
文字起こしAI「Whisper」でTwitterスペース音声を書き出してみた

■使用するツール・アプリケーション
ボイスレコーダー(Windows10標準搭載)
Google Colaboratory(Googleアカウントあればすぐ使用可能)
■文字起こしAI「Whisper」って?
きっかけは、議事録の作成が面倒で色々調べているうちに見かけた、こちらの記事でした。
10月31日(月):文字起こしAI「Whisper」、その精度と使いやすさは?
録音データからの文字起こしができるサービスが何かないか? と探していたところ、今年9月に発表された「Whisper」という文字起こしAIが、かなりの高精度で音声データのテキスト化を行ってくれるらしい。それも、以前に「Stable Diffusion」などの画像生成AIを使った時と同じように、Googleの「Colaboratory」上から無料で機能を利用できるようだ。
――急遽テレワークを導入した中小企業の顛末記(118)
Whisperって何?
WhisperはWebから収集した68万時間の多言語音声で学習した汎用音声認識モデルです。大規模で多様なデータセット使用することで過去のモデルと比べてロバスト性が向上しました。
なんかすごい音声認識モデルというやつらしい。
弊社では色々な制約のため使用できなかったものの、どれくらいの精度なんだろう?と試してみたくなりました。
■「Google Colaboratory」って?
「Colaboratory」というのも初耳だったので、調べてみました。
Google Colaboratoryとは
Google Colaboratory(グーグル・コラボレイトリーもしくはコラボラトリー)とは、Googleが機械学習の教育及び研究用に提供しているインストール不要かつ、すぐにPythonや機械学習・深層学習の環境を整えることが出来る無料のサービスです。Colab(コラボ)とも呼ばれます。無料で利用する事が出来ますが、Googleアカウントが必要になります。またCPU及びGPU(1回12時間)の環境が利用可能です。
環境構築とかアレコレしなくても、Googleアカウントがあれば簡単にPythonが試せるようになると。
これを使って「Whisper」なるものを使い、音声ファイルの文字起こしをする。なるほど!
1.音声ファイルを用意しよう!
じゃあ早速音声ファイルを……と思ったところで、作業するのは個人PCなので、本来使いたい議事録用の会議音声は手元にありませんでした。
手元に文字起こししてみたい音声ファイルがあるよ!という方はここは飛ばしてください。
(1)Twitterスペースを音声ファイルにしたい!
毎週水曜日、朝8時から30分、Twitterスペースにて開催されている「外資ITサバイバル英語」。
こちらは録音したものを公開してくださっていて、これを音声ファイルとして保存して文字起こしすれば勉強にも使えそうだしいいんじゃない?と思い立ちました。
しかし調べてみると、ホストの方はアーカイブダウンロードできるようなのですが、普通の視聴者は少なくとも公式アプリ等ではダウンロードできなさそう……。
(2)ボイスレコーダーでPC内部音声を録音できる!
質問
Windows 10のボイスレコーダーで、パソコンから再生されている音声を録音する方法を教えてください。
回答
パソコンから再生されている音声は、ステレオミキサーを有効にしてボイスレコーダーから録音を行います
録音する方法を教えてください。
Windows10搭載の「ボイスレコーダー」で何とかなりそうだったので、これを使いました。
記事中の画像の通りにするだけだったので、とても分かりやすかったです。
なお、ステレオミキサーのレベルは「100」にしました。

