
【Stable Diffusion 3.5】SD3.5(Stability AI)を使ってみた

Stability AIから待望のStable Diffusionの新しいモデルの発表がありましたので、早速使ってみました。
ダウンロードはHugging Face経由となります。非商用ラインセンスとなります。FLUX.1-devと同じですね。
画像生成はComfyUIで実行することができます。(ComfyUIの説明は省略)
ダウンロード手順
まず、Hugging Faceで以下の2ファイルをダウンロードします。
①sd3.5_large.safetensors
②SD3.5L_example_workflow.json
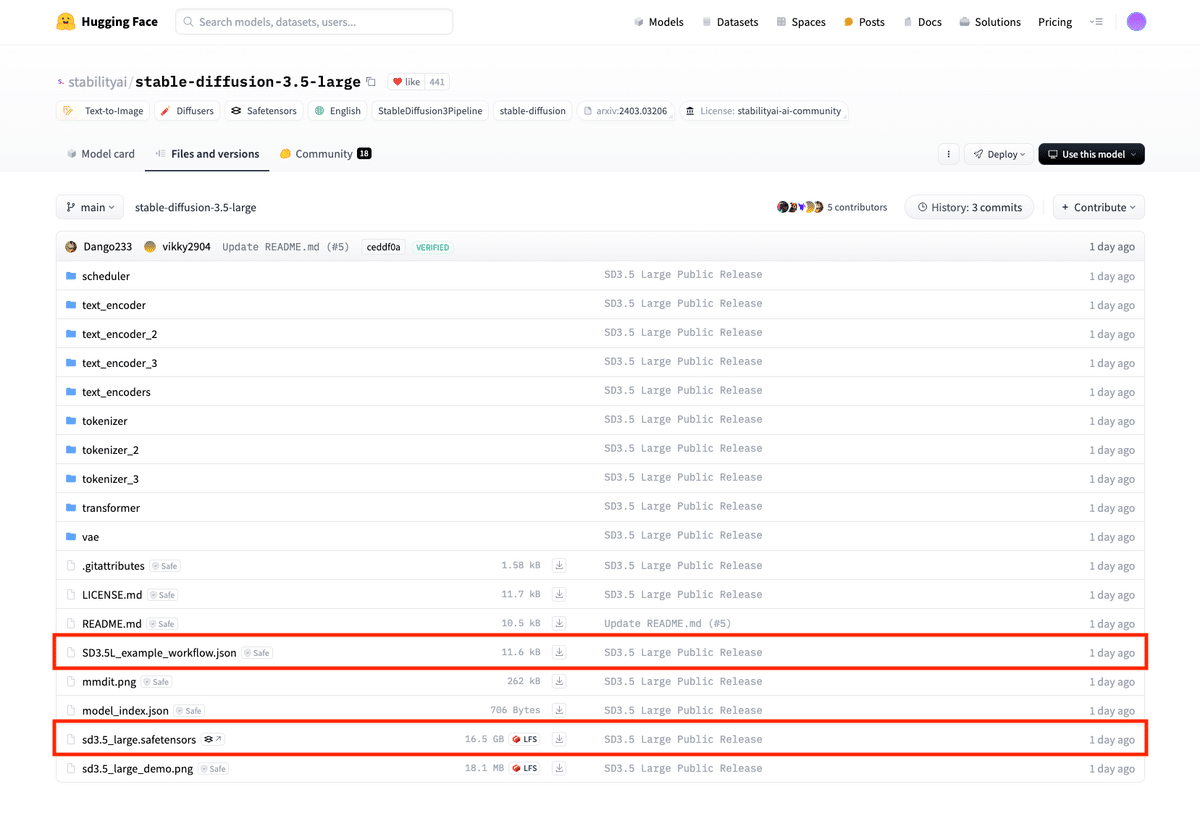
①はComfyUI/models/checkpointsに配置します。

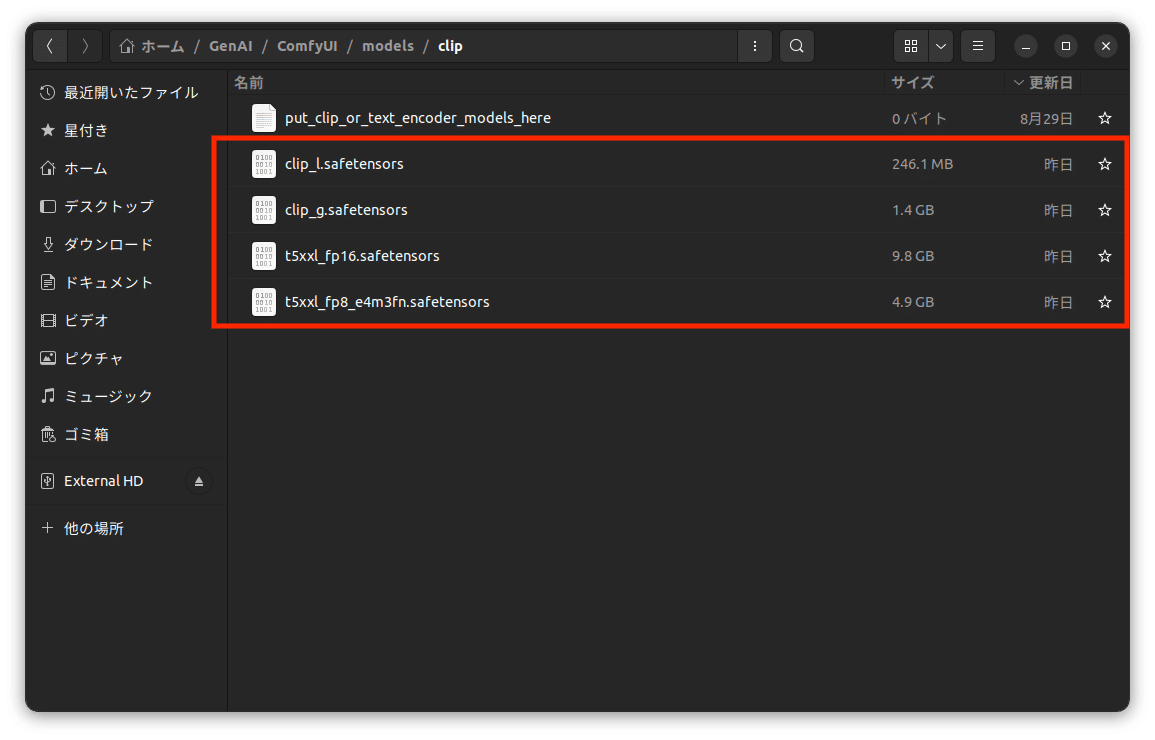
次にCLIPをダウンロードします。
③clip_g.safetensors
④clip_l.safetensors
⑤t5xxl_fp16.safetensors
⑥t5xx|_fp8_e4m3fn.safetensors
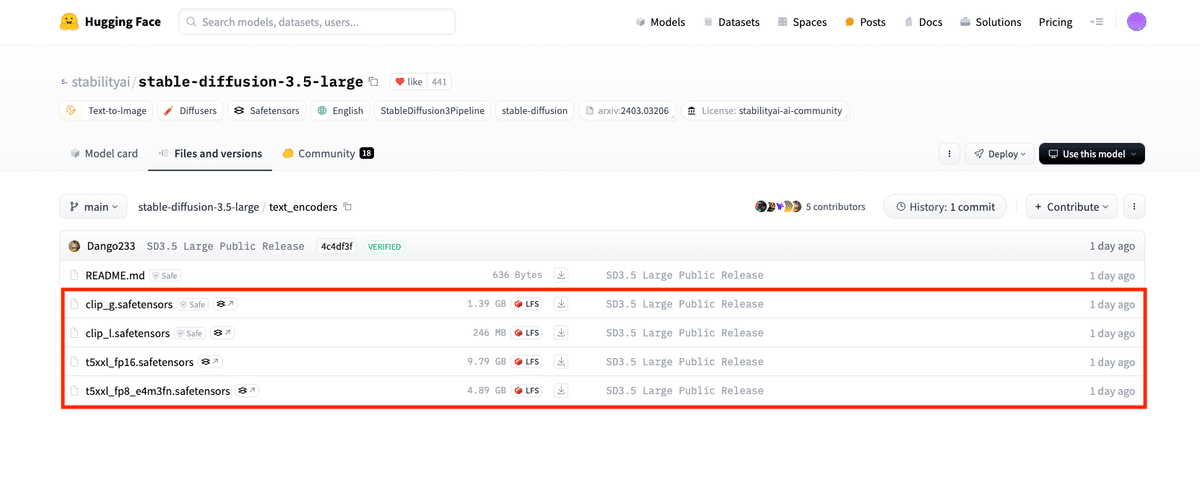
③〜⑥はComfyUI/models/clipに配置します。
実行手順
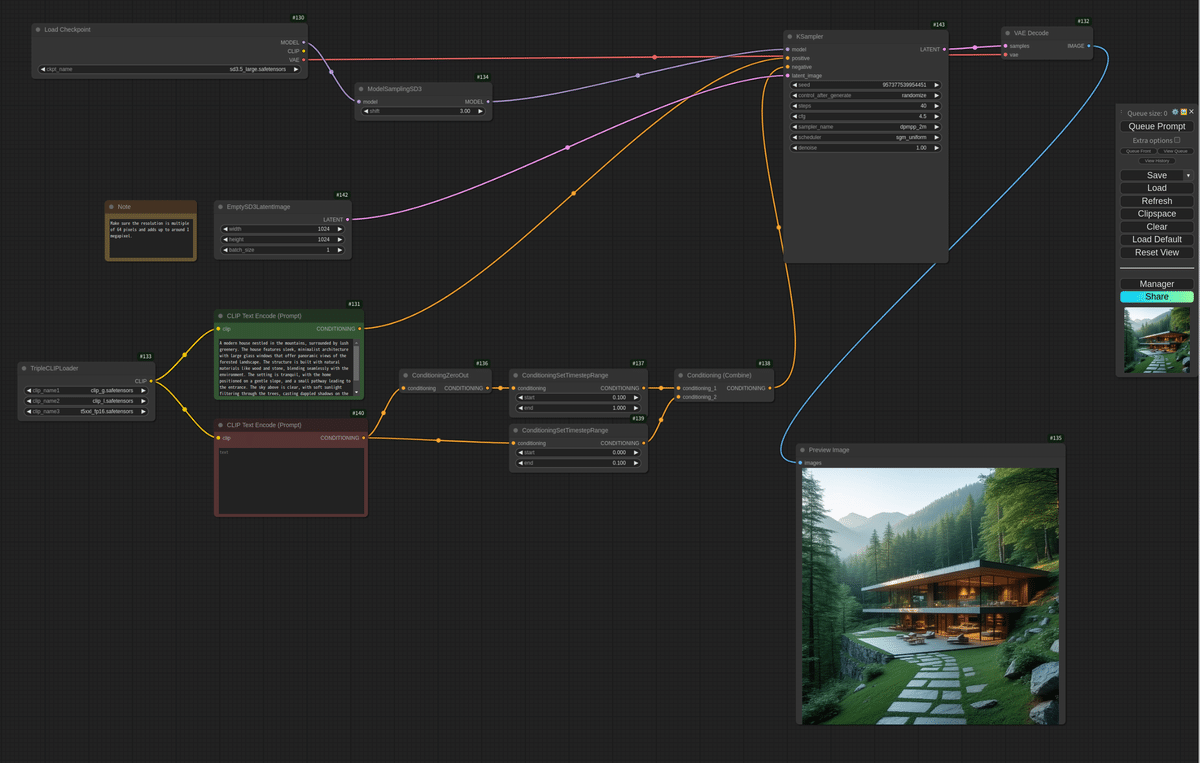
ComfyUIを実行します。右下にある「Load」を押下し②のjsonファイルを選択、ワークフローを開きます。
TripleCLIPLoader(下図の赤枠)で③④と⑤(or⑥)を選択します。
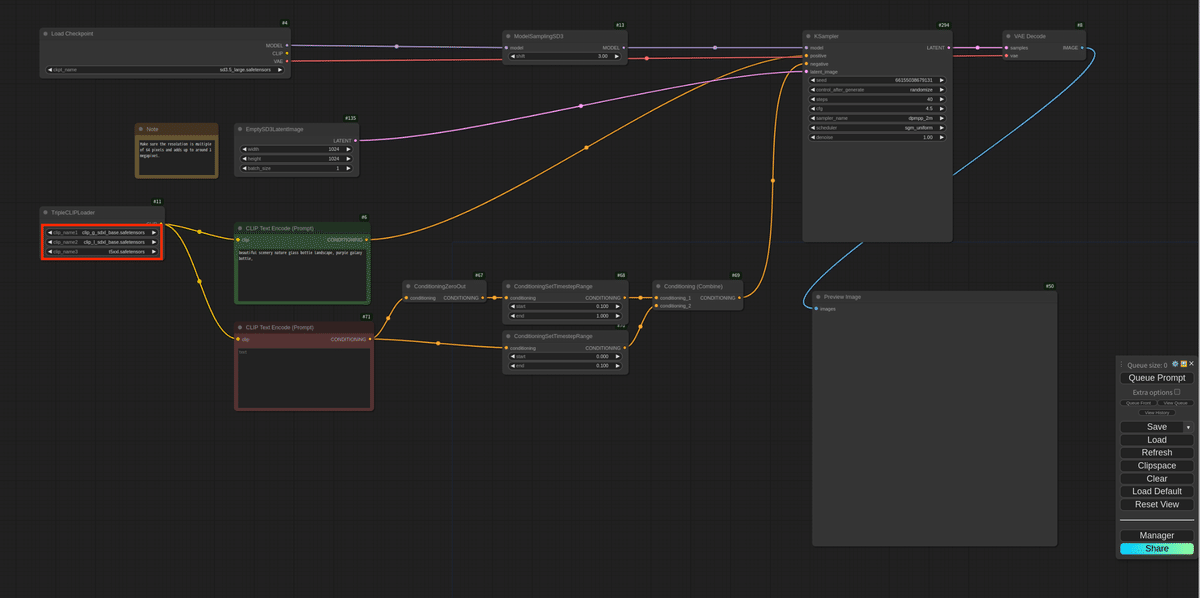
最後にプロンプトを入力し、「Quene Prompt」を押下すれば画像生成ができます。
評価
では、実行結果を評価します。結論としては、flux.1 devより見劣りする印象です。(今後検証することで評価が変わる可能性あり)
以前、Stable Diffusion 1.5(SD1.5)とflux.1 devを比較したので、今回はStable Diffusion 3.5(SD3.5)と3モデルで比較します。
プロンプトは前回と同じ文言を使います。

上記のプロンプトで、512x512(pixcel)で画像生成しました。



実はSD3.5で1024x1024(pixcel)の画像生成をしたときの印象としては、flux.1 devと同様の精度という印象でした。そこで、以前の結果と比べるために512x512(pixcel)で画像生成をしてみると、flux.1 devより見劣りする印象となりました。Pixcelの数値が大きければ大きいほど緻密に画像生成ができるとはいえ、ここまで差が出てしまうとflux.1 devの方が良い印象です。
継続検証していこうと思います。
