
【松尾研LLM講座】第7講「RLHF」を受講して

ここまでの講義の流れをざっくりと振り返ると、
第2講:「PromptingとRAG」で学習済モデルの活用の仕方を、第3講:「Pre-training」にて事前学習の方法について、第4講:「Scaling Law」にて大規模化している背景について、第5講「Fine-tuning」にて事前学習モデルに対して追加の学習を行う手法について学んできた。
今回の第7講では、RLHF(Reinforcement Learning with Human Feedback)について。これは、Fine-tuningの一種であり、特に人間のフィードバックを取り入れた強化学習を活用することで、より自然な出力を生成できるように言語モデルを調整する手法です。
RLHFは、これまで学んできた知識と密接に関連しており、GPTシリーズが驚くほど自然な出力を可能にしている要となる技術でもあるため、きちんと理解したいですね。
RLHFの必要性
狭義のFine-TuningであるInstruction-Tuningでは、事前学習済のモデルに対して、特定の下流タスクへの精度を高めるために教師あり学習を行いますが、人間らしい出力へ近づけたり、人種差別や犯罪行為の教唆など、意図しない発言を抑制するのは難しいとされていました。
そこで、今回学んでいくRLHFという人間のフィードバックを強化学習の報酬として取り入れることで、より人間らしい、不適切な発言が抑制された、それでいて多様な応答を実現するための改善を行う技術が必要となった、という形のようです。
RLHFの3ステップ
RLHFは以下の3ステップにより構成される。
step1. 教師あり学習
step2. 報酬モデルの学習
step3. 強化学習
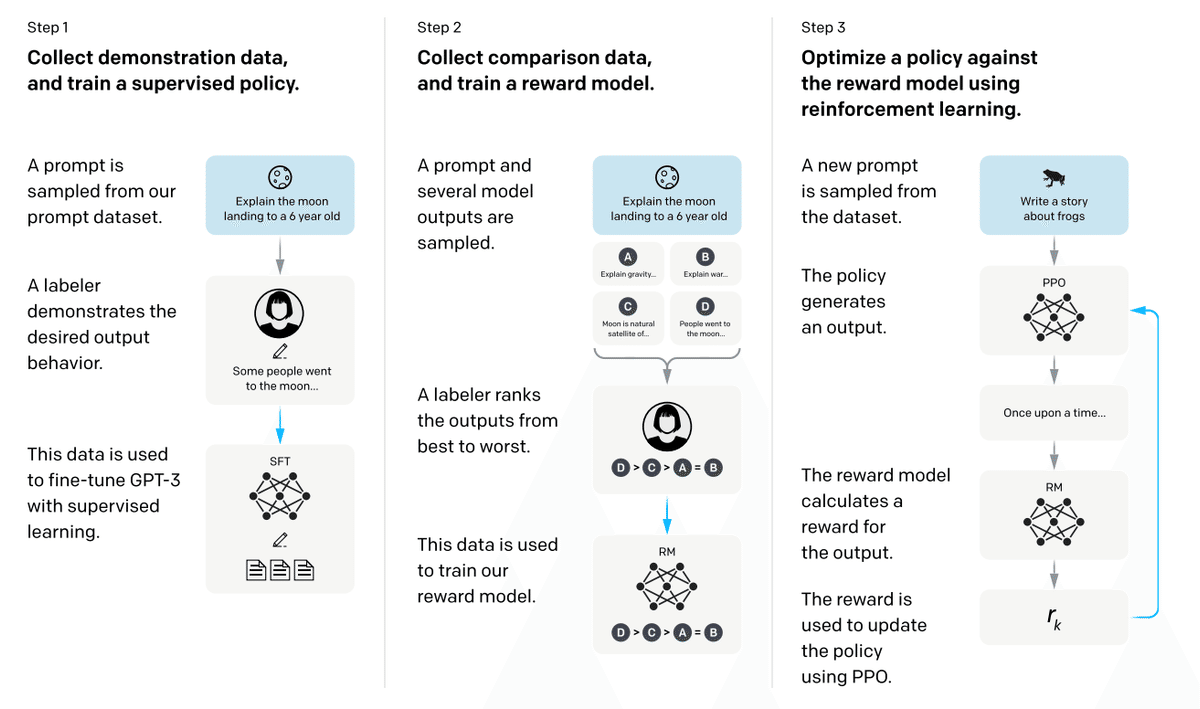
step1. 教師あり学習(SFT:Supervised Fine-Tuning)
最初のステップはプロンプトとそれに対応する応答文をラベラー(人間)が作成し、それを教師データとして教師あり学習によりFine-Tuningする。
step2. 報酬モデルの学習(Train Reward Model)
step1で学習させたモデルが用意した複数パターンの回答をラベラーが評価し、その順位付けデータセットを用いて報酬モデルを学習させる。

step3. 強化学習(Reinforcement Learning)
step1,step2で学習させたモデルを用いて強化学習を行う。step1のモデルの回答に対して、step2の報酬モデルにより評価を行い、フィードバックすることでモデルを改善していく。

まとめ
本講義を受講して、RLHFの基礎について理解が進みました。このnoteでは本当に基本的なところしかまとめられていませんが、講義では発展的な話題として、報酬モデルを使用せず直接ランキングを学習するDPO(Direct Preference Optimization)なども紹介されていました。まだまだLLMの奥は深いですね。
それではまた!
<それぞれのジャンルの記事まとめ(マガジン)>
いいなと思ったら応援しよう!