注意!
このPCでZOOMなどマイクを使って通話している方は、ステレオミキサーの有効化をオフにしてマイクに戻しておかないと自分の声が相手に届かなくなったりするかと思いますので、終わったら元に戻すようにしたほうがいいかなと思います。
(3)実際にやってみた!
ステレオミキサーの設定が完了したので、「ボイスレコーダー」を開いてみます。
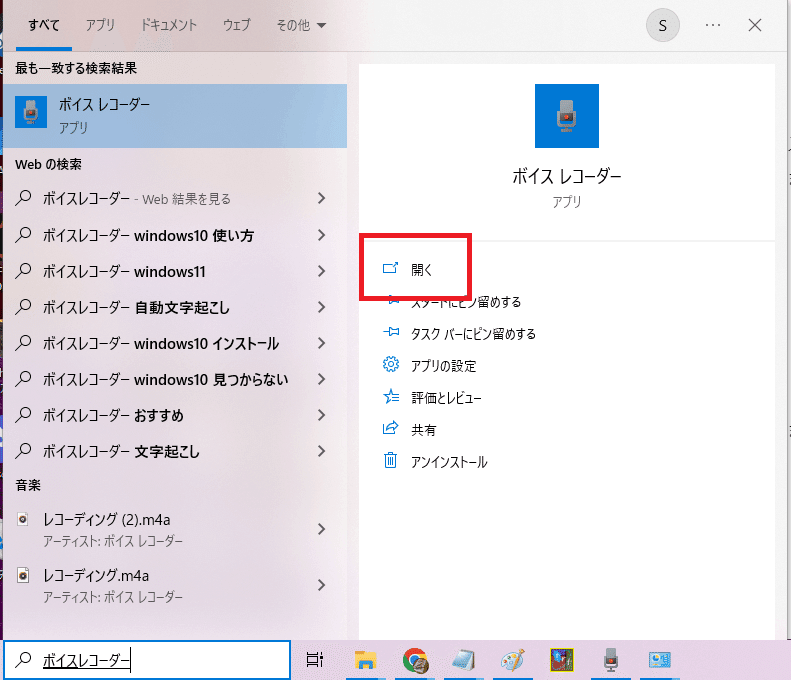

録音開始はちょっと待って、次はこちらのスペース録音URLを開きます。

「ボイスレコーダー」で録音開始→Twitterスペースの「録音を再生」でスペースの音声を録音していきます。
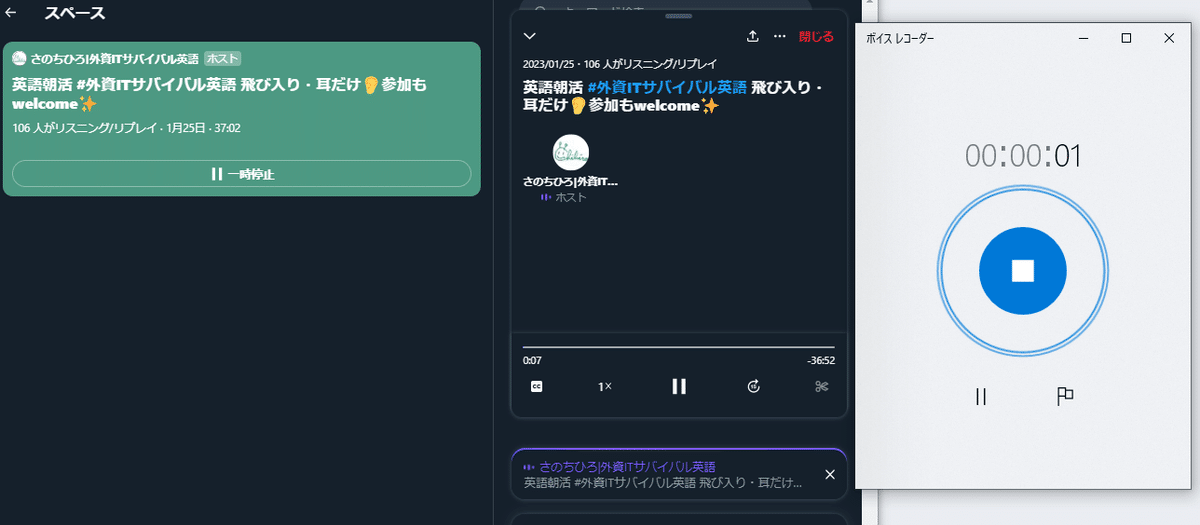
スペースの録音時間は30分ほどあるので、とりあえず今回はお試し用として、冒頭25秒くらいまでを録音します。
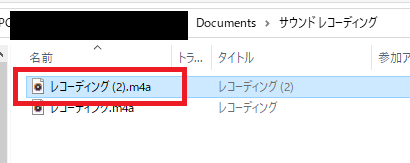
ボイスレコーダーの「■」ボタンで録音内容がファイル化されます。
今回のは図の「レコーディング(2)」になります。


