
Tableau 2024.2新機能:Multi-Fact Relationshipsについて

こんにちは!少し前にTableau 2024.2で「Multi-fact Relationships」(あるいはShared Dimensions)という新機能が発表されました。これはデータ分析の幅を広げてくれる素敵な機能で、先日のTableau Conference 2024(=TC)のセッションでも紹介されていましたので、こちらについて書きたいと思います。
Multi-fact Relationshipsとは?
言葉の通り複数(Multi)のファクトテーブル(fact)を複数のディメンションテーブルをそれぞれリレーションシップで繋いで分析が可能になる機能です。
ここで、ファクトテーブル?ディメンションテーブル?となる方もいらっしゃると思いますので(私もはじめそうでした)、いったんこちらについて説明します。
ちゃんとした解説は色々な記事があるのでそちらに譲りたいと思いますが、辞書で以下のような記載がわかりやすかったので転記します。
https://eow.alc.co.jp/search?q=dimension+table

ファクトは直訳すると事実ですので、何が起こったか?という風に脳内変換していただくとわかりやすいかも?しれません。
ディメンションは直訳すると特徴という意味がありますので、事実に対してどのような特徴があるか?という風に捉えていただくとどうでしょうか。
なお、このファクトテーブルとディメンションテーブルで構成したデータモデリング(設計)をスタースキーマというものがあったりします。
Multi-fact Relationshipsで何ができるか?
ここまでMulti-fact Relationshipsとその構成要素について書いてきましたが、具体的にこの機能で何ができるのか書きたいと思います。
先日のTCでデモを交えてこちらの機能説明に関するセッションがありましたので、簡単に概要を記載します。
デモの実演をされた方が同様の内容をブログでまとめてありますので(英文)、併せてご参照ください。
デモではTableauのサンプルスーパーストアの分析を行いますが、いつものフィールドがすべて横に並んでいるファイル形式ではなく、実務に即した形で以下のようなデータモデリングの前提で行います。
(中身は基本的に同じで、おなじみのファイルを要素分解するとこんなテーブル形式で持つよね、とイメージしていただければ)
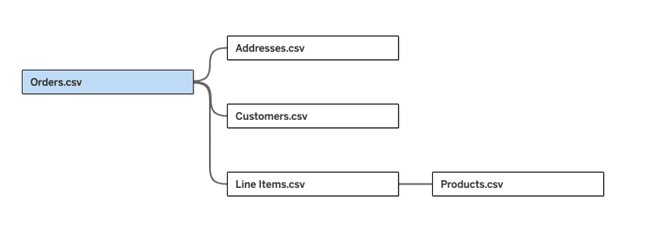
上記をもって分析を行うと下図の「東のテーブル」の利益が大問題(赤枠箇所)というインサイトが得られます。
