
【松尾研LLM講座】第4講「Scaling Law」を受講して

先々週の「PromptingとRAG」も先週の「Pre-training」も非常に面白かったが、今週の「Scaling Law」も非常に面白かった。
自身の知識定着のためにも、noteへアウトプットしていく習慣をつけたい。
スケール則とは何か
第3回に引き続き、LLM学習の最初のステップである事前学習について。その中でも超有名なスケーリング則についての講義であった。スケーリング則を語る上で欠かせないのは、2020年にOpenAIから発表された以下の論文である。
Scaling Laws for Neural Language Models
まず1つ目の論文は、計算資源(C)、データセットサイズ(D)、パラメータ数(N) と誤差(L)の間に成立する経験則を主張する論文である。
表の左から、それぞれの変数の組み合わせに対してスケーリング則が成立していると主張している。
・計算資源(Compute)と誤差(Loss)
・データセットサイズ(Dataset Size)と誤差(Loss)
・パラメータ(Parameters)と誤差(Loss)
ここでいうLossは交差エントロピー誤差であり、それぞれの変数以外(他2変数)は十分大きいと仮定している。

(出典:OpenAI「Scaling Laws for Neural Language Models」)
ちなみに計算資源にPF-daysは「Peta FLOPs days」であり、「1ペタFLOPSの処理速度を持つサーバで何日学習にかかるか」という意味である。
FLOPSとFLOPsは、少しややこしいが、以下のような意味の違いがある。
・FLOPs(Floating Point Operations)
→何回浮動小数点演算を含むか。(計算量の指標)
・FLOPS(Floating Point Operations Per Second)
→1秒あたりに処理できる浮動小数点演算の回数。(計算速度の指標)
また、「Scaling Laws for NLM」の次に有名なのが2022年にDeepMindから提出された以下の論文である。
Training Compute-Optimal Large Language Models
この論文では、計算資源を最適化してトレーニングする大規模言語モデルのサイズとトレーニングに使用するトークン数を決定する方法を提案している。
最適なパラメータ数とトレーニングトークンの割り当てを決めるアプローチとして、以下の3津が解説されている。
Fix model sizes and vary number of training tokens: モデルサイズを固定し、トレーニングトークン数を変動させるアプローチ。
IsoFLOP profiles: 計算資源(FLOP)を等しく維持しながらモデルサイズやトークン数を変えるアプローチ。
Fitting a parametric loss function: 損失関数をパラメトリックにフィッティングするアプローチ。

(出典:DeepMind「Training Compute-Optimal Large Language Models」)
ただ、スケールしてるスケールしてるとは言うが、実際はどのくらい増えているのだろうか。
GPT-1:117M
GPT-2:1.5B
GPT-3:175B
GPT-4:約1.8T(より詳細には、220Bモデル×8)
trillionなんてトリリオンゲームでしか聞いたことない。笑
ちなみにmilliion = 100万、billion = 10億、trillion = 1兆である。

「The emergence of Large Language Models (LLMs)」
LLMの学習に必要な計算量とは
LLMの学習に必要な計算量は、パラメータ数Nとトークン数Dを用いて、以下の式で近似されることが多いらしい。
学習に必要な計算量 = 6 × N × D
6をかけるのは経験則らしいが、納得できる説明としては1パラメータあたりのMLP層における行列演算数が6回、というところに起因しているらしい。もちろんTransformerにはMLP以外にAttention層などもあるが、MLPが全体のパラメータの60-70%程度を占めると言われている。
【ミニクイズ】A100を1000基使うとして,GPT-3の学習にはどれくらいの学習時間が必要か?
講義中で出されたミニクイズに回答していく。
上記の近似式から、GPT-3に必要な計算量は以下のとおりである。
6 × 175B × 0.3T ≒ 3.14 × 10^23(FLOPs)
GPU A100は1基あたり10^14(FLOPS)の計算能力を持っているため、単純計算で1000基用いれば、10^17(FLOPS)となる。
これらより求めたい学習時間を計算すると、
3.14 × 10^23 / 10^17 = 3.14 × 10^6(second)
3.14 × 10^6 / 3600 ≒ 872(hour)
872 / 24 ≒ 36.3(day)
となり、1ヶ月強の時間が必要なことがわかる。
A100を1000基という贅沢な使い方をした想定だが、これが1/10の100基になると約1年、10倍の10000基になると学習が4日弱でおわることを考えれば、LLM開発企業がこぞってNVIDIAに頭を下げる理由がわかる。
スケール則の活用
スケール則はなんとなく理解できたが、実際にどのような場面で有用なのであろうか?それは、以下の問いに答えるときに活用できる。
①計算資源への投資判断:どこまでモデルサイズを大きくするか?
②効率的なモデル選択:パラメータを増やしたときにどちらが良いモデルか?
③効率的な計算資源の活用のための判断:トークン数とパラメータ数のどちらを増やすべきか?
これらはどれも経営判断に関わる部分なので、大きな関心が集まるのもうなづける。
あるモデルをスケールするべきか
まず1点目の「計算資源への投資判断」について。
あるモデルをスケールさせた時に「やってみたけど性能上がりませんでした」では商売にならない。
しかしスケール則があることにより、スケールさせた場合にどのような精度向上が見込めるのかが予測がつくようになっている。
下記は横軸が計算量、縦軸がnext word predictionの精度であり、縦軸がlogスケールのため直線ではないが、確かにスケール則が成り立っている。