これで書き起こしに使用する音声ファイルの準備ができました!
2.「Colaboratory」の準備をしよう!
(1)ログインしよう!
Googleアカウントを持っている人は、そのままログインしてください。
持ってない人はアカウント作成からになりますが、ここでは割愛します。
(2)ノートブックを新規作成しよう!
ここからは、上記で貼った記事に記載されたことをほぼそのままやっていきます。

上の画面を間違って閉じちゃった!というときはファイルからも新規作成できるので大丈夫です。

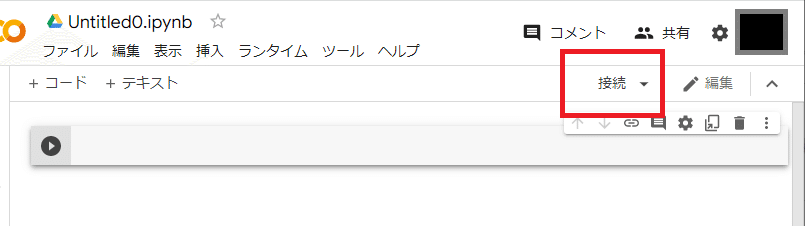
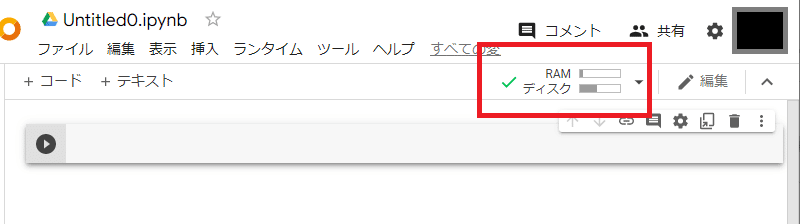
(3)ランタイム接続をしよう!



(4)音声ファイルをアップロードしよう!


ちなみに音声ファイルの場所は、ボイスレコーダーから対象のファイルを右クリックして出るメニューで保存先を開けます。



アップロードできたら、音声ファイルのパスを取得して、テキストファイルなどにメモしておきます。

3.コードをコピペで貼り付けよう!
元記事で公開いただいているコードをそのまま貼り付けていきます。
(1)1行目:Whisperのインストール
まず1行目にこのコードをコピペで貼り付けます。
!pip install git+https://github.com/openai/whisper.git次に、行を追加します。
左上の「+コード」ボタンでも、行の下あたりにカーソルを持ってきた時に表示される「+コード」ボタンでも、どちらでもよいです。

(2)2行目:インポート
2行目にこのコードをコピペで貼り付けます。
import whisper
(3)3行目:モデルサイズのロード
また行を追加して、3行目にこのコードをコピペで貼り付けます。
ここで注意なのが「()」や「""」がちゃんと半角になっていることです。
ブログ等の仕様でこれらの記号が全角になってしまっているとき、知らずにコピペして「えっなにこれエラー出たんだけど!?」とかなったりします。なりました。
ちなみに、「large」というのは一番精度がいいモデルサイズです。
精度順に「tiny < base < small < medium < large」となっているようです。
精度がいい分、読み込みに少し時間がかかります。
model = whisper.load_model("large")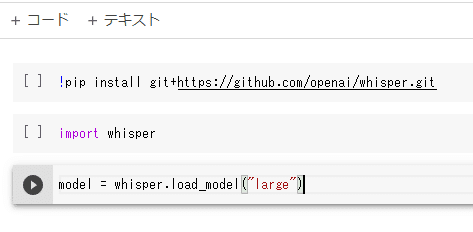
(4)4行目:音声ファイルの読み込み
行を追加して、4行目にこのコードをコピペで貼り付けます。
result = model.transcribe("音声ファイルのパス")この「音声ファイルのパス」には、音声ファイルをアップロードしたときにコピーしておいたパスを入れてください。
恐らく「/content/レコーディング (2).m4a」のようになっていると思います。

(5)4行目の続き:文字起こし結果の書き出し
今度は行を追加せず、4行目をEnterキーで改行してコードを追記します。
print(result["text"])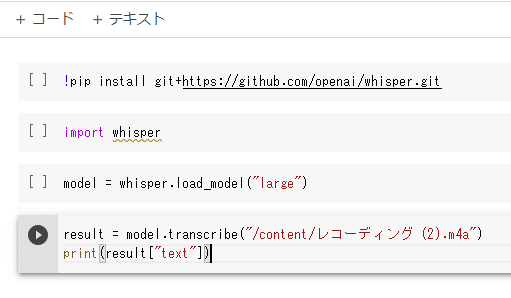
これでコードの準備ができました!
4.文字起こしを実行しよう!
あとは、上から順番にコードを1行ずつ実行していきます。
本来は行ごとに記述→実行→次の記述……でいいと思いますが、この記事では全部コードを書いてから実行します。
コードの実行は、行の右端の[ ]にカーソルを持っていくと再生ボタンになるので、これをクリックすればOKです。
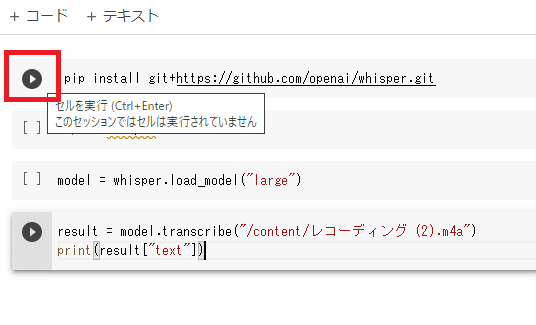




「large」サイズを選んでいると少し時間がかかる

25秒くらいの音声ファイルだと、14秒ほどで文字起こしが完了します。
(後ほど35分のファイルで試したら、約8分で14,000字ほど文字起こしされました。)

5.書き起こし結果発表!
(1)書き起こされたテキストを見る
赤枠の部分を全選択してコピーし、テキストファイルに貼り付けました。

ちゃんと英語の発音の部分は英語に、日本語の部分は日本語になっていますね。
改行は自動ではつかないので、手動で整えていく必要があります。
(でも最後の「ご視聴ありがとうございました」、音声では言ってないのになぜ入っているのか……?)
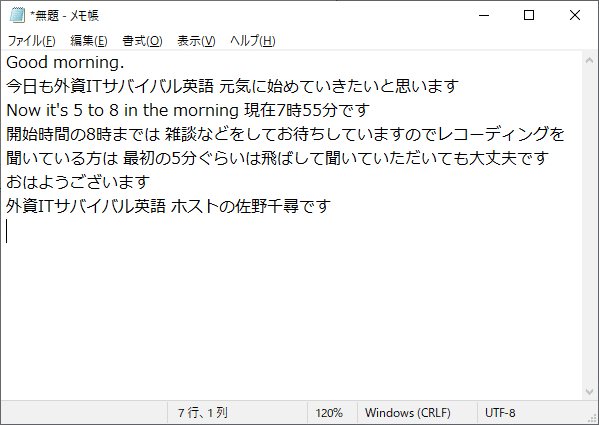
「it's 5 to 8」の「to」の部分はちょうどTwitterスペースの接続が一瞬途切れたところです。
全体的にはかなり正確に、意味の繋がるように書き起こしされていました。
しっかり漢字も違和感なく変換されていてすごいですね。
(2)思ったよりもかなり簡単
Pythonの知識はほぼなく、完全に見たままコピペしただけのコードでしたが、こんなに簡単に文字起こしできました!
しっかり勉強すればもっともっと使いやすくなりそうですし、自動化も視野に入ってきそうです。
でも、使用頻度的にそう多くなければ、このレベルでも割と十分だよな~とも思います。
最後に
今回、この記事に書くにあたって、スペースの録音データの使用を快く了承くださった「#外資ITサバイバル英語」のさのちひろ様(@IQ_Bocchi)に厚く御礼申し上げます!
今週の水曜日も朝8時からスペース開かれる予定です。
Twitterアカウントなくても、上のハッシュタグのリンクからタグのタイムラインが見れますし、ツイートのスペースの直リンクを踏めばアカウントなくてもスペース聴けるようなので、まだお聴きになったことがない方は是非。
(ここまで閲覧くださるような方で、未視聴の方っていらっしゃるのかなあ……)