
日刊 画像生成AI (2022年10月26日)

画像生成AI界は、今認識できないスピードで進化をし続けています。
DALL・E2公開、Midjourney公開、StableDiffusionがオープンソースで公開され、日々とても早いスピードで変化しています。

そんな中、毎日時間なくて全然情報追えない..!って人のために業界変化、新表現、思考、問題、技術を毎日あらゆるメディアを調べ、まとめています。
過去の投稿はこちら
開発
StableDiffsuiionが利用できるサービスの1つ、「getimg.ai」にtext2maskが追加
部分修正する際は普通ペンやツールでマスクを作って、プロンプトを入力してそこだけ置き換えるのが主流ですが、text2maskを使えばプロンプトでマスクを作ることができます。webui by automatic1111にも実装されていますがこの度、stablediffusionが使える有名な海外のサービスの1つ、getimg.aiにその機能が搭載されました。この機能が搭載されてるSDwebサービスはまだないのでいいですね、ていうかここ最近これ系サービスの競争がすごい。

DreamBooth by Cantrell
Stability AIのプロダクト担当副社長, PhotoshopのStableDiffusionが使えるプラグイン開発をされていたCantrell氏がいくつかのバグ修正、利便性、およびユーティリティを備えた DreamBooth リポジトリのフォークを作成しています。今 Nvidia A100でテスト中とのこと。
I created a fork of the DreamBooth repo with some bug fixes, conveniences, and utilities. I'm testing it out now on an A100 rented through @vast_ai. If you want to fine-tune @StableDiffusion, give it a try.https://t.co/eOmBJIqosf
— Christian Cantrell (@cantrell) October 25, 2022
StableDiffusionで生成した画像アセットを利用して、(キャラクター以外)リズムゲームを作成している方がいます。
すごい、Midjourneyの素材で作られているゲームは公開されてバズったりしていましたが、StableDiffusionだともうこのままリリースできそうでいいですね、Midjourneyだとどうしてもそれ感が出てしまうので。
テキストからゲームを生成できるようになって、画像素材も同時にこうやって生成できるようになったら本当に楽しそう。

ゼルダ姫のHypernetworkが公開
BOTW のゼルダのスクリーンショットでHypernetwork学習をした方がおり、ptファイルを公開されています。違いは以下の画像に添付しました。


Windowsで、ShivamShriraoリポジトリ(DreamBooth)をローカルで使用する
表現
元絵を分割してimg2imgして作るアートが流行っています
AIに読み込ませる参考画像を9等分して、それぞれでimg2imgをして生成するアートがこの日海外では流行っているようです。



NovelAIで複数キャラを顔を崩さず出力する方法
高杉さん曰く、こちらのプロンプトでいけるようです。猫の絵文字を大量に使って大量に猫を出力するのをかりみやさんがやられていたので、絵文字はいいのかもしれません。
masterpiece, best quality some girls, 美味しいヤミー❗️✨🤟😁👍感謝❗️🙌✨感謝❗️🙌✨❗️🍖😋🍴✨🙏✨🙏✨ 🙏✨ 🙏✨🙏✨🙏✨ ハッピー🌟スマイル❗️👉😁👈
今まで困難だった顔を崩さず複数のキャラ同時出力する方法が発見された
— 高杉 光一🦋 (@kuronagirai) October 26, 2022
だが特定のキャラを指定して…ってところだとまだ難しい…
貫通力の高い子と低い子の差が大きい…#NovelAI#NovelAIDiffusion #画像生成AI pic.twitter.com/rhxlhohtE3
複数人召喚のやり方はこちら
— 高杉 光一🦋 (@kuronagirai) October 26, 2022
masterpiece, best quality some girls, 美味しいヤミー❗️✨🤟😁👍感謝❗️🙌✨感謝❗️🙌✨❗️🍖😋🍴✨🙏✨🙏✨ 🙏✨ 🙏✨🙏✨🙏✨ ハッピー🌟スマイル❗️👉😁👈
おいヤミの肉をケーキに変えることも可#画像生成AI#NovelAI#NovelAIDiffusion https://t.co/lsekkxZm4a
研究
一昨日登場した新しいDreamBoothの検証続々
新しいDreamBoothとはこちらとこちら。モデルを破壊せず、数百の概念も学習できる上、1時間程度で学習できるというすごいDreamBoothが公開されて話題になりました。初めての方に向けて話すとDreamBoothは少ない枚数で新しい概念を学習させ、モデル全体に影響を与えるもの。
この人は1500stepくらいの学習がちょうど良かったなぁとのこと。

