
[Knitfab 技術ハイライト] 機械学習タスクを過不足なく自動実行する技術 -- #3 Projection: “足りない Run” を見つけ出す

はじめに
みなさんこんにちは。株式会社オープンストリーム・技術創発推進室、Knitfabチーフプログラマの高岡です。
この記事は Knitfab の主要機能のひとつである「自動ワークフロー」について、その詳細に迫る連載記事の最終回です。
#1 自動ワークフローのオーバービュー (前々回)
#3 Projection: “足りない Run” を見つけ出す(今回)
まだ 1 回目や2回目をお読みいただいていない読者には、この先を読み進める前に、これらの記事に目を通していただくことをおすすめします。
さて、前回は、Knitfab が Run を生成する準備段階として、Data と入力を対応付ける方法、すなわち Nomination について説明しました。今回は、その続きのステップである Projection について解説します。さあ、Run が作られる様子を把握していきましょう!
この記事は、技術創発推進室のブログ "Keep Innovating! Blog" の転載記事です。
https://www.opst.co.jp/keep_innovating_blog/20240531_1/
Projection: 新しい Run を検出する
Nomination までは、入力と Data の関係がアサイン候補となるかどうかを考えました。それに続くステップである Projection は、Plan の入力とアサイン候補の組み合わせを考えて、漏れなく・重複なく Run を生成することを責務とします。
Run を生成するときには、Plan の各入力について、アサイン候補からそれぞれひとつ Data を選んで、入力の組み合わせを生成するのでした。

この入力の組み合わせに重複も、漏れもないようにしたいのです。
まず、「重複なく」が問題です。Knitfab では、Plan と入力が決まると Run が決まり、Run が決まると出力 Data の内容が決まる、と考えます。したがって、Run を生成するときに、既存の Run と同じアサインの仕方をしたような Run (等価な Run)が重複しないようにする必要があります。さもなくば、同じ出力を与える計算を何度も実行することになってしまい、無駄だからです。
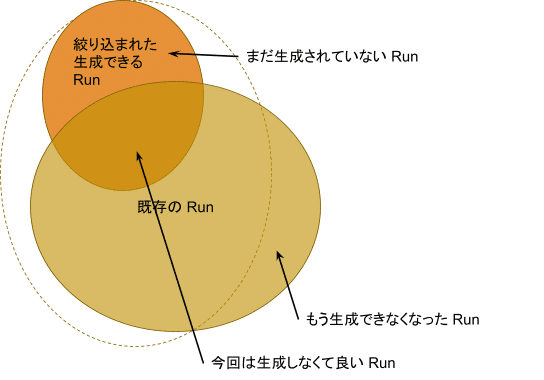
単純に考えれば「生成できる Run」を全部数え上げて、その中から「既存のもの」を取り除けば、「まだ生成されていないRun」がわかる、ということになります(図2)。

しかし、ここに「漏れなく」の難しさが関わってきます。組み合わせの問題であることが厄介なのです。
たとえば、 3 つ入力のある Plan があったとして、各入力に 10 個づつアサイン可能な Data があれば、10の3乗=1000 通りの Run が作られます。これを一度に計算しようと思うと時間とメモリを多量に消費しそうです。実際には、定期的に生成される Data を取り扱うとすると、もっと数は増えるでしょう。例えば、日次データを対象とすると、1 年間で 1 入力につき 365 個のデータがアサイン候補に挙がることになります。しかも、これは増えることはあっても、減ることはありません。とにかく全部数え上げる、ということは、簡単ではないのです。
こういうわけですから、全通りを揃えるにしても、一息でやらないようにしておきたいところです。少しづつ処理して、最終的に全部揃うようにしたいのです。その上で、重複なくやらなくてはいけません。
どうすればこの問題を解決できるでしょうか?
差分はどこにある?
一度に全部考えるのはうまくありませんから、必要がない部分は極力絞り込みをしつつ、処理を小分けにすることにします。
まずは絞り込みについて、「そもそも、新しい Run が生成されるきっかけとは何でしょう?」というところから、切り込んでいきましょう。その答えは「何らかの Data が、何らかの Plan の入力に新しくアサイン可能になったから」、すなわち Nomination の一覧に新しいアサイン候補が追加されたから、であるはずです。ということは、Projection は「新しく Nomination に追加されたアサイン候補をつかった Run」について考えれば十分だ、ということがわかります。新しく生成すべき Run は、新しいアサイン候補と、新しいアサイン候補の入力以外の入力の既存のアサイン候補の全組み合わせの中に含まれているはずです。

たとえば、Data#A, Data#1, Data#2 がPlan の入力にアサイン可能であるときに、新しく Data#B が追加されたとしましょう(図3.)。このとき新しく生成すべき Run の各入力は:
新しいアサイン候補を得た入力 = 上側の赤い入力: Data#B のみ
それ以外の入力 = 下側の青い入力 = 既存のアサイン候補すべて
から作れる組み合わせをすべて考えれば、カバーされているはずだ、ということです。
このように、Projection のきっかけとなった新しいアサイン候補を使うような Run についてだけ考えれば十分で、その時点で生成できるあらゆる Run についてまで考える必要はありません。
これで「生成できるRun」の範囲を絞り込むことができます(図4)。
都合の良いことに、この考え方は同時に「小分けにやる」を実現してもいます。というのも、「新しいアサイン候補」と「既存のアサイン候補」から生成すべき Run がすべてわかるなら、「新しいアサイン候補」を適当にひとつ取り出して順次 Run を生成していけば、いずれ「新しいアサイン候補」の全てについて Run を生成できるからです。一度に「新しいアサイン候補全て」について処理する必要もまた、ないのです。
差分はどこにしかない?
ところで、「新しく Nomination に追加されたアサイン候補をつかった Run」は、実は「まだ生成されていない Run」を含むのですが、同時に既存の Run を含んでいる可能性もあります。なぜならば、Kntifab ではData に対して Tag を貼ったり外したりすることができるからです。
次の図5-1. から 図5-4. のようなシナリオを考えてみましょう。




こういうわけなので、依然として「既存の Run」にないものに絞り込む、という処理が必要です。
「既存の Run」にないもの
生成しようとしている Run のうち、「既存の Run」にないものだけを実際に生成することにしましょう。「既存の Run」のなかから、生成しようとしている Run と等価な Run を探して、見つからなければ生成して良い、ということですね。
「既存の Run」がどんなものだったのか(それぞれ具体的にどんな Data をアサインされたか)ということは、もちろんリネージを調べればわかるはずです。しかも、Run の全探索は必要ありません。というのも、等価な Run にもこの Projection の起因となったアサイン候補が使われているはずなので、既存の Run のうちで、そのアサイン候補を使っているものだけを調べれば十分だから、です。

というわけで、1つの Run 候補に対して、等価な Run を探す範囲も絞り込むことができます(図6.)。
以上の考え方にしたがって、「生成できる Run」が「既存のRun」にあるのかどうか調べるために、次の SQL クエリを書きました。
with "assign_pattern" as (
select
unnest($1::int[]) as "input_id",
unnest($2::varchar[]) as "knit_id"
),
"run_ids" as (
select distinct "run_id"
from "assign"
where "plan_id" = $3 and "input_id" = $4 and "knit_id" = $5
),
"assign" as (
select * from "assign" where "run_id" in (table "run_ids")
),
"known" as (
select "run_id", count(*) as "overlapped"
from "assign"
where ("input_id", "knit_id") = any(table "assign_pattern")
group by "run_id"
)
select count(*) from "known"
where "overlapped" = (select count(*) from "assign_pattern")ここで、パラメータ $1 と $2 は入力のID と Data の識別子である Knit Id です。これらを、存在を確かめようとしている Run のアサインと対応するようにインデックスを揃えてクエリに渡します。配列を unnest することで列に展開して、1レコードがアサインしようとしている入力・Data 組になっている表を得ています( assign_pattern )。
$3 はRunの元となる Plan の ID、 $4 と $5 はこの Projection のきっかけとなったアサイン候補です。これらによって、Run の探索範囲を「同じ Plan のもの」であり、かつ「Projection のきっかけとなったものと同じアサインに関係する Run」である範囲に制限しています (run_ids)。
あとは、探索範囲の各 Run について assign_pattern と共有するアサインを数えて(known)、それが assign_pattern と同数かどうかを考えたらいいです(クエリ本体)。もし同数のものが見つかればクエリの結果は 1 になるので、そのパターンの Run はすでにある、とわかります。Nomination の考え方と似ていますね。
こうすることで、生成しようとしている Run が既存のものと同じかどうかを判断できるようになりました。つまり、「漏れなく、重複なく」Run を生成できるようになった、ということです。やりましたね!
この後
こうして Run を生成することさえできてしまえば、つまりどの Plan の入力に、どの Data を割り当てればよいか決まってしまえば、あとは簡単です。コンテナとして立ち上げて終了を待ちます。コンテナの終了を検出したら、その記録をデータベースに残してコンテナを削除します。 Run が出力 Data を持っていれば、またその Data は Nomination に回されるので、次の機械学習タスクをトリガーすることでしょう。
まとめ
「機械学習タスクを過不足なく自動実行する技術」と題して連載してきました。ここまでついてきてくださった皆さんには Knitfab の裏側を楽しんでいただけたのではないかと思います。
Knitfab の開発にあたっては、この「Run を漏れなく・重複なく生成する」という振る舞いを実現することが最重要のマイルストーンでした。これさえ正しく実装できれば、多入力・多出力をもつ機械学習タスクを自動実行すること、Knitfab の管理化で機械学習タスクを実行することですべてのリネージを追跡することにむけて大きく前進できるからです。
技術的には、タグ集合を比較することや入力のパターンを比較することが「共通部分を数える」という同様の方法論で実現できることを見てきました。可変長の要素をもった実体を SQL 的に表現するときの比較手法として、読者の皆様の参考になれば幸いです。
本連載はこれでおしまいです。また次のトピックでお会いしましょう!