸びている線の長さ分,長方形を移動させるというもの.

これは上に示された色の順番に,正方形を重ねていくというものだ.
(なお,その他の失敗例は,KaggleグランドマスターのMikel Bober-Irizar氏が紹介している)
一方で,より難しいが,o3が解けている問題は,例えば以下のようなものがある.

これは,すぐにわかる人は少ないと思う.
答えは,同じ色で繋がっているマスが2マス以下の場合に黄緑色に変える,である.
これはアナウンス記事内では紹介されていないが,自分が確認する限り,o3の提出答案で低コストなほうでも高コストなほうでも正解しているようである.
こう見ると確かに,先に挙げたような比較的簡単な問題のほうが解けていないのは興味深い.
(得手不得手はあるので,人によっては難しく感じるかもしれない)
結果の洞察
ここから考えられる可能性は主に2パターンある.
a) o3はあくまで汎用的な知能ではない,計算量でカバーしているのみ
b) o3は汎用的な知能だが,異質すぎるので人間には理解できない
常識的に考えれば (a) だが,本当にそうなのだろうか.
何か見落としていないだろうか.
また,そもそもo3の仕組みについて,
i) o3は言語(トークン/埋込/潜在)空間の推論や探索をしている(もちろんマルチモーダルも含むが)
ii) o3は世界モデルやその他言語以外に関わるモデルを統合している
という可能性がある.
ARC-AGI領域の専門家の見解
ここで少し,ARC-AGIに関連の深い人々の意見を見てみよう.
まずARC-AGIの考案者であるFrançois Chollet氏は,(a) かつ (i) という王道な立場だ(詳細は後述).
今年のKaggleコンペティションでも非公式に1位を取っていた(ソースコードの公開を拒んだためスコアが無効となった)MindsAIのJack Cole氏,Mohamed Osman氏,Michael Hodel氏は,現状では明言していない.
(コンペではAPI使用不可のため)o3が直接競合となるレギュレーションのARC-AGI-Pubで元1位であったJeremy Berman氏は,多くのベースLLMを検証モデルで間引いているという意見であり,含意としては (a) かつ (i) となるだろう.
元2位のKevin Ellis氏,Ekin Akyürek氏,Mehul Damani氏,Linlu Qiu氏,Han Guo氏,Jacob Andreas氏は,今のところ明言なし.Yoon Kim氏はtwitterアカウントが見当たらなかった.
元3位であり,かつARC-AGI-Pub設立のきっかけともなったRyan Greenblatt氏も現状では見解はなさそうであった.
日本では,アラヤやALIGNに所属するIppei Fujisawa氏がコメントを出している.
氏はむしろ自律的な創造性を重視しているようだが,上の選択肢に当てはめるなら,やはり (a) かつ (i) ということになるだろう.
実情としても,OpenAIは,Genie2などを持つDeepMindと比べて世界モデルを本格的に手掛けているかも定かではない.
投資先のFigure AIがロボティクスを扱っているが,外部である以上やはり不明瞭である.
と考えると,(i) は妥当な線だろう.
(François Chollet氏も指摘している通り,1問解くごとに大量のトークンを消費しているのも合点がいく)
そしてこれは,(a) らしさを補強する前提だ.
汎用知能の可能性
だがしかし,(i) だとしても,(b) ではないと本当に言い切れるのだろうか.
いささかスペキュラティブなことを考えてみる.
10年以上前から汎用人工知能の危険性について指摘していた哲学者のNick Bostrom氏やEliezer Yudkowsky氏によれば,人類は,知能というものに対して歪んだ認識を持っている可能性がある.

我々はしばしば,村人とアインシュタインを知能の両極端と考えがちだ.
しかし実際はその二者より,チンパンジーやネズミのほうがもっとずっと知的には距離があるかもしれない.
この落とし穴は,人間視点で,人間の常識で考えてしまうことが原因である.
この発想を応用すると,我々が汎用な知能としてイメージしているものも,平均的な人間に囚われている可能性がある.
例えば,タコは腕ごとに神経節があって,半自律的に動く.
このような分散的知能も,汎用知能となり得るかもしれない.
より現実的な話では,目の不自由な人などどうだろうか.
視覚の代わりに,足音の反響や舌を鳴らした時の反響から,部屋の広さや壁までの距離を認識できるようになる場合がある.
もちろん彼らは汎用な知能であるが,世界の認識の仕方が変われば,考え方も変わってくるだろう.
こう考えていくと,もしかすると常識とは全く異なる汎用人工知能も存在し得る気がしてくる.
この方向性で,François Chollet氏の発言を見直してみよう.
彼は,非常に簡単なARC-AGIタスクに失敗しており,AGIではないだろうとしている.
しかし(平均的な人間目線で)簡単なタスクが解けることは,汎用な知能に必須ではない.
o3も,ARC-AGIの一部のタスクは苦手だったが,汎用な知能であるかもしれない.
いやむしろ,ARC-AGIという多様な未知タスクに人間と同程度対応できている時点で,汎用な知能と認めるべきではないのか.
その思考過程がどうであれ,結果は結果と認めるべきだろうし,他の未知タスクにも対応できてしまう可能性が十分あるわけだ.
また,ARC-AGI-2でも賢い人は95%を取り続けられるとの記載がある.その点o3は30%未満と大幅に下がるのでAGIではないのでは,という口調だ.
だがこの場合,平均的な人間のスコアも下がるのではないだろうか.
o3にとって難しいデータセットにするということは,基本的には「賢い人」未満の何かしらの知能が出すスコアを押し下げているはずで,大半の人間も巻き込まれてしまうのではないか.
やはりo3が異質な汎用知能である可能性は低くないように思えてくる.
ここで考えられる反論は,ARC-AGIに特化しているのではないか?ということである.
様々なタスクを包含するとは言え,2次元のマス目であったり,法則の前後の2つで一組だったり,扱えるタスクに制限はある.
これに対しては,他のベンチマークの結果を見ると良い.
詳細は省略するが,特にFrontierMathやCodeforcesに注目すべきだ.
前者は非公開データセットであるし,後者も(o1の時の様子から察するに)おそらくリアルタイムで競技プログラミングに参加しており,実質的な非公開データセットとなるだろう.
非公開ということは学習していないわけであり,言い換えれば,ARC-AGIに特化しているわけではなく,様々な新しいタスクに対応できているということだ.
(もし反響が大きければ,改めて細部の検討を説明するかもしれない)
異質な汎用知能による危険性
特に危険性の観点で考えると,もしo3が汎用知能である可能性が低かったとしても検討しておかねばならない.
例えば「人類が滅亡する可能性が5%あります」と言われた時,「それなら大丈夫そうですね」とはならないだろう.
その低い確率が本当となってしまった場合,要は期待値的な考えに基づけば,少ない確率であってもあまりに危うい.
具体的にどのようなリスクがあるかの一般論については,Existential RisksやAI Alignementなどで調べてみると良い.
異質な汎用知能について特別に注意しなければならないことは,特定の能力が著しく高い(例えばAlphaGoのように)可能性があることだろう.
それによって,何かしら特定のリスクが大幅に前倒しに到来する恐れがある.
どのリスクが前倒しになるかの詳細な検討は,さらなる検証結果が待たれる.
今わかる範囲で何となくSF話をしておくと,
まず今回公開された事実として,未知タスクへの対応は平均の人間程度だが,コーディングや数学については人類トップに肉薄しているということだ.
ロボティクスの現状も合わせると,現実世界より仮想世界のほうが得意ということになるのだろう.
最悪の場合は,自己改善や賢いコンピュータウイルスなどを起点として,インターネットに接続されているあらゆる機器が狙われる恐れがある.
個人はまだいいとして,発電所や水道などのインフラや,場合によっては核兵器・生物兵器の施設も(監視システムやセキュリティアップデートなどの事情により)わずかにインターネットに繋がっている場合があり得る.
このような場所において,従来よりはるかに巧妙な攻撃が行われる可能性を,そろそろ注意し始めなければならないということだ.
まとめると,o3が人間とは全く異質の汎用知能であるかもしれない,と考える価値は十分にあり,もし違ったとしても今後本当に異質な汎用知能(あるいは単に人間相当の汎用知能)が出現した場合に備えることができる.
急いで書いたので,根本的でも小さなことでも,ぜひ気軽にご指摘を.