リーサ・リサージュ・ヤスミンさんも複数概念学習できるノートブックを作られていました。ShvamShriraoさんのdiffusers改造独自機能実装があるんですね
DreamBoothで複数概念を学習できるノートブック作って検証してみました。アンルシア(キャラ)とラーメンイラスト(構図)を学習させることで、ラーメンを食べるアンルシアを描くみたいなことが出来るようです。https://t.co/q04JDf0wnj#DreamBooth #WaifuDiffusion pic.twitter.com/SsM3RnfejE
— リーサ・リサージュ・ヤスミン (@LisaDQX) October 26, 2022
注意点
— リーサ・リサージュ・ヤスミン (@LisaDQX) October 26, 2022
・DreamBoothで複数学習は重いので、プレミアム版のGPUじゃないと動かない感じです
・複数学習させるせいか、単品での学習精度(服の再現度等)は下がっている感じです
・ラーメンイラストを学習させても、ラーメン食べるのはあんまり上手くならないです
学習対象が両方人じゃなければ大丈夫というわけじゃなく、セラフィ(キャラ)とホイミン(マスコット)でも混ざる感じなので、ラーメン食べてるイラストみたいに、混ぜる前提の概念じゃないと使いにくそうです pic.twitter.com/cxt5t5tr2d
— リーサ・リサージュ・ヤスミン (@LisaDQX) October 26, 2022
技術的補足。
— リーサ・リサージュ・ヤスミン (@LisaDQX) October 26, 2022
複数読み込み機能はShivamShriraoさんのdiffusers改造独自の機能ですが、やっていることは既存機能のprior preservationを複数実行しているだけな気がします(詳細は読めてない)
prior preservation使うと学習効果を限定出来るので、そのおかげで複数概念を学習できてるのかなと。
prior preservationを使うとVRAMの使用量が増えるのでGoogleColabの通常GPUでは動かなくなるのですが、さらにVRAM節約するdiffusers改造を作ってる人もいて、そちらだとprior preservationが通常GPUでも動くので、そちらの成果が反映されるの期待したいところ。https://t.co/XnJmEjkB1q
— リーサ・リサージュ・ヤスミン (@LisaDQX) October 26, 2022
タコ姉,ずんちゃん,きりたん,めたん,ずんだもんの5人を同時にDreamboothで学習.
— しらゆ (@shirayu) October 25, 2022
モデル切り替えなしに描けるようになった✌
ただ,異なるキャラを的確に同時に出す良い方法はまだ見つけられてない.
また,特徴の学習が若干弱い気はする(学習ステップが不足している可能性はある) pic.twitter.com/8W6oKBziI4
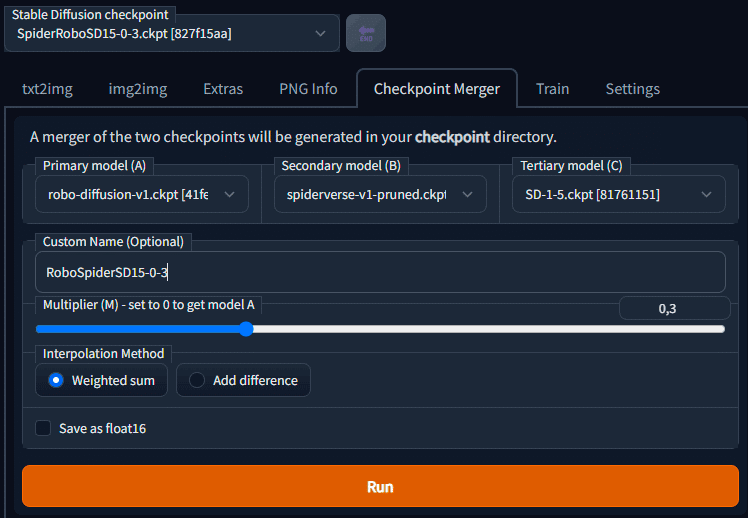
Spiderverse Diffusion + Robo Diffusion + Arcane Diffusionの結合
チェックポイントをマージする実験をされている方がいたのでメモ。roboはほぼ消えてるけど、いい出力ですね

