ラビットチャレンジ:Stage2実装演習レポート

機械学習の様々な手法(○○回帰モデルなど)を、数学的な背景から紐解いていくというもの。
コード書くのはあくまでも補助的で、まずは数式レベルで各モデルの意味を理解することが重要
線形回帰モデル
ざっくりと言えば直線的なデータの関係から、未知の結果を予測するモデル。最もシンプルな構造は比例関係にあるようなデータ。
求める値=目的変数
影響を与えるデータ=説明変数
として、目的変数を説明変数の線形関数(一次式)で表し、その係数を求めることでモデルを表現する。
y = w0 + w1*x + w2*x + w3*x ・・・・
実際には、方程式を解くように一意の解を求めるのでは無く、すべてのデータに対し予測値(一次式の計算結果)と実際の値(データに含まれる値)の差をとり、最小二乗法によってその差が最も小さくなるように一次式の係数(w)を定める手法をとる。
演習:ボストンハウジングデータを使った住宅価格の予測
sklearnに含まれる初学者の学習用データセットとして有名なボストンハウジングデータを使った住宅価格の予測を試してみる。


手で計算すると、複雑な計算も数行のコードで実現できる。ただ、このままではただの「魔法の箱」になってしまうので、背景となる数学的アプローチを理解しておく必要がある。
非線形回帰モデル
線形回帰モデルにおける一次式を、xの任意の関数Φj(x)に置き替えた式として考える。
y = w0 + w1*Φ1(x) + w2*Φ2(x) + w3*Φ3(x) ・・・・
このとき重要なポイントは、wについては線形のままであるということ。
つまり、係数wについては線形関数であるため、線形回帰モデルと同様の手法で係数wを求めることが出来る。
Φj(x)の代表的なものとしては
多項式関数
Φj(x) = aj0*x^0 + aj1*x^1 + aj2*x^2 + aj3*x^3 + ・・・・
ガウス型既定関数
Φj(x) = exp{-(x-uj)^2/2hj}
などがある。
Φj(x)に複雑な関数を用いると過学習が発生しやすいため、正則化法を利用して表現力を抑止するなどの手法を取り入れる。
ロジスティック回帰モデル
分類モデル( 0 or 1 )に利用するモデル。
シグモイド関数 sig(x) = 1/(1 + exp(-x)) を用いて、目的変数を 0 ( sig(x) < 0.5 ) または 1 ( sig(x) ≧ 0.5 )に取ることで 決定する。
演習:タイタニックの乗客データをもとにした生死判別のモデル



主成分分析
多変量解析における次元圧縮の手法。次元を削減するのではなく、情報損失をなるべく小さく圧縮する。
1.最も分散が大きくなるように低次元化を行う。
※分散が最も大きくなる射影軸をとることで、情報損失を最小化できる。
2.それぞれのベクトルは直行する
演習:乳がん検査データの2次元圧縮


アルゴリズム
・k近傍法
与えられたデータに対し、最も近い点をk個取ってきて、それらが最も多く所属するクラスに分類する。教師あり学習の一つ
例:以下の図で、点X(青い点)が「赤・緑」のどちらに分類されるかを考える

K=1のとき

最初の一つ目が赤のため、「赤」に分類される
K=5のとき

最も近い5個は赤=2個、緑=3個のため、「緑」に分類される
K=7のとき

最も近い7個は赤=4個、緑=3個のため、「赤」に分類される
・k-means
クラスタリング手法の一つで、代表的な教師なし学習

こんな風に分けたい
↓↓↓↓↓

演習


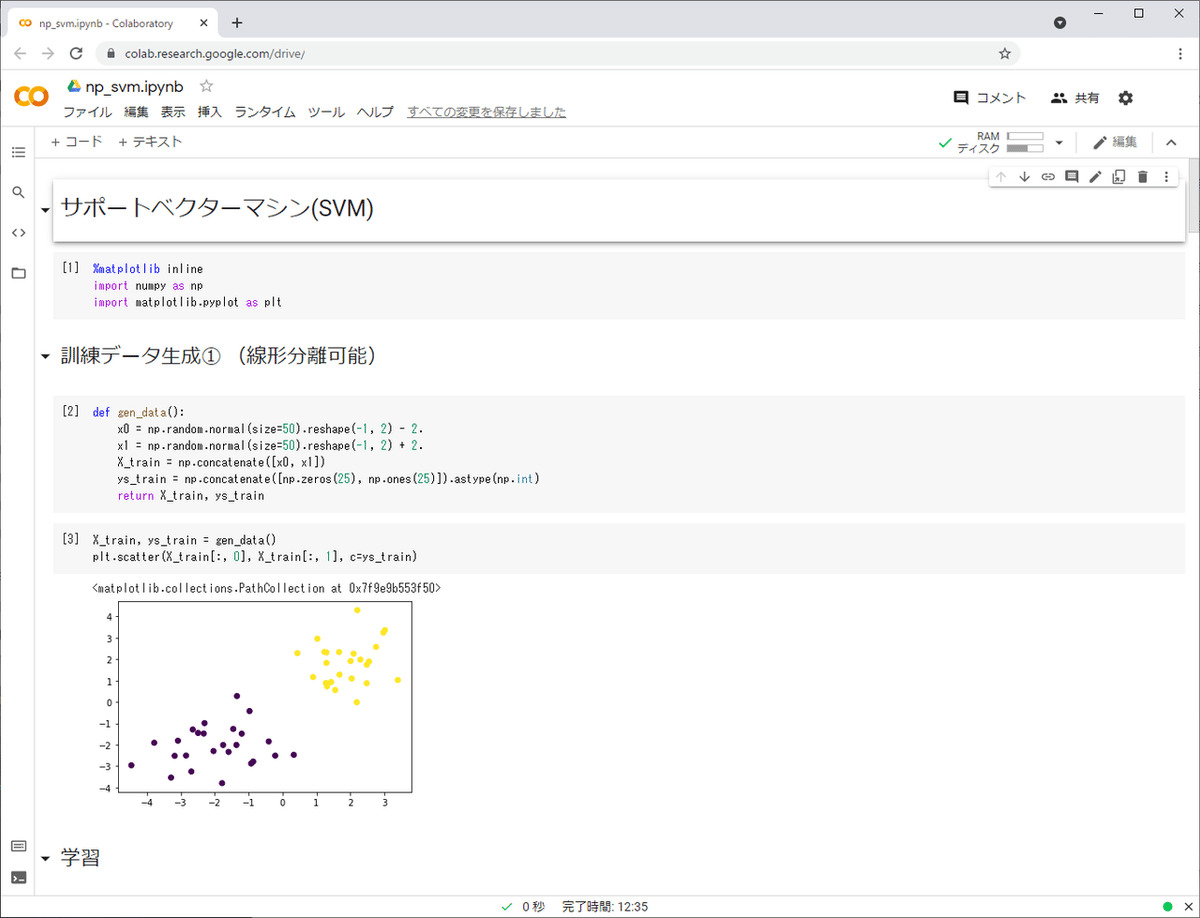
サポートベクターマシン
教師あり学習による2値分類モデル。データを二つに分類するための超平面を見つけるというもの。2次元データでは以下のようなイメージ

複数の線を持つことが出来るが、最も近い点との距離が最大(マージンが最大という)となる線を決定境界と呼ぶ

上記の図のように、完全に2分することが出来る決定境界が存在する分類をハードマージンと呼ぶが、データによっては必ずしも完全に2分することが出来ないケースも存在する。
そのとき、条件を緩めていくつかは反対側に入ってしまう(多くは2分できる)ような分類をソフトマージンと呼ぶ。
ソフトマージンはスラック変数と呼ばれる許容誤差を定め、マージンを最大化しつつ誤差を最小化する

演習