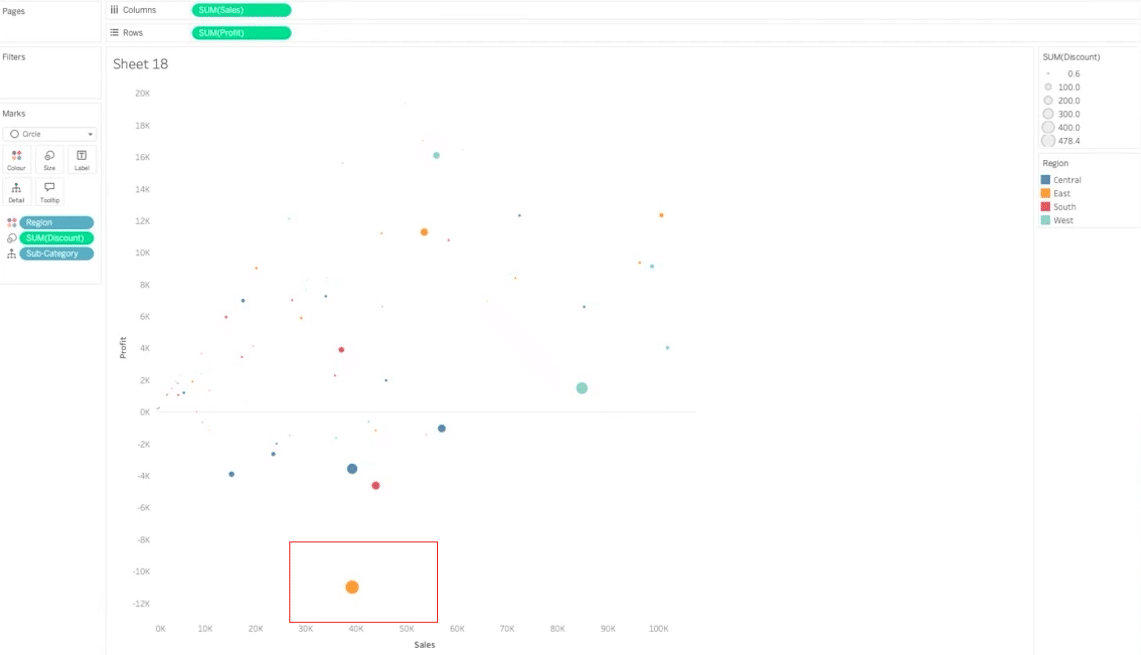
ただ、ここで東のテーブルがはなぜこのように低調なのかという疑問が当然浮かびます。
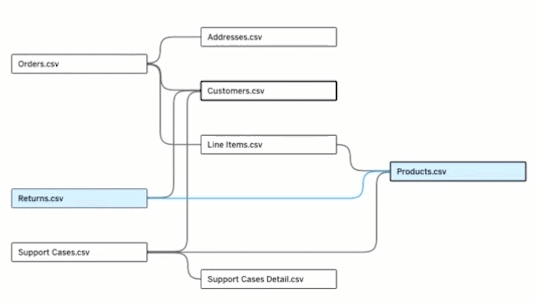
そこで顧客からのフィードバックのデータが記載されているサポートケース(Support Cases.csv)という新しいファクトテーブルを加えて、注文関連のファクトテーブルとの関係性について分析をしようとします。
※厳密に言うと、今回の事例においてOrders.csvはファクトテーブルではないようですが、注文関連とサポートケースの異なる2つのファクトテーブルを同時に分析するという意図には変わりありません。
しかし、Support Cases.csvを既存のモデルに繋げようとした場合、何と紐づけをすればよいのでしょうか?確かにCustomers.csvは共通のCustomerIDキーがあるので、それを介して繋ぐことも可能です。しかし、顧客軸以外に、例えば商品軸(Products.csv)で見たい場合はどうすれば良いでしょうか?
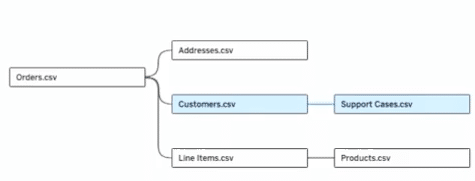
これまでのTableauのリレーションシップ機能ですと、残念ながら顧客と商品の複数テーブルを繋げることができません、

この課題を解決してくれたのが、今回のMulti-fact Relationshipsになります!
以下のような形で複数のファクトテーブルと複数のディメンションテーブルを共有することが可能になりました。(複数のディメンションを共有できるから”Shared Dimensions”とも呼ぶようです)
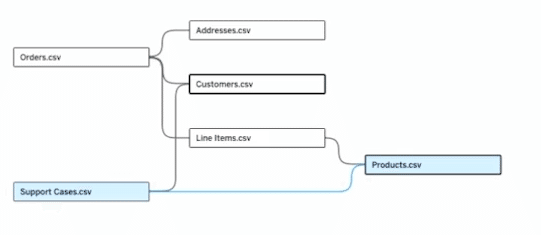
上記のようなモデリングが実現できたことで、販売数量に対してどの程度の割合でサポートケースが発生するかといった分析も可能になります。

上記はLine Items.csvとSupport Cases.csvからそれぞれ値を使用した計算式です。本題のテーブルの問題について改めて確認すると、確かにサポートケース頻度は高いですが(上から2番目)、それだけが原因ではなさそうです。
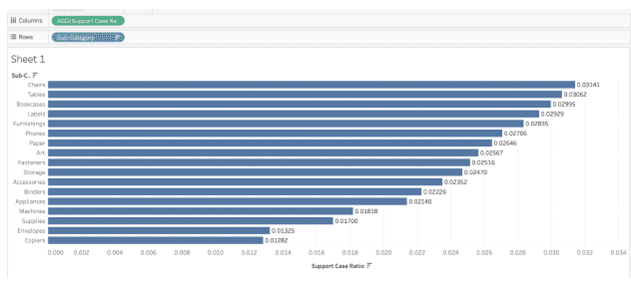
そこで次に返品データ(Returns.csv)をみてみます。こちらのデータは顧客と商品のテーブルと接続します。
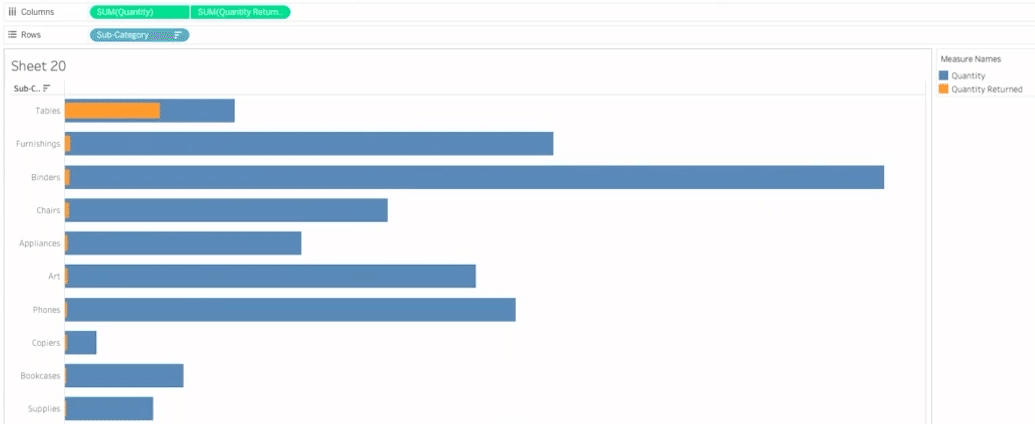
販売数量と返品数量をサブカテゴリ別で見てみると、一目瞭然でテーブルの返品数が圧倒的に多いことが分かります。では、なぜテーブルだけ返品数が高いのか・・・といったように本編ではさらに別テーブルをつないで深堀り分析のデモを行います。
(興味ある方はぜひ動画をご覧ください)
Multi-fact Relationships機能について今回TCのセッション動画で解説しましたが、以下の記事は内容を汎化し、かつ簡潔にまとめられていて分かりやすかったため、併せてご参照いただけると良いと思います。
Multi-fact Relationshipsを使うことで何が嬉しいのか?
ここまでこの機能でできることはある程度理解したものの、このメリットが何なのか?について少し書きたいと思います。
Multi-fact Relationshipsのデータモデリングを行うメリットとして、
ユーザビリティ改善
計算式が簡素化
性能改善
が挙げられます。
ここで、よくあるデータソースの代表例としてフィールドが横並びで1ファイルで完結する、いわゆる大福帳(Tableauのサンプルスーパーストアはまさしくそれです)のままでも問題ないのでは?と思われる方もいらっしゃると思います。
結論から言うと、データセットが小さい場合(と作りたいViz次第で)は大福帳でも上記3点は問題にならないことが多いです。今後もデータは増えないことがはっきりと決まっているのであれば、わざわざ今回のような機能を利用してデータモデリングをする必要はありません。
ただ、たいていの場合はデータが増えたり、あるいは別の切り口からデータを繋げたい、といったニーズが発生すると思います。
そうなったとき、例えばカラム数が50や100あるいはそれ以上に増えるとどうでしょうか?必要なカラムを探すのにも一苦労しそうで、ユーザビリティの問題が生じそうです。
また横に列が広がることでユーザビリティが損なわれるだけでなく、計算式を作成するのが大変になる可能性があります(ここは要件次第でどういったVizを作成したいかにもよりますが)。
性能面においては何億~何十億を1つのデータで持とうとすると、フィールドによっては同じ情報をただ繰り返すだけでリソースの無駄がどんどん蓄積していきます。その結果、Tableauのダッシュボードのパフォーマンスが劣化する可能性も高くなります。
上記観点についてPower BIの動画ではありますが、データモデリングを行う利点について分かりやすく解説されているため、こちらもご参照いただけると良いと思います。
(英語ですが、ご了承ください、、)
まとめ
いかがだったでしょうか。個人的にはこれまで以上にTableauで分析できる幅が広がったと思う一方で、データモデリングに関する理解、そして何よりデータやそのビジネスの理解がより一層重要になってくるなと思いました。
早速このMulti-fact Relationshipsを使ってみましたので、次回はそちらについて書きたいと思います!