StableDiffusionで手を作る方法
手書きからおそらくimg2imgを繰り返して手を綺麗にしている事例。ただ解剖学的に明らかにおかしかったりするのでこの辺りは難しいですね、個人的には元写真として手の写真を使うか、3Dモデルの手を使うかでimg2imgするのが現状としては一番クオリティが高いと思っています。

思想・ムーブメント
StabilityAIのローンチイベントの公式動画アップロード, 内容をスレッドでツイート
StabillityAIのローンチイベントに関しては以前解説しましたが、公式アカウントで動画をアップ、内容についてスレッドで紹介されているのでまだ見ていない方はこちらをチェックするのもいいかと思います。
Last week we had our official launch event where we shared some of the projects we are working on.
— Stability AI (@StabilityAI) October 25, 2022
You can watch the full recording over here! → https://t.co/OQMwkOvUqq
Here are some of the announcements we made at the event🧵
Our CEO, @EMostaque, joined @KevinRoose and @CaseyNewton on their @nytimes podcast, Hard Fork, to discuss Stability AI's approach to open-source AI and share some of the recent announcements.
— Stability AI (@StabilityAI) October 25, 2022
Listen here → https://t.co/jw6VjciZCO
以前の解説はこちら
Myuk - フェイクファーワルツ (Music Video)
Midjourneyの背景(852話さんが生成)を使ったミュージックビデオが公開されました。素敵な作品なのでぜひ!
AIから考える面白いのメカニズム
この日の気になるツイート
予想どうりの展開になってきた。課題は20億画像でトレーニングしてる場合、20億生成あたり0.1円とかの金額感になりそうなことかなぁ。 https://t.co/aovjUCIFdV
— 深津 貴之 / THE GUILD / note.com (@fladdict) October 26, 2022
Shutter stockの動きは、クリエイター保護と同時に、オープンAI破壊の手でもあって、この流れは「モデルはクローズで、巨大データセットを持ってる会社に占有される」という流れを後押しするものでもある。どういう展開になるか
— 深津 貴之 / THE GUILD / note.com (@fladdict) October 26, 2022
昨日某誌のインタビューで、昨今のAI画像生成やプロンプト・エンジニアリングは、DJ行為に近いのではという話した。
— Nao Tokui / 徳井直生 『創るためのAI』📘 (@naotokui) October 26, 2022
既存のスタイルやコンテンツをうまくミックスして、その人なりの「新しい」コンテンツを生み出す。過去の作品/歴史に関する知識が必要なのも同じ。
勉強
Qosmoさん、深津さん、水野さんの勉強会アーカイブ
生成AIはビジネス・デザイン・アートをどう変えるのか?のセミナーに参加していたんですがレポートが公開されたようです。大変面白くて勉強になったので興味ある方は是非。
最後に
Twitterに、毎日製作したものや、最新情報、検証を載せたりしています。
よかったら見ていただけたら嬉しいです。
画像生成AIの実験, 最新情報のまとめはこちら
過去の号はこちら
次の号はこちら
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます