ラビットチャレンジ:Stage4実装演習レポート

深層学習Day3
確認テスト
5×5の入力画像をサイズ3×3のフィルタで畳み込んだときの出力画像サイズ
ストライド2、パディング1

以下の図のようになる

よって出力画像は3×3
Section1:再帰型ニューラルネットワークの概念
RNN全体像
RNN(Recurrent Neural Network)
時系列データに対応可能なニューラルネットワーク
音声データやテキストデータなど、時間的な変遷があり、且つ統計的にその関係性が認められるもの
音声データ:連続的な音の変化など
テキストデータ:単語の並びに意味があり、順序が意味を持つ
など、時間的なつながりのある情報を効率よく学習させるモデル
確認テスト
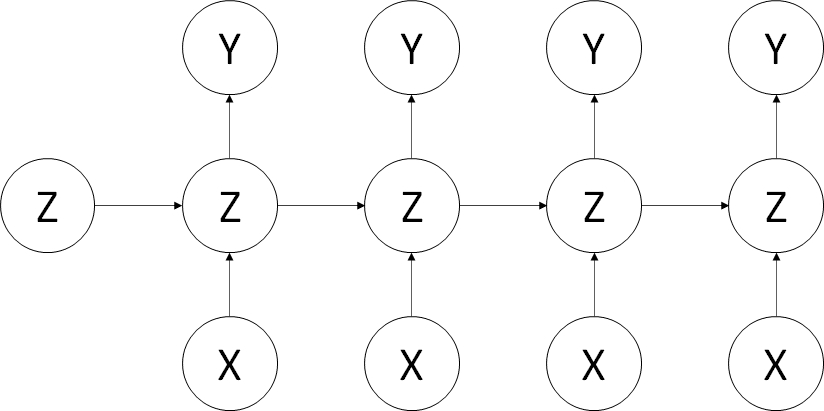
RNNに登場する第3の重み
中間層から次の中間層を定義する際にかけられる重み(図中のZからZへの重み)
実装:


BPTT(Backpropagation Through Time)
RNNにおいての誤差逆伝播の手法
確認テスト1
dz/dx = dz/dt * dt/dx
z = t^2
t = x + y
dz/dt = 2t
dt/dx = 1
dz/dx = dz/dt * dt/dx = 2t = 2(x+y)か確認テスト2
Y1 = g(Wout * S1 + c )
S1 = Win * X1 + W * S0 + bBPTTの全体像
実装:


Section2:LSTM
RNNは時系列を遡って重みを決めていくが、その過程で勾配が損失してしまうため、長い時系列での学習が困難である。(勾配損失問題)
RNNにおいて勾配損失問題が起こらないような構造がLSTM
確認テスト
sigmoid(x) = 1/(1 + exp(-x))
sigmoid'(x) = (1- sigmoid(x))*sigmoid(x)
sigmoid'(0) = (1 - sigmoid(0))*sigmoid(x)
sigmoid(0) = 1/(1+exp(0)) = 1/(1 + 1) = 1/2
sigmoid'(0) = (1 - 1/2)*1/2 = 1/4 ・・・(2)勾配爆発
勾配損失問題とは逆に、勾配が爆発的に大きな値になってしまう問題
CEC
時間的な依存が無く、常に一定の重みをとる層
入力ゲート・出力ゲート
入力値の重みを行列で変換可能とする
忘却ゲート
過去の情報を不要になった時点で忘れるための機能
確認テスト
忘却ゲートの作用によるもの
覗き穴結合
CEC自身の値に、重み行列を介して伝播可能にした構造
Section3:GRU
GRUとは?
LSTMが計算量が膨大になるのに対し、計算量を大幅に削減して同等またはそれ以上の精度が望めるようになった構造。
LSTMの機構から一部の層を削除しているが、タスクによっては良い性能を発揮する。
これにより、長期的な依存関係を学習することが出来る。
確認テスト
LSTMの課題:パラメータが多く計算量が膨大になる。
CECの課題:記憶域のみで学習特性が無い
実装:


確認テスト
GRURはLSTMに比べて変数やゲートの数が少なく計算量が少ない単純なモデルである。
Section4:双方向RNN
過去の情報だけでなく未来の情報を加味することで、精度を向上させるモデル。RNNが時系列の「前」の情報を用いていたのに対し、双方向RNNでは「後」の情報からさかのぼって作用する層を設けて、精度を向上させている。
文章の推敲や機械翻訳で活用される。
Section5:Seq2Seq
Encoder-Decoderモデルの一種
Encoder RNN
テキストデータを単語などのトークンに区切って渡す構造
Taking:文章を単語ごとに分割
Embedding:単語を表す分散表現ベクトルに変換する
Encoder RNN:ベクトルをRNNに入力
Decoder RNN
システムがアウトプットデータを単語のトークンごとに生成する構造
Sampling:生成確率に基づいてtokenをランダムに生成
Embedding:選ばれたtokenをEmbeddingしてDecoder RNN へ
Detokenize:上記を繰り返し、tokenを文字列にもどす
確認テスト1
解答(2)
(1) は双方向RNNの説明
(3) は構文木の説明
(4) はLSTNの説明
確認テスト2
seq2seqは一つの時系列データから別の時系列データを得る手法
HREDはseq2seqに文脈の意味をくみ取る機構を加えたもの
VHREDはHREDが文脈に対して当たり障りのない回答しか作れなくなった時の対策
確認テスト3
VAEは自己符号化器の潜在変数に確率分布を導入したもの
Section6:Word2vec
RNNでは単語のような可変長の文字列をニューラルネットワークに与えることは出来ないので、固定長形式で単語を表現する必要がある。
Word2vecは単語をベクトル表現するための手法の一つ。
文章を区切って使われている単語をリストアップし、それぞれの単語の使われている順にone-hotベクトルを生成する。
Section7:Attention Mechanism
Seq2seqは長い文章に対応できない。単語数によらず固定次元ベクトルの中に入力しなければならないため、文章が長くなると表現できなくなる。
文章の長さに応じて内部表現の次元が大きくなる仕組みが必要
→「入力と出力のどの単語が関連しているのか」の関連度を学習するしくみ
確認テスト
RNNとword2vec、seq2seqとAttentionの違い
RNNは時系列データを処理するのに適したネットワーク
word2vecは単語の分散表現の手法
seq2seqは一つの時系列データから別の時系列データを得る手法
Attentionは時系列データの関連性に重みを付ける手法
深層学習Day4
Section1:強化学習
強化学習とは、行動の結果得られる報酬をもとに、行動決定の原理を改善する仕組みのこと。
教師あり学習:
答えがわかっているデータを使って、答えを出す仕組みを学習すること
教師なし学習:
データの特徴からデータ群を分割することで、答えを導き出すための学習
強化学習:
正解かどうかはわからないが、それぞれの行動によって得られる報酬を基準に、それがより多く得られる行動を選択できるようにするための学習

強化学習の応用例
マーケティングにおいて、キャンペーンのコスト(負の報酬)と実際に売り上げが上がるという正の報酬に対して、強化学習によって行動(キャンペーンメールの送り先)を決める
この時、
環境:マーケティングという場(企業の部署)
エージェント:キャンペーンメールの送り先を決めるソフトウェア
行動:顧客に対しメールを送るか送らないか
報酬:送ることに掛かるコスト(負の報酬)、売り上げが上がるというコスト(正の報酬)
強化学習では、どのような顧客にメール送るとどのような行動(売り上げがあがるか)がわからない状態から、結果を得ながら行動指針を変えていく。
価値関数
報酬を決定する関数
方策関数
行動を決定する関数
Section2:AlphaGo
Googleが開発した囲碁のプログラム。強化学習により、より報酬の高い打ち手を選択することで、勝ちに結び付ける。
Alpha Go Lee:
2016年、韓国の世界トップ棋士李氏に勝利したAlpha Goの2代目バージョン
PolicyNetと呼ばれる方策関数のニューラルネットワークと、ValueNetと呼ばれる価値関数で構成されている。
Alpha Go Zero:
4代目バージョン。40日の学習でAlpha Go Leeに100戦全勝するレベルまで到達した。PolicyNetとValueNetを統合し、さらにResidual Netと呼ばれる新たな層を追加した。
Residual Netはショートカット構造を追加して、勾配の爆発、消失を抑える効果を狙ったもの。これにより100層を超えるニューラルネットワークでの安定した学習を可能とした。
Section3:軽量化・高速化技術
深層学習では、何層にも重なる層を多くのパラメータで構成していることから、しばしば膨大な計算量に陥ることも少なくない。
そのことから、高速な計算が求められこれらの手法について学ぶ。
主に「データ並列化」「モデル並列化」「GPUによる高速技術」を考える。
データ並列化
親モデルを各ワーカーに子モデルとしてコピー。データを分割し、各ワーカーごとに計算させる。各ワーカーの計算を同期をとりながら進める手法と、非同期に各々のワーカーで進める手法がある。
非同期型のほうが圧倒的に早いが、最新のモデルのパラメータを利用できないため、学習が不安定になりやすい。
結果として、同期型のほうが精度が良いことが多く、主流となっている。
モデル並列化
モデルそのものを分割し、各ワーカーで学習した後に一つのモデルに復元する。
GPUによる高速化
本来はグラフィック処理に向けて開発された演算装置
CPUに比べ、単純な計算の並列処理に長けている。ニューラルネットは単純な行列演算が多いため、高速化が可能。
モデルの軽量化
量子化・蒸留・プルーニングなどの手法により、モデルそのものを軽量化し、モバイル・IoT機器などに活用する。
量子化
パラメータの64bit浮動小数点を32bitなど下位の精度に落とすことで演算処理の削減を行う。
モデルの表現力が低下する。
蒸留
規模の大きなモデルの知識を使い、軽量なモデルの作成を行う
プルーニング
モデルの精度に寄与が少ないニューロンを削減し、モデルの軽量化をはかる
Section4:応用モデル
MobileNet
ディープラーニングモデルの軽量化・高速化・高精度化を実現する。
一般的な畳み込みレイヤーは計算量が多い。Depthwise ConvolutionとPointwise Convolutionを組み合わせて軽量化を図る。
・Depthwise Convolution
入力マップのチャネルごとに畳み込みを実施し、出力マップをそれらと結合して入力マップのチャネル数と同じにする。
・Pointwise Convolution
1 x 1 convにより出力マップをフィルタ数分だけ作成する
DenseNet(Densely Connected Convolutional Networks)
Residual Networkでは前方の層から後方の層へアイデンティティ接続を介してパスを作ることで、層が深くなるにつれて学習が難しくなるという問題を対処(勾配消失問題)した。
DenseNetはDenseBlockと呼ばれるモジュールを用いた同手法の一つ。
出力層に前の層の入力を足しあわせ、層間の情報の伝達を最大にするために全ての同特徴量サイズの層を結合する。
Batch Norm以外の正規化
Batch Norm:
ミニバッチに含まれるsampleの同一チャネルが同一分布に従うよう正規化。
ミニバッチのサイズを大きく取れない場合には、効果が薄くなってしまう
Layer Norm:
それぞれのsampleの全てのpixelsが同一分布に従うよう正規化。
ミニバッチの数に依存しないので、上記の問題を解消できていると考えられる。
Instance Nrom:
さらにchannelも同一分布に従うよう正規化。
コントラストの正規化に寄与・画像のスタイル転送やテクスチャ合成タスクなどで利用。
Wavenet
音声生成のモデル。
提案された新しいConvolution 型アーキテクチャはDilated causal convolutionと呼ばれ、結合確率を効率的に学習できるようになっている
Dilated causal convolutionを用いた際の大きな利点は、単純なConvolution layer と比べてパラメータ数に対する受容野が広いことである。
Section5:Transformer
自然言語処理で利用される深層学習モデルで2017年に発表された。
Encoder-Decoderモデルは文章が長くなると表現力が足りなくなる。
注意機構(Attension)とは、翻訳先の各単語を選択する際に、翻訳元の文中の各単語の隠れ状態を利用。辞書オブジェクトとも言われる。これにより、文が長くなっても翻訳精度が落ちない
注意機構を使って考案されたのがTransformer。RNNを使わずAttentionのみ。
注意機構には「ソース・ターゲット注意機構」と「自己注意機構」Transformer-Encoderは自己注意機構。
RNNを用いないので単語列の語順情報を追加する必要がある。
注意状況を確認すると言語構造を捉えていることが多い。
Section6:物体検知・セグメンテーション
物体検知のアルゴリズムの中身では無く、共通して押さえて見なければならないこと(精度評価など)を学ぶ。
◆物体の位置にこだわらない
分類(Classification):
クラスラベルを得る
◆インスタンス(個体)にはこだわらない
物体検知(Object Detection):
どこに何があるか(Bounding Box)
意味領域分割(Semantic Segmentation):
各ピクセルに対しラベルが割り当てられる
◆インスタンス(個体)にこだわる
個体領域分割(Instance Segmentation)
各ピクセルに対して個体ごとのラベルが割り当てられる
代表的なデータセット
目的に応じて使い分ける必要がある。

「Box/画像」が小さい(写っている物体数が少ない)と、日常風景では無くアイコン的なもの。「Box/画像」が大きい(写っている物体数が多く、重なりもある)とより日常的なシーンとなる。
クラス数
写っているものがどの程度詳細に分類されているか?を図るものではあるが、同じものを別の呼び名で分類されていることもあるので、必ずしも大きければ良いというものでは無い。
評価指標

IoU:Intersection over Union(物体位置の精度)

mAP:mean Average Precision(PR曲線の下側面積)

SSD: Single Shot Detector
特定の領域内に含まれる検出したい物体を判定する
Semantic Segmentation(意味領域分割)
画像分析では、ConvolutionやPoolingを重ねていくことで入力画像の解像度が落ちていく。
Semantic Segmentationでは、各ピクセルごとにクラスラベルを付けたいので、そのままでは困る。
落ちた解像度を戻すことをUp-samplingと呼び、これがSemantic Segmentationの重要ポイント。DeconvolutionやTransposed convolutionなどの手法がある。
また、Dilated ConvolutionなどConvolutionの段階で受容野を広げる工夫もある。