(出典:OpenAI「GPT-4 Technical Report」)
より精緻なモデル選択
そもそもどのモデルをスケールさせるか?というところも論点である。化学でいうラボとプラントの違いのように、スケールしてもスケール前のモデルの精度比が受け継がれる保証はどこにもない。
ただ、以下の図を見るとスケールしても
Transformer < LSTM
であることが推察できる。
外挿によりモデルスケールした場合の精度を予測できる。

また、下の図の左からは大きなモデルはより少ないサンプルでLossが下がり始めることがわかり、サンプルサイズに制約ある場合などに考慮すべきパラメータに示唆を与えてくれる。
右の図からは。小さなモデルだと学習途中からLossが下がりづらくなることが示されており、Lossを下げようと思うなら小さなモデルで計算資源を投下し続けるのは非効率であることがわかる。

「Scaling Laws for Neural Language Models」
スケール則の具体的な求め方
基本的には比較的小さな条件で、測りたいパラメータ以外を固定した状態で実験していく。
左の図: 各FLOPsに対して、モデルのパラメータ数とトレーニング損失の関係を示す。計算資源を固定し、パラメータ数を変化させることで、計算資源の量に適したパラメータ数を特定することができる。
中央の図: FLOPsに応じた最適なモデルのパラメータ数の関係を示す。計算資源と学習可能なモデルのパラメータ数は比例関係にあることがわかる。
右の図: FLOPsに対するトークン数の関係を示す。計算資源と学習可能なトークン数にも比例関係があることがわかる。

「Training Compute-Optimal Large Language Models」
ただ、このように実験によりFittingを行ったとしても、「モデルサイズの変え方」や「ハイパラの設定方法」への疑問が残る。
まず「モデルサイズの変え方」についてだが、一言に「モデルサイズを変更する」と言っても
層を増やす
埋め込み次元を上げる
フィードフォワード層の中間層の次元を上げる
Attention層ヘッド数を増やす
など、幾つも選択肢があって悩ましい。
例えば、最初に紹介したスケーリング則を代表するOpenAIの論文の中には、以下のような議論がある。
パラメータ数を固定したときにネットワークのいくつかの要素を変動させて検討しているが、大きな影響がないという結論に至っている。
左の図: フィードフォワード層のサイズ比(d_ff / d_model)を変えた際のトレーニング損失の増加を示し、極端に増加させると損失が増えることを示す。
中央の図: モデル次元とレイヤー数の比(d_model / n_layer)に対する損失の変化を示し、広い範囲のモデル設計で性能が安定していることを示す。
右の図: アテンションヘッドごとの次元(d_model / n_head)に対する損失の増加を示し、アテンション次元が増加しても損失はわずかにしか増えないことを示す。

「Scaling Laws for Neural Language Models」
次に「ハイパラの設定方法」についてだが、一般的に通常の初期化の場合は最適なハイパラは変動する。
ここでは「μTransfer」という手法について紹介する。
本研究では、「Maximal Update Parametrization(μP)」というパラメータ化手法を用いることで、モデルサイズが変わっても最適なハイパーパラメータが安定することを発見。これにより、小規模なモデルでチューニングされたハイパーパラメータを大規模モデルに直接転送できる「μTransfer」が提案された。
下の図はモデルの幅(ネットワークのパラメータ数)が異なるTransformerモデルにおける、トレーニング損失と学習率の関係を示している。横軸は学習率の対数スケール(log2LearningRate)であり、右側にいくほど大きくなる。
異なる幅のモデルに対して最適な学習率がどのように変化するかについて、従来の方法(左)ではパラメータ数が増えるにつれて適切な学習率が大きくなる側に推移するのに対して、提案された新しい手法(右)ではパラメータ数に関わらず最適な学習率がほぼ同じ範囲に集約されている。
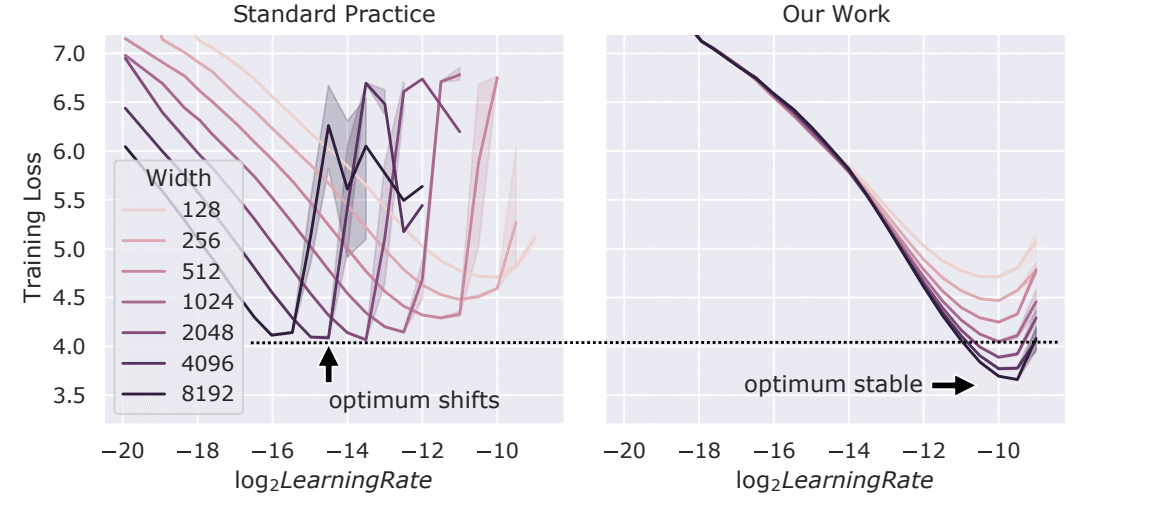
「Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer」
新たなトレンド:推論時のスケーリング
ここまでは事前学習のスケーリングの話であったが、OpenAI o1に代表されるように、近年では推論のスケーリングにも注目が集まっている。
以下の図はOpenAI公式のo1についての解説記事からの引用であるが、学習時・推論時どちらもスケーリングさせることで性能が向上することを報告している。

推論時のスケーリングとは、推論時の性能や精度を向上させるために、計算リソースやモデルサイズ、処理するデータ量などを指す。
有名な手法としては、思考の流れを出力させながら問題の回答に向かわせるChain-of-Thoughtや、問題と解答例のセットを多数与えるMany-Shot ICL、デコーディングを複雑にする方法などがある。
プロンプティングによる改善であるChain-of-ThoughtやMany-Shot ICLは第二講で解説があったため、以下ではデコーディングの工夫について述べる。
デコーディング
有名なデコーディング手法には以下のようなものがある
Greedy Decoding:確率が最も高いトークンを逐次選択していく。いわゆる貪欲法。一番確率が高い次の単語を選び続けるので、表現に多様性はない。
Beam Search:複数の候補を保持しながら、指定した「ビーム幅」だけ少し先のステップまで検討して最適な生成結果を探索する。精度は高いが計算コストが大きい。ビーム幅を広げすぎると計算量爆発・表現力の低下などの問題が起こりやすい。
Random Sampling:完全ランダムではなく、確率分布に基づいてサンプリングする。多様性のある生成結果が期待できるが、一貫性の低下や不自然な文章が生成される可能性があるなどのデメリットもある。確率分布の上位K個からサンプリングするTop-K Samplingや、累積確率がPになるまでのトークンから選択するTop-P Samplingなどがある。
デコーディングからメタジェネレーションへ
これまでの単語(トークン)レベルのデコーディングだけでなく、文章や段落の生成過程を評価することで全体最適を目指す概念、それがメタジェネレーションである。
メタジェネレーションの種類は以下の3種類がある。
Parallel search:並列に複数の候補を生成してスコアリングや多数決などにより生成物を選ぶ
Step level search:Stepレベルに評価を行なって生成物を選ぶ
Refinement:外部/内部のフィードバック結果を用いて,反復的に生成結果を更新する

(出典:「From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models」)
メタジェネレーション1:Parallel search
MBR Decoding(Minimum Bayes-Risk Decoding)
Self-Consistency
Best-of-N
N個の回答を出してみて、スコアが高いものを選択する手法。
スコアの算出方法はタスクによって使い分けられる。(ex . LLMのスコア、学習した評価器、BLUEなど特定の指標)
一般的にNを多くすればするほど回答の精度は高くなるが、その評価指標によって大きく差が開くことが以下でわかる。
多数決 < 結果評価 < プロセス評価
という結果になっている。多くの会社の人事制度にも通づるところがありそうな結果だが、一番良い結果を表してるプロセス評価ののアーキテクチャはProcess Reward Model(PRM)と呼ばれている。
ここはあくまで自分の解釈であるが、Outcome Reward Model(ORM)による精度向上がが一定のNで頭打ちになっているのは、ORMが評価関数の質に大きく依存し、推論を増やしても評価関数の質が上がる訳ではないことに由来しているのではないか。逆にPRMが伸び続けているのは、各プロセス評価関数の質にプロセス全体の評価が依存しきっていないので、推論を増やすことによる精度向上が続いていると考えている。
ただ、あくまで評価関数の質への影響が緩和されているだけな気がするので、1モデルでの精度向上はやはりどこかに壁があるのも事実であろう。
オレンジの線(PRM:Process-Supervised RM): プロセスを監督する報酬モデル
青の線(ORM:Outcome-Supervised RM): 結果を監督する報酬モデル
灰色の線(Majority Voting): 複数のソリューションに対して多数決

および多数決手法の問題解決能力の比較
(出典:OpenAI「Let’s Verify Step by Step」)
メタジェネレーション2:Step level search
先ほどは出力候補から1つを選び生成結果を決めていたが、このStep level searchではステップごとの評価を行い最終生成物を選ぶ。
講義ではステップレベルのビームサーチと第二講で紹介のあったTree of Thoughtsが紹介されていた。
Beam-Search (Step Level)

出典:DeepMind 2024「Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters」
Tree of Thoughts
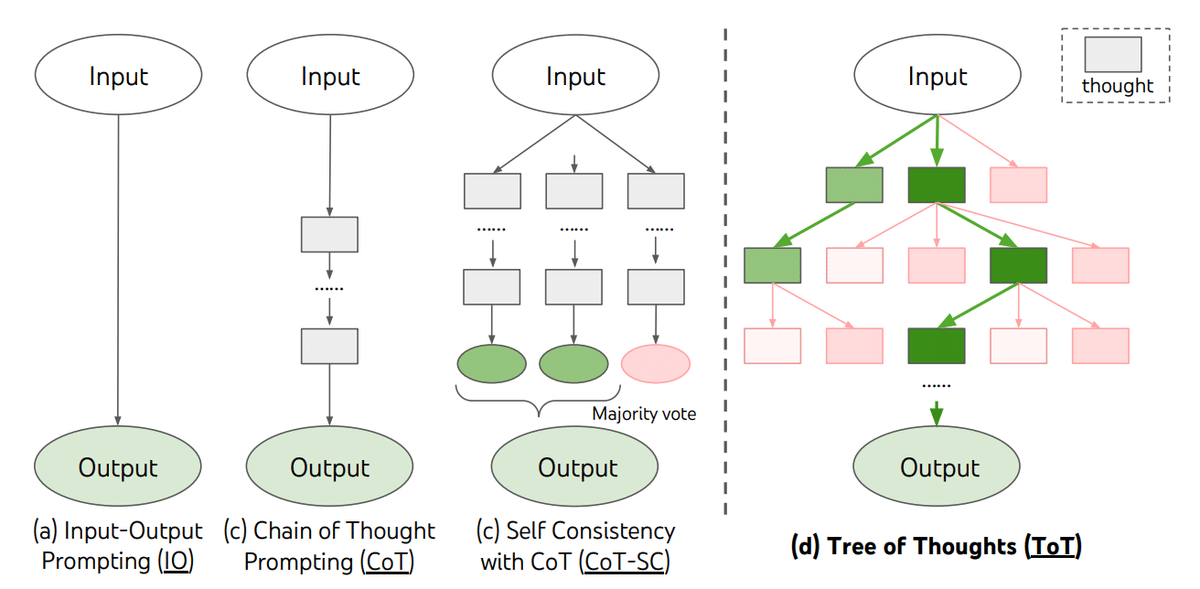
(出典:「Tree of Thoughts: Deliberate Problem Solving with Large Language Models」)
メタジェネレーション3:Refinement
最後はSelf-Refineと呼ばれるアーキテクチャに代表されるRefinementである。一般的なモデルは入力に対して出力は一度だけ行われるが、このSelf-Refineでは自身の出力に対して自身による見直しを行い改善した出力を行う。

この「自己改善」のステップを取り入れることで、GPT系列のモデルが下記タスクに対して最大50%の精度向上を達成したと報告されている。

(出典:「Self-Refine: Iterative Refinement with Self-Feedback」)
<それぞれのジャンルの記事まとめ(マガジン)>
いいなと思ったら応援しよう!
