
SARIMA分析とLSTM分析の精度比較 -インドSENSEX30の為替予測- :(x2004-Aidemy成果物2)

はじめに
この成果物は、Aidemyを受講した6ヶ月の学習成果を客観視することを目的として作成した。この6ヶ月の間には、申し込みをした「データ分析」だけでなく「E資格」「AIアプリ開発」「自然言語処理」と、可能な限り利用ができる講座を受講し様々な知識を学んだ。
一通りの学習を終え、Aidemyの受講目的を振り返った際、本来の目的は「自分の新しいキャリア形成」であり、「IT・AIの世界で活躍するための土台をつくる」ことであることを再確認した。
この受講目的が達成されているかを確認するための”問題の所在”となったのは、「学んだ知識をどのように実社会(=仕事)に活かしていくか」であり、「どのように自身のスキルアップを図っていくか」であると考えた。
そこで、6ヵ月の学習の成果をポートフォリオにまとめることにした。
この”問題の所在”に対し、どのようなアプローチをするか考えた際、修士学生の時に専攻した経済史で研究テーマとした「イギリス-インド帝国の対外貿易をはじめとした政策の変遷」にヒントとしてテーマを探した。
そして、メディアで紹介されることもある「今後もインドは経済成長を続けていく」という観点に疑問を持ったことから、「インドの経済成長」をテーマとして成果物を作成することにした。
この成果物を作成するにあたり、「どのような観点から経済成長を定義するか」について多くの時間を要した(専攻していた経済史では、「経済成長=経済面を中心と社会変化」を論ずる際、「生活水準」や「貿易内容の推移」、「金融の成長」、「統計観点から見た人口推移」、「経済に関連する政策との関連による社会変化」など様々な観点がある)。
どの観点から成果物を作成するかが、今後の自分の”仕事”や”スキルアップ”に対して1つの基準となると考えたため、テーマの設定に2週間ほどかけた。(Kaggleを使って、インドに関するレポートを読み漁った)
上記に加えて、今の自分のPythonを使う能力や引用が可能なデータベースの有無などを考慮した結果、「インドSENSEX30"の為替予測」をテーマとしたデータ分析の成果物を作成することを、Aidemyを6ヵ月受講した成果として製作・発表することにした。
1.目的
ⅰ) インドSENSEX30の為替推移を基にインド経済の成長ついて考察をする。為替推移を扱うにあたり、時期を3つに分けて分析を行い、まずは各時期に対して予測を行い、予実比較を行う。
ⅱ) その上で、手法の異なる予測による予測精度の比較を行い、将来の為替の成長性について考察をする。
・今回は上記2点に注目した上で、インド経済の成長と今後の成長性を考察する。
2.分析手法・時期・実行環境
1) 手法
為替推移に対する手法として、 Yahoofinanceから引用したインドSENSEX30(^BSESN)データをもとに、下記2点の手法の異なる予測を行い、予実比較/精度比較について考察を行う。
ⅰ) SARIMA分析による時系列予測…4節で紹介
ⅱ) LSTMによる予測…5節で紹介
ⅲ) SARIMA分析の結果 と LSTMの結果 の精度比較…6節で紹介
2) 検証を行う時期の区分
考察を行うにあたり、以下の3つの時期に分けて考察を行った。
時期の区分については、以下の表を参照のこと。
① 2000~2013年(~リーマンショックの影響が終わるまで)
② 2014~2022年(~コロナウイルスの大規模蔓延が終わるまで)
③ 2019~2024年(~24年末まで)

3) 実行環境
・Google Colaboratory
・python3
3.データ分析の準備
この節では、インドSENSEX30(^BSESN)の分析の準備として、Yahoofinanceから引用したデータ整理とグラフ化の紹介をする。
今回は、このデータ整理と整理によって出力した グラフ(1) をもとに、次節以降でSARIMA分析やLTSM分析を行った。
以下は、データ整理とグラフ化の際に用いたコード/出力したグラフやデータフレームになる。
ⅰ) Yahoofinanceのインポート準備
#YahooFinanceのインポート準備
!pip install mplfinance japanize-matplotlib
ⅱ) ライブラリのインポートとグラフ表示の設定
#ライブラリのインポート(YahooFinance参照)
import yfinance as yf
from datetime import datetime
df= yf.download("^BSESN").dropna() #SENSEX
import pandas as pd
import itertools
import matplotlib.pyplot as plt
#データの取得期間 -- Export-Importとyfが重複する期間を対象とする(1997/7から当日まで)
st = "1997-07-01"
ed = "2024-05-31"
# 株価の終値データを抽出
close_prices = df['Close'] # 適宜、終値の列名を変更してください
# 年ごとの終値の平均を計算
annual_mean_close = close_prices.resample('Y').mean()
# グラフのサイズを設定
plt.figure(figsize=(10, 6))
# 折れ線グラフを描画
plt.plot(annual_mean_close.index, annual_mean_close.values, label='Annual Mean Close Price', color='blue')
# グラフのタイトルとラベルを設定
plt.title('Annual Mean Stock Close Price')
plt.xlabel('Year')
plt.ylabel('Mean Close Price Yen')
plt.legend()
# グラフを表示
plt.show()
ⅲ) データフレームインデックスの表示
#DatetimeIndexのコード
df
print(df.index)
print(df.columns)
ⅳ) データフレームを ”始値” "高値" "安値" ”終値” ”出来高”で表示
・この後のデータ量が多く処理に時間がかかるを考慮し、月足でデータフレームをまとめた
#dfの一覧
df = df.asfreq("M",method="ffill")
df
この処理を通じて、Yahoofinanceから引用したデータの整理とグラフ化を行い、次節の分析結果がどのような結果を表しているかを検証する土台を完成させた。
次節では、この土台を基にしてSARIMA分析とLSTM分析を行う。
4.SARIMA分析
この節では、SARIMA分析を用いた為替予測を行い、以下の2点について検証を行い、これらの結果をもとに実績と予測の乖離について考察をする。
前提: 1997年7月~2024年5月末までのグラフを作成(このグラフを基準として考える、3.データ分析の準備を参照のこと)
(ⅰ) 過去の為替実績をもとに、”過去の実績” vs "過去実績をもとに行った予測"の比較
① 2000~2013年(リーマンショック前の実績に基づく予測vsリーマンショックが起こった後の予測/実績)- グラフ(A) vs グラフ(B)
② 2014~2022年(コロナウイルス蔓延前の実績に基づく予測vsコロナウイルス蔓延が落ち着いた頃の予測/実績)- グラフ(C) vs グラフ(D)
(ⅱ) 24年5月末までの実績をもとに、24年末まで予測
③ ”2019~2024年5月末までの実績をもとに予測” vs ”1997~2024年5月末までの実績をもとに予測” - グラフ(E) vs グラフ(1-2)

1) SARIMA分析の紹介
「SARIMA分析とは何か」について、Aidemyの講座[時系列解析Ⅰ(統計学的モデル - 4.1.1 ARIMAモデルの復習]を参考として簡潔に説明をする。
SARIMAモデルとはARIMAモデルをさらに季節周期を持つ時系列データにも拡張できるようにしたモデルである。ARIMAモデルが以前の値に影響されるモデルであり、直前p個の値と相関をもつようなARモデル𝐴𝑅(𝑝)AR(p)と、以前の誤差に影響されるモデルで直前q個の値の影響を受けるようなMAモデル𝑀𝐴(𝑞)MA(q)を合成した𝐴𝑅𝑀𝐴(𝑝,𝑞)ARMA(p,q)を、d時点前の階差系列に適応したものであるのに対し、SARIMAモデルはARIMAモデルに季節周期を持つ時系列データにも拡張できるようにした事で、ARIMAモデルで(p, d, q)のパラメーターに対応していたのに加えて、(sp, sd, sq, s)というパラメーターにも対応できるようになっている。

2) 3つの時期区分の検証
① 2000~2013年(リーマンショック前の実績に基づく予測vsリーマンショックが起こった後の予測/実績)
ここでは、2000~2013年の時期を対象とした「リーマンショック前の実績に基づく予測vsリーマンショックが起こった後の予測/実績」について、整理を行う。
方法としては、以下のように行った。
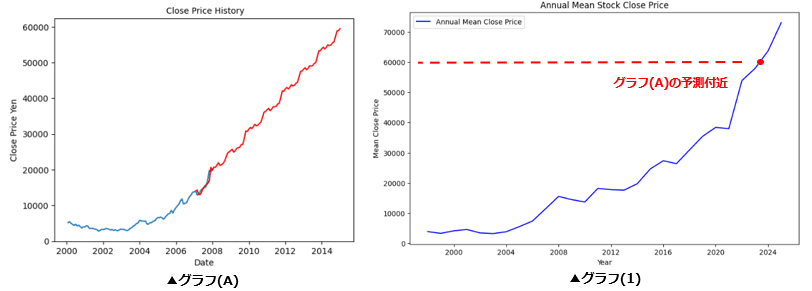
(A) リーマンショック前(=2007年まで)の為替実績をもとに2014年までの為替予測を行う。※以降の表記は(A)とする。
(B) リーマンショック収束後(=2013年まで)の為替実績をもとに2014年の為替予測を行う。 ※以降の表記は(B)とする。
(A) リーマンショック前(=2007年まで)の為替実績をもとに2014年までの為替予測 (作成するグラフは グラフ(A) とする)
(A)- 2000年1月~2007年12月末までのグラフを作成
#Case-(A) グラフ出力-2000∼2007年
import datetime
df= df["2000-01":"2007-12"]
#共通コード1 … 以下のコードはグラフ(B)~(E)共通のため、グラフ(B)以降は(共通コード1と記載)
# 株価の終値データを抽出
close_prices = df['Close'] # 適宜、終値の列名を変更してください
# 年ごとの終値の平均を計算
annual_mean_close = close_prices.resample('M').mean()
# グラフのサイズを設定
plt.figure(figsize=(10, 6))
# 折れ線グラフを描画
plt.plot(annual_mean_close.index, annual_mean_close.values, label='Annual Mean Close Price', color='blue')
# グラフのタイトルとラベルを設定
plt.title('Month Mean Stock Close Price')
plt.xlabel('Month')
plt.ylabel('Mean Close Price Yen')
plt.legend()
# グラフを表示
plt.show()
#DatetimeIndexのコード 詳細は割愛
df
print(df.index)
print(df.columns)
#dfの一覧 詳細は割愛
df = df.asfreq("M",method="ffill")
df
(A)- SARIMA分析による2008~2014年までの予測モデル
#Case-(A) SARIMA分析
#共通コード2 … 以下のコードはグラフ(B)~(E)共通のため、グラフ(B)以降は(共通コード2と記載)
#SARIMAの前準備
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
#SARIMAモデル
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
#from pandas import datetime
import numpy as np
import warnings
warnings.filterwarnings('ignore')
#モデル導入の前段階
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)]
# モデルの当てはめ
#SARIMA_ = sm.tsa.statespace.SARIMAX(df["Close"],order=(0, 0, 0),seasonal_order=(0, 1, 1, 12)).fit()
best_params = selectparameter(df["Close"], 12)
SARIMA_ = sm.tsa.statespace.SARIMAX(df["Close"], order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()#グラフ(A)の出力
# predに予測データを代入する
pred = SARIMA_.predict("2007-01", "2014-12")
# 実測値と予測値をグラフに反映
plt.plot(df["Close"])
plt.plot(df["Close"].loc["2014-12":], "b")
plt.plot(pred, "r")
plt.title(' Close Price History', fontsize=10)
plt.xlabel('Date', fontsize=10)
plt.ylabel('Close Price Yen', fontsize=10)
plt.show()
(B) リーマンショック収束後(=2013年まで)の為替実績をもとに2014年の為替予測 (作成するグラフは グラフ(B) とする)
(B)- 2000年1月~2013年12月末までのグラフを作成
#Case-(B) グラフ出力-2000∼2013年
import datetime
df= df["2000-01":"2013-12"]
#以下、共通コード1を参照のこと
(B)- SARIMA分析による2000~2013年を基にした2014年の予測モデル
#Case-(B) SARIMA分析
#以下、共通コード2を参照のこと#グラフ(B)の出力
# predに予測データを代入する
pred = SARIMA_.predict("2008-01", "2014-12")
# 実測値と予測値をグラフに反映
plt.plot(df["Close"])
plt.plot(df["Close"].loc["2014-12":], "b")
plt.plot(pred, "r")
plt.title(' Close Price History', fontsize=10)
plt.xlabel('Date', fontsize=10)
plt.ylabel('Close Price Yen', fontsize=10)
plt.show()
② 2014~2022年(コロナウイルス蔓延前の実績に基づく予測vsコロナウイルス蔓延が落ち着いた頃の予測/実績)
ここでは、2014~2022年「コロナウイルス蔓延前の実績に基づく予測vsコロナウイルス蔓延が落ち着いた頃の予測/実績」について整理を行う。
方法としては、以下のように行った。
(C) コロナウイルス蔓延前(=2018年まで)の為替実績をもとに2023年までの為替予測を行う。 ※以降の表記は(C)とする。
(D) コロナウイルス蔓延が落ち着いた頃(=2022年まで)の為替実績をもとにした2023年の為替予測を行う。 ※以降の表記は(D)とする。
(C) コロナウイルス蔓延前(=2018年まで)の為替実績をもとに2023年までの為替予測 (作成するグラフは グラフ(C) とする)
(C)- 2014~2018年までのグラフを作成
#Case-(C) 2014∼2019年
import datetime
df= df["2014-01":"2019-12"]
#以下、共通コード1を参照のこと
(C)- SARIMA分析による2019~2023年までの予測モデル
#Case-(C) SARIMA分析
#以下、共通コード2を参照のこと#グラフ(C)の出力
# predに予測データを代入する
pred = SARIMA_.predict("2019-01", "2022-12")
# 実測値と予測値をグラフに反映
plt.plot(df["Close"])
plt.plot(df["Close"].loc["2022-12":], "b")
plt.plot(pred, "r")
plt.title(' Close Price History', fontsize=10)
plt.xlabel('Date', fontsize=10)
plt.ylabel('Close Price Yen', fontsize=10)
plt.show()
(D) コロナウイルス蔓延が落ち着いた頃(=2022年まで)の為替実績をもとにした2023年の為替予測 (作成するグラフは グラフ(D)とする)
(D)- 2014~2022年までのグラフを作成
#Case-(D) 2014∼2022年
import datetime
df= df["2014-01":"2022-12"]
#以下、共通コード1を参照のこと
(D)- SARIMA分析による2014~2022年を基にした2023年の予測モデル
#Case-(D) SARIMA分析
#以下、共通コード2を参照のこと#グラフ(D)の出力
# predに予測データを代入する
pred = SARIMA_.predict("2019-01", "2022-12")
# 実測値と予測値をグラフに反映
plt.plot(df["Close"])
plt.plot(df["Close"].loc["2022-12":], "b")
plt.plot(pred, "r")
plt.title(' Close Price History', fontsize=10)
plt.xlabel('Date', fontsize=10)
plt.ylabel('Close Price Yen', fontsize=10)
plt.show()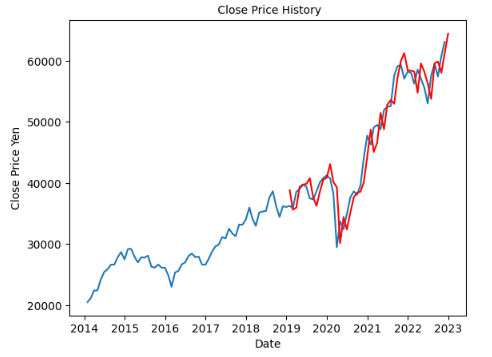
③ 24年5月以降の予測
24年末までを予測(作成するグラフは グラフ(E) と グラフ(2) する)
(E) 2019年~2024年5月末までの実績をもとに、2024年12月末までを為替予測 (作成するグラフは (グラフE) とする)
(E)-2019年~2024年5月末までのグラフを作成
#Case-(E)-2019∼2024年
import datetime
df= df["2019-01":"2024-12"]
#以下、共通コード1を参照のこと
(E)-SARIMA分析による2019年~2024年5月末をもとにした、2024年の予測モデル
#Case-(E) SARIMA分析
#以下、共通コード2を参照のこと#グラフ(E)の出力
# predに予測データを代入する
pred = SARIMA_.predict("2023-05", "2024-12")
# 実測値と予測値をグラフに反映
plt.plot(df["Close"])
plt.plot(df["Close"].loc["2023-05":], "b")
plt.plot(pred, "r")
plt.title(' Close Price History', fontsize=10)
plt.xlabel('Date', fontsize=10)
plt.ylabel('Close Price Yen', fontsize=10)
plt.show()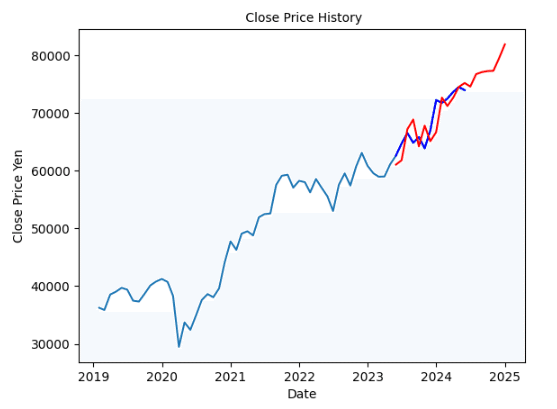
グラフ(2) 1997年7月~2024年5月末までの実績をもとに、2024年12月末までを為替予測 (作成するグラフは グラフ(2) とする)
グラフ(2)- 1997年7月~2024年5月末までの実績をグラフ作成
#Case-(グラフ2) 2019∼2024年
import datetime
df= df["1997-07":"2024-05"]
#以下、共通コード1を参照のこと
グラフ(2)- 1997年7月~2024年5月末までの実績を基にした、2024年12月末までの予測モデル
#Case-(グラフ2) SARIMA分析
#以下、共通コード2を参照のこと#(グラフ2)の出力
# predに予測データを代入する
pred = SARIMA_.predict("2023-05", "2024-12")
# 実測値と予測値をグラフに反映
plt.plot(df["Close"])
plt.plot(df["Close"].loc["2023-05":], "b")
plt.plot(pred, "r")
plt.title(' Close Price History', fontsize=10)
plt.xlabel('Date', fontsize=10)
plt.ylabel('Close Price Yen', fontsize=10)
plt.show()
3) 検証結果に対する考察
ここでは、上記の グラフ(A)~(E), グラフ(2) の予測結果をもとに、アプローチした条件が異なるグラフの共通点や課題となる点について言及を行う。
◆ グラフ(A) と (B) の比較による考察

■問題提起)
グラフ(A) と (B) の比較をした場合、以下のことが検証が必要と考える。
(1) グラフ(A) の予測は、正しく学習できているか
⇒正しく学習できていた場合、問題点はどのようなものになるか
(2) グラフ(B) のリーマンショックの影響は、正しく学習できているのか
⇒正しく学習できていた場合、問題はどこにあるか
■問題提起に対する考察
(1) グラフ(A) の予測は、正しく学習できているか
問題点は、上昇する幅が大きい(2007年から2014年で約3倍の成長)
=約3倍の成長は実体を伴う成長なのか("バブル経済"の疑い)
(2) グラフ(B) リーマンショックの影響は、正しく学習できているのか
問題点は、下落幅が大きい(2008年から2009年で約1/2倍の下落)
=リーマンショックの影響が凄まじいものであり、2013年前後の時点では”外れ値”として考える事も方法の1つである。
■ グラフ(A) と (B) の比較に対する結論
・リーマンショックがないとした場合、"バブル経済"の疑いがある。
⇒ 実体の伴っていない経済成長、それに伴うリスクが考えられる。
・リーマンショックの影響を考慮して予測をした場合、リーマンショックの経済への影響の大きさを表していると言える。
⇒ リーマンショックを考慮するか否かで、「経済の動きの捉え方」が 180度 変わる。
◆ グラフ(C) と (D) の比較による考察

■問題提起
グラフ(C) と (D) の比較をした場合、以下のことが検証が必要と考える。
(1) コロナウイルスが蔓延しない事を想定した グラフ(C) の予測結果に対し、コロナウイルスが蔓延した後の実績で予測をした グラフ(D) の方が予測された価格が高いの何故か?
⇒ コロナ前とコロナ後の、経済政策の変化(コロナ対策)による影響なのか
(2) グラフ(D) の2022~2023年前後に価格が伸び悩んでいるのは何故か?
⇒ 世界各国のコロナ蔓延の落ち着きによる経済活動再開の影響?
■問題提起に対する考察
(1) グラフ(C) はコロナ前に決定した経済政策の効果を予測しているのか?
・学習期間が5年という点を考えると、経済政策の効果を予測していると考える事は出来る。
・また、 グラフ(D) より予測価格が低いのは、諸外国もコロナの影響がないと考えるため、コロナ前にインドと比べ投資が集中した国があった場合、投資の度合いによる差がグラフに反映されたと考察できる。
(2) グラフ(D) の2022~2023年前後に価格が伸び悩んでいるのは何故か?
・ グラフ(C) に対する考察を踏まえ、また2020年から2021年にかけての 急激な上昇を考慮すると、世界各国のコロナショック発生直後の経済政策とそれに対する投資需要の変化が生じたと考えられる。(インドは経済成長を優先した結果、コロナショック中に感染防止を優先した国に比べ投資需要が高かったため、為替が上昇したと考えられる)
・その後、世界的にコロナショックが落ち着いた後は、コロナにより一時的に過熱したインドへの投資が、他の投資先へ移ったと考える事が出来る(利益確定などの影響も含む)。
■ グラフ(C) と (D) の比較に対する結論
インドの為替成長への期待はコロナ前から高かったが、コロナ前はインドよりも為替成長への期待が高い国があり、コロナショックによってその国より為替成長への期待が一時的に高まったのではないだろうか。
つまり、以下の点が グラフ(C) と (D) の比較に対する結論と考えている。
(1) その国の経済の成長段階と優先した政策による投資需要の違いがあった。
(2) 各国の政策内容による短期的な投資需要の増減による変化があった。
(3) コロナウイルスへの対応の考え方の変化による違い
◆グラフ(E) と グラフ(2) の比較による考察
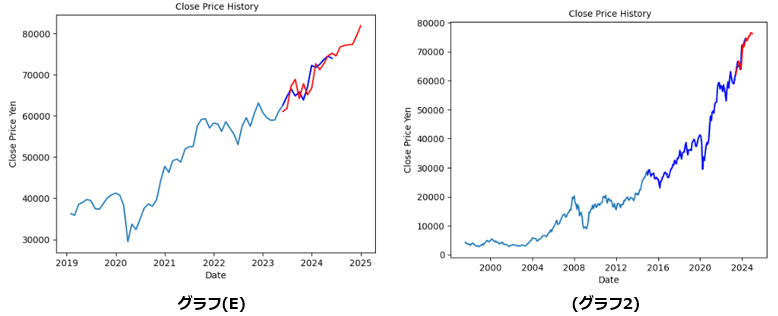
■問題提起
グラフ(E) と グラフ(2) の比較をした場合、以下のことが検証が必要と考える。
グラフ(E) の学習期間が約5年であるの対し、グラフ(2) の学習期間は約25年ほどある。しかし、2つのグラフの予測は80,000円前後を予測している事を考えると、学習期間の差があるにも関わらず予測差は小さいのではないかという疑問が生じる。
この疑問について、以下で検証をしていく。
■問題提起に対する考察
学習期間の差があるにも関わらず、予測差は小さい理由は何故か?
・学習期間の差が約20年という点を考えると、差だけで考えたら予測値も大きな差があっても当然であると考えることも出来る。
・だが、実態としては予測値の差は小さい。なので、実態に沿って考えると「何かしらの要因」が作用して、予測値の差が小さい結果となったと考えるのが自然な考え方なのではないか。
■ グラフ(E) と グラフ(2) の比較に対する結論
グラフ(E) と グラフ(2) の場合、予測のベースとなるdfの対象期間を異なった形で予測を行っているため、この違いが偶然にも近しい予測値を算出したと考えるのが妥当ではないだろうか。
つまり、2019年以降の為替上昇の学習データと、1997年∼2024年までの為替上昇の学習データが似通ったものとなった事が、学習期間の差があるにも関わらず予測差が小さい要因となっているのではと考えている。
4) この節のまとめ
同じ時系列に対して2種類の観点からSARIMA分析をして結果の比較を行ったところ、以下のことが指摘できると考えている。
(1) 経済状態の認識について
・ グラフ(A) のリーマンショックがなかったとした場合の予測結果の考察
⇒ バブル経済の状態と捉える事が出来るためバブル崩壊が予想できる。
・ グラフ(B) のリーマンショック後を考慮した予測結果の考察
⇒ リーマンショックを1つのバブル崩壊と考えると、グラフ(A) で考察できたバブル崩壊が起こった結果と考えることは出来ないだろうか。
(2) 国内向け/対外向け経済政策の有無による、為替の動きが発生
コロナ対策については、各国の対策に差が生じた(国内感染の防止を優先する国や経済成長を優先する国など)ことが、グラフ(C) と (D) の予測結果の違いを生じさせたのではないだろうか。
(3) グラフ(E) と (グラフ2) の予測結果について検討する場合
上記(1)~(2)を踏まえるとアメリカ中央銀行による利下げが警戒される中での予想となるため、 利下げの影響≒リーマンショック/コロナとなる可能性もあり得るのではないだろうか。
今回は為替価格が上昇するグラフのみの作成となったが、価格が下落しているグラフも併せて作成することが今後は必要とされるだろうと感じている。(※利下げの影響の程度は分からないため、下落するグラフの予測が見当違いになる可能性も十分ある)
(参考1) 複数のグラフを一括で出すためのコードの紹介
今回、グラフ作成にあたり「以下、共通コードを参照」という文言を多く使用した。これは”dfの範囲”と”予測する日付”以外は同じコードを使用しているため、同じコードを丁寧に紹介し続けるとブログの文章量が多くなり、冗長な内容となる事を防ぐためである。
この重複する内容を解消する方法の1つとして、Aidemyのカウンセリングにてご指導をいただいた、複数のグラフを一括で出すコードを紹介する。
#グラフ(1)のコード
#以下、共通コード3とする
#YahooFinanceのインポート準備
!pip install mplfinance japanize-matplotlib
#この下は別のセルに貼り付けをして使用して下さい
#ライブラリのインポート(YahooFinance参照)
import yfinance as yf
from datetime import datetime
df= yf.download("^BSESN").dropna() #SENSEX
import pandas as pd
import itertools
import matplotlib.pyplot as plt
#データの取得期間 -- Export-Importとyfが重複する期間を対象とする(1997/7から当日まで)
st = "1997-07-01"
ed = "2024-05-31"
# 株価の終値データを抽出
close_prices = df['Close'] # 適宜、終値の列名を変更してください
# 年ごとの終値の平均を計算
annual_mean_close = close_prices.resample('M').mean()
# グラフのサイズを設定
plt.figure(figsize=(10, 6))
# 折れ線グラフを描画
plt.plot(annual_mean_close.index, annual_mean_close.values, label='Month Mean Close Price', color='blue')
# グラフのタイトルとラベルを設定
plt.title('Month Mean Stock Close Price')
plt.xlabel('Month')
plt.ylabel('Mean Close Price Yen')
plt.legend()
# グラフを表示
plt.show()
#この下は別のセルに貼り付けをして使用して下さい
df
print(df.index)
print(df.columns)
#この下は別のセルに貼り付けをして使用して下さい
df = df.asfreq("M",method="ffill")
df#上のコードをもとに、(df, start_date, end_date, title)を変更したコードを複数作成すると
複数のグラフが出力する
#以下、共通コード4とする
def plot_mean_close_prices(df, start_date, end_date, title):
# 指定された期間のデータを抽出
df_period = df[start_date:end_date]
# 株価の終値データを抽出
close_prices = df_period['Close'] # 適宜、終値の列名を変更してください
# 月ごとの終値の平均を計算
monthly_mean_close = close_prices.resample('M').mean()
# グラフのサイズを設定
plt.figure(figsize=(10, 6))
# 折れ線グラフを描画
plt.plot(monthly_mean_close.index, monthly_mean_close.values, label='Monthly Mean Close Price', color='blue')
# グラフのタイトルとラベルを設定
plt.title(title)
plt.xlabel('Month')
plt.ylabel('Mean Close Price Yen')
plt.legend()
# グラフを表示
plt.show()
# データフレームの読み込みや初期化が必要です
# df = ...
#以下、目的に合わせてグラフの設定を行う
# 各グラフの出力 (df, "出力する期間", 'Monthly Mean Stock Close Price, "グラフタイトル"')
#Case-1
plot_mean_close_prices(df, "2000-01","2013-12", 'Monthly Mean Stock Close Price Case-1')
#Case-2
plot_mean_close_prices(df, "2014-01","2022-12", 'Monthly Mean Stock Close Price Case-2')
今回、このコードを使用しなかった理由は、このコードでは先に出力したグラフをdfとして認識してSARIMA分析を行う傾向があるためである。(今回ケースではCase-1:"2000-01","2013-12"の期間がSARIMA分析のdfとなる)
このため、今回試みた「分析する期間は同じだが、予測する期間が異なる分析の比較( 例:リーマンショック前とショック後をそれぞれ予測して比較をする)」の場合、行いたい分析に対し上手く機能しなかったため使用を断念した。
(参考2) 学習と予測は関数に入れず、予測値も入れたグラフ作成について
以下のコードはAidemyのカウンセリングでSARIMA分析について相談をした際に教えていただいたものになります。これは、SARIMA分析で行われる過去を学習したデータによる予測は関数として扱わず、学習したデータによる予測を基に作成した予測値をグラフに反映させたものになります。
#重複する内容が多いため、共通コードによる説明をさせていただきます。
#以下、共通コード3の貼り付けをする#以下、共通コード4に変更を加えたものになります。変更があるところのみ、コードを載せます。
# データフレームの読み込みや初期化が必要です
# df = ...
# 各グラフの出力 (df, "出力する期間", 'Monthly Mean Stock Close Price, "グラフタイトル"')
#Case-1 -グラフ(B)-
plot_mean_close_prices(df, "2000-01","2013-12", 'Monthly Mean Stock Close Price 2000-01 - 2013-12')
#Case-2 -グラフ(D)-
plot_mean_close_prices(df, "2014-01","2022-12", 'Monthly Mean Stock Close Price 2014-01 - 2022-12')
#Case-3 -グラフ(E)-
plot_mean_close_prices(df, "2019-01","2024-12", 'Monthly Mean Stock Close Price 2019-01 - 2024-12')##DatetimeIndexの表示
df
print(df.index)
print(df.columns)
#この下は別のセルに貼り付けをして使用して下さい
df = df.asfreq("M",method="ffill")
df#以下、共通コード2を記載して下さい
- SARIMAの前準備+SARIMAモデルの実行コード # predに予測データを代入する
pred = SARIMA_.predict("2023-05-31", "2024-12-31")
preddef plot_mean_close_prices(df, start_date, end_date, title, pred):
# 指定された期間のデータを抽出
df_period = df[start_date:end_date]
# 株価の終値データを抽出
close_prices = df_period['Close'] # 適宜、終値の列名を変更してください
# 月ごとの終値の平均を計算
monthly_mean_close = close_prices.resample('M').mean()
# グラフのサイズを設定
plt.figure(figsize=(10, 6))
# 折れ線グラフを描画
plt.plot(monthly_mean_close.index, monthly_mean_close.values, label='Monthly Mean Close Price', color='blue')
plt.plot(pred, "r")
# グラフのタイトルとラベルを設定
plt.title(title)
plt.xlabel('Month')
plt.ylabel('Mean Close Price Yen')
plt.legend()
# グラフを表示
plt.show()
# 各グラフの出力 (df, "出力する期間", 'Monthly Mean Stock Close Price, "グラフタイトル"')
#Case-1 -グラフ(B)-
plot_mean_close_prices(df, "2022-01","2023-12", 'Monthly Mean Stock Close Price 2023-01 - 2023-12', pred)

今回は、(参考2グラフ) の方が予測精度が出ると考えているので成果物に使用することを考えたが、「実績vs予測」をテーマとした今回の成果物では「学習と予測は関数に入れず、予測値も入れたグラフと実績の差異」をどのように考えたら良いのかについて上手く考えが纏まらなかったため、使用するのを断念した。
5.LSTM分析
この節では、LSTM分析を用いた為替予測の検証を行い、これらの結果をもとに実績と予測の乖離について考察をする。
なお、検証する時期の区分については、SARIMA分析と同じ時期とした。(検証する時期の区分については、4.SARIMA分析を参照のこと)
LSTM分析前の前提: 1997年7月~2024年5月末までのグラフを作成(このグラフを基準として考える、3.データ分析の準備を参照のこと)
1) LSTM分析の紹介
「LSTM分析とは何か」について、Aidemyの講座[時系列解析Ⅱ(RNNとLSTM) -1.2.3 LSTMの構造]を参考として簡潔に説明をする。
LSTMとは”Long-Short Term Memory”の略であり、長期的な記憶を保持することができないシンプルなRNNに対してRNNの中間層(隠れ層)のユニットをLSTMブロックに置き換えることで長期に文脈を保持することができるようになるプログラムです。以下はAidemyの講座で紹介されている図説になるので、LSTMのシステムフローは下図の参照をお願いします。




2) 3つの時期区分の検証
前提: 1997年7月~2024年12月末までのグラフを作成(基準として考える)
※グラフ(3)とする
① 2000~2013年(リーマンショック前の実績に基づく予測vsリーマンショックが起こった後の実績) ※グラフ(F)とする
② 2014~2022年(コロナウイルス蔓延前の実績に基づく予測vsコロナウイルス蔓延が落ち着いた頃の実績) ※グラフ(G)とする
③ 24年5月以降の予測(”2019~2024年5月末までの実績をもとに予測” vs ”1997~2024年5月末までの実績をもとに予測” ) ※グラフ(H)とする
※コードを作成するにあたり、以下のブログを参照させていただいた。
前提: 1997年7月~2024年5月末までの実績+2024年12月末までの予測
上記の期間をもとにグラフを作成(これをLSTM分析を行う基準として考える)
※以下、グラフ(3-1) , グラフ(3-2) とする
・今回は、「学習と予測の繰り返しをする関数」として”def predict(df):”を使用した。これの使用により、①∼③は予測する期間を指定するコードを変更するのみでグラフ作成が可能となった。(#LSTMモデル 共通コードを参照)
・今回の予測は、全て"window_size=30", "epochs=30"で統一して行った。
#LSTMモデル 共通コード
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation,LSTM
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras import optimizers
import numpy as np
from sklearn.metrics import r2_score
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()
from datetime import datetime
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, LSTM, Dropout
import matplotlib.pyplot as plt
#分析期間の設定 … 分析したい期間を、start='yyyy-mm-dd', end="yyyy-mm-dd"で変更する
s_target = "^BSESN"
df = pdr.get_data_yahoo(s_target, start='1997-07-01', end="2024-12-31")
df.head()
#学習と予測の繰り返しをする関数
def predict(df):
#グラフ設定
plt.figure(figsize=(16,6))
plt.title(s_target + ' Close Price History')
plt.plot(df['Close'])
plt.xlabel('Date', fontsize=14)
plt.ylabel('Close Price Yen', fontsize=14)
plt.show()
# Close(終値)のデータ
data = df.filter(['Close'])
dataset = data.values
# データを0〜1の範囲に正規化
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(dataset)
scaled_data
# 全体の80%をトレーニングデータとして扱う
training_data_len = int(np.ceil( len(dataset) * .8 ))
# どれくらいの期間をもとに予測するか
window_size = 30
train_data = scaled_data[0:int(training_data_len), :]
# train_dataをx_trainとy_trainに分ける
x_train, y_train = [], []
for i in range(window_size, len(train_data)):
x_train.append(train_data[i-window_size:i, 0])
y_train.append(train_data[i, 0])
# numpy arrayに変換
x_train, y_train = np.array(x_train), np.array(y_train)
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
model = Sequential()
model.add(LSTM(units=50,return_sequences=True,input_shape=(x_train.shape[1], 1)))
model.add(Dropout(0.2))
model.add(LSTM(units=50,return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50,return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50))
model.add(Dropout(0.2))
model.add(Dense(units=1))
model.compile(optimizer='adam', loss='mean_squared_error')
history = model.fit(x_train, y_train, batch_size=32, epochs=30)
model.summary()
# テストデータを作成
test_data = scaled_data[training_data_len - window_size: , :]
x_test = []
y_test = dataset[training_data_len:, :]
for i in range(window_size, len(test_data)):
x_test.append(test_data[i-window_size:i, 0])
# numpy arrayに変換
x_test = np.array(x_test)
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1 ))
# 予測を実行する
predictions = model.predict(x_test)
predictions = scaler.inverse_transform(predictions)
# 二乗平均平方根誤差(RMSE): 0に近いほど良い
rmse = np.sqrt(np.mean(((predictions - y_test) ** 2)))
print(rmse)
# 決定係数(r2) : 1に近いほど良い
r2s = r2_score(y_test, predictions)
print(r2s)
train = data[:training_data_len]
valid = data[training_data_len:]
valid['Predictions'] = predictions
plt.figure(figsize=(16,6))
plt.title('Model')
plt.xlabel('Date', fontsize=14)
plt.ylabel('Close Price Yen', fontsize=14)
plt.plot(train['Close'])
plt.plot(valid[['Close', 'Predictions']])
plt.legend(['Train', 'Val', 'Predictions'], loc='lower right')
plt.show()#グラフ(3-1),グラフ(3-2)の出力
#1997年7月∼2024年5月末までの実績+2024年12月末までの予測
s_target = "^BSESN"
df = pdr.get_data_yahoo(s_target, start='1997-07-01', end="2024-12-31")
df.head()
predict(df)


① 2000~2013年(リーマンショック前の実績に基づく予測vsリーマンショックが起こった後の実績) ※以下、グラフ(F-1) , (F-2)とする
(F)- 2000~2013年までのグラフの作成、LSTM分析を実行
#グラフ(F-1),グラフ(F-2)
#2000~2013年までのグラフ
s_target = "^BSESN"
df = pdr.get_data_yahoo(s_target, start="2000-01-01", end="2013-12-31")
df.head()
predict(df)


② 2014~2022年(コロナウイルス蔓延前の実績に基づく予測vsコロナウイルス蔓延が落ち着いた頃の実績)※以下、グラフ(G-1) , (G-2)とする
(G)- 2014~2022年までのグラフの作成、LSTM分析を実行
#グラフ(G-1),グラフ(G-2)
#2014~2022年までのグラフ
s_target = "^BSESN"
df = pdr.get_data_yahoo(s_target, start="2014-01-01", end="2022-12-31")
df.head()
predict(df)


③ 24年5月以降の予測(”2019~2024年5月末までの実績をもとに予測”vs ”1997~2024年5月末までの実績をもとに予測” ) ※以下、グラフ(H-1) , (H-2)とする
(H)- 2019年~2024年12月末までのグラフの作成、LSTM分析を実行
#グラフ(H-1),グラフ(H-2)
#2019年~2024年5月末までのグラフ
s_target = "^BSESN"
df = pdr.get_data_yahoo(s_target, start="2019-01-01", end="2024-12-31")
df.head()
predict(df)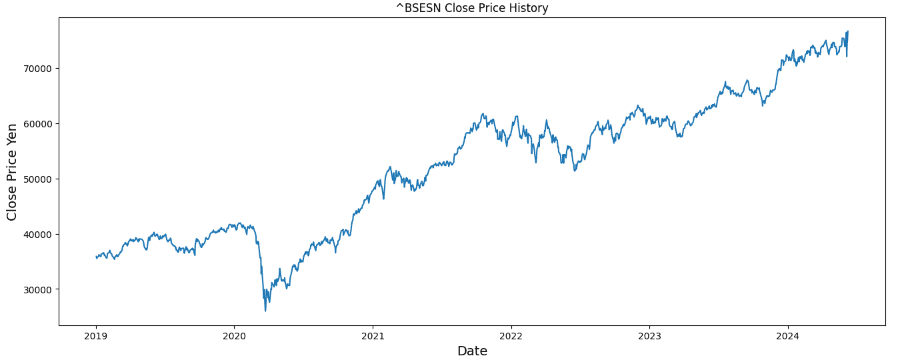


3) 検証結果に対する考察
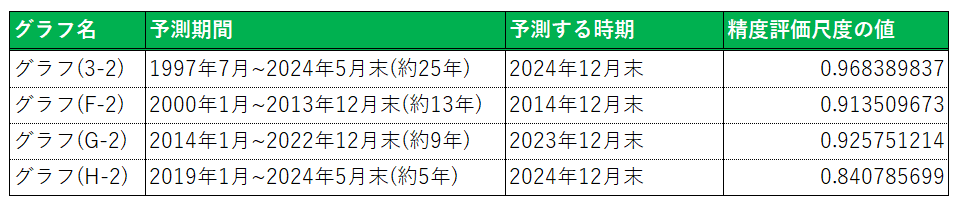
ここでは、上記の グラフ(3-1,3-2) と (F)~(H) の予測結果をもとに、課題となる点について言及を行う。
(考察1) 精度評価尺度の差と予測を行った期間の違いが出たのは、なぜか
今回はリーマンショックやコロナショックなどの社会現象に合わせた予測期間の設定を行ったため、それぞれの予測期間が異なる形になった。このため、予測期間の違いが精度評価尺度への影響が出ている可能性が考慮される( グラフ(3) と グラフ(F)~(H) では、精度評価尺度が 0.1~5前後の違いが生じている)。
また、予測期間の設定が適切であったかについて、今後の検証が必要である。



(考察2) "window_size", "epochs"の設定問題
今回の予測は"window_size=30"、"epochs=30"で統一して行った。これらの設定にした理由は、①"window_size=30"が全てのグラフ作成に対してある程度の精度がでる条件であったこと、②"epochs=30"は計算量の膨大にしないためである。
精度評価尺度だけで見れば、この条件は精度が出ていると考えられるが、予測を行うのに最適な精度であったかとは判断がつかないため、今後の課題である。
また、コード実行ごとに精度評価尺度が違う場合があり、今回は一番精度が高い数字を記載した。この問題の解決も今後の課題である。
4) この節のまとめ
今回は1997年7月~2024年5月末の期間を対象に、リーマンショックやコロナショックなどの社会現象に合わせて、検証期間を区切り為替予測を行った。それを踏まえ、以下の点が検証結果だと考えている。
(まとめ1) LSTM分析を行う際の設定が適切であるか熟慮しなければならない
今回のケースでは、予測を行う期間のみ条件を変えて予測を行ったが、社会現象に合わせて予測期間を変える=予測のもとになる時間に差が生じる事に繋がった。つまり予測計算をするための元データの量に差が生じているという事であるため、精度評価尺度に差が出るのは自明である。
しかし、予測期間が異なるもの同士を比較することについて、「正確な比較が出来ているか」の疑問もあるため、予測期間の設定については再考が必要である。
また、"window_size", "epochs"、共に4つのグラフ作成をする際に共通してある程度の精度が出る数字をいくつか検証した上で値を決めたため、今後は精度が出る値を探して検証結果を導くのでなく、求める結果から逆算をして予測の設定をすることが課題である。
(まとめ2) Val(正確値)とPrediction(予測値)の差についての説明が必要
今回の検証では、4つのグラフのVal(正確値)とPrediction(予測値)を比較すると、「正確値が予測値を上回るが2つに大きな差はほぼない」という結果であった。
このため、精度が出ている予測が出来たという判断を下すことが出来る一方で、「2つに大きな差はほぼない」理由について十分な説明が出来ていない。このため、「差がない」理由について説明が出来るようにすることが今後の課題である。
6.SARIMA分析とLSTM分析の精度比較
この節では、SARIMA分析とLSTM分析の精度比較を行い、分析手法の違いによって予測結果がどのような違いがあるかを明確にする。
1) 2000~2013年末までのグラフの比較 - グラフ(A)(B) vs グラフ(F-2)
ここでは、SARIMA分析による グラフ(A)(B) とLSTM分析による グラフ(F-2)の精度比較を行う。グラフは全て2014年末までを予測している。

2) 2014~2022年末までのグラフの比較 - グラフ(C)(D) vs グラフ(G-2)
ここでは、SARIMA分析によるグラフ(C)(D) とLSTM分析による グラフ(G-2)の精度比較を行う。グラフは全て2023年末までを予測している。
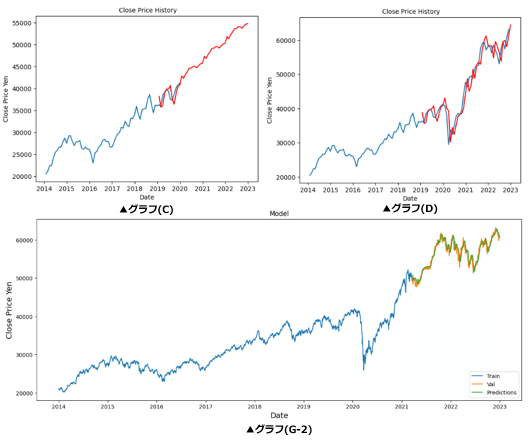
3) 2019~2024年5月末までのグラフの比較 - グラフ(E)(グラフ2)vs グラフ(H-2)
ここでは、SARIMA分析による グラフ(E),(1-2) とLSTM分析による グラフ(H-2)の精度比較を行う。グラフは全て2024年末までを予測している。

4) この節のまとめ
上記の精度比較の結果を踏まえ、明らかになった事を以下に整理を行う。
・SARIMA分析では、学習内容により大きく結果が異なることが判明した。(リーマンショックやコロナショックを学習した内容の方が、LSTM分析の予測に近い結果を出しており、分析精度は高いと言えるのではないか)
・学習する背景を同じにしたSARIMA分析とLSTM分析の場合、予測結果が近しい場合がある( 比較グラフ(1) と 比較グラフ(2) を参照)。
ただし、学習する背景を同じにしたSARIMA分析とLSTM分析であっても、予測結果が異なる場合がある( 比較グラフ(3) を参照)。
・比較グラフ(3) の予測結果が異なる理由を考察することは、次回の課題。各グラフのコードを確認いただくと分かるが、SARIMA分析/LSTM分析共にほぼ同じコード(予測する日付などのみ変更)であるため、 比較グラフ(3) のみ予測結果の大きな乖離が生じた事は、原因究明の必要がある。
・予測精度だけで考えるのならば「LSTM分析>SARIMA分析」となるが、大まかな予測傾向を掴むのならば「LSTM分析<SARIMA分析」と考える事も出来るのではないだろうか。
上記の考えの根拠は、下記のグラフをもとに為替推移について考えた場合、 グラフ(A) が仮にバブル状態であるとしても、どこかで暴落することが予想できる(=リーマンショックと同じ状態に何かしらの原因で陥る可能性がある)ためである。
また、 グラフ(1) では2022年前後でグラフ(A)の予想価格に到達している。この事実だけを考えるならば、グラフ(A) は短期的な成長に対して疑問が生じるが長期的な為替推移の予測の方向性は大まかな特徴を捉えていると言えるのではないか。
7.結論、今後の課題
1) 結論
結論として、今回の検証では以下の事が言及できると考えている。
(1) SARIMA分析は過去実績に基づく分析のため、リーマンショックなどの予測ができない急激な下落の有無により、大きく結果が変わる。
(2) SARIMA分析の特徴を考慮すると、予測ができない急激な下落がないケースの予測は”バブル”を表している可能性がある(実体経済との乖離)。
(3) LSTM分析は、予測を行う前の課題/目的/コード作成をする際の設定を詳細に整理し、且つ適切であるかを熟慮する必要がある。
(4) 上記の整理が不十分な場合、Val(正確値)とPrediction(予測値)の差の説明、もしくは実績と予測の乖離の説明が出来ない場合がある。そのため、LSTM分析はSARIMA分析より予測精度が高くなりやすい特徴があるが、予測結果をどのように整理/理解するかが難解である。
(5) SARIMA分析とLSTM分析を比較した結果、過去実績ありきで考えるのならば予測精度はLSTM分析の方が過去の実績に沿った精度の高い分析ができると考えている。
・ただし、精度の高さは"epochs"等の値の決定を始めとした予測前の課題設定により左右されるため、設定の作りこみが精度の高い分析の焦点となる。
・一方で、(何が起こるか分からない)5~10年先の将来の予測をするにあたっては、精度だけを見ると信頼性に欠けるように思えるが、ある程度の目標値や目安を知る方法として予測を行うにはSARIMA分析の方が機能するのではないかと考えている。
2) 今後の課題
今回の成果物作成を通じて、今後の課題は大きく以下の2点だと感じた。
(1) 大きなテーマを安直に選ばず、検証内容を絞り”成果物”を作成すること
・今回はインド為替変動約25年をターゲットとして分析を行ったが、ターゲットとした期間が長すぎたため、冗長なレポートになった。(上手く整理が出来ていないサーベイ論文のようになってしまった)
・今回の反省を活かすのならば、次回以降は「リーマンショック前と後」 や「コロナウイルスの前と後」のように時期を短く絞るべきである。
(2) 時期を絞った上で、様々な分析手法を用いて多面的に分析を行うこと
・今回は2つの分析手法で為替分析を行ったが、分析手法が似ている事もあり、主張が弱い(発見が多くない)ポートフォリオになった。Aidemyで学んだ事も活かしきれていない点が多くあったため、知識の実用的な使い方を身につけることが必要だと痛感している。
(3) 経済危機の経験回数など数値変化の背景の影響を考慮すべきではないか
・今回の分析期間にはリーマンショックとコロナショック、2つの大きな「経済危機」と呼べるものが約10年ごとにあった。単純に時系列で考えるならば、2029年前後には「経済危機」と呼べるものが起こるのではと 考えることも出来る。
・このため、単に数値変化を追うのではなく、「世の中の変化」や「変化のきっかけ」に対しての理解や分析がなければ、正確な(精緻な)分析/物事の把握は困難であると改めて感じた。
(4) note(≒縦に読む/書く形のレポート)のまとめる経験値が少ない
・最後になるが、このブログの公開にあたり内容を何度も読み返したが、縦に読む形のレポート作成のスキルが不十分と分かる内容だと感じた。
・成果物などの評価として「読んでくれた方の新しい知見に繋がる」「読んで面白かった」などの感想を持っていただける事が、良い成果物の評価基準だと考えているため、縦に読む/書く形のレポート作成のスキルを磨きたい
結び
今回の成果物に対する自己評価としては、”やりたかった結果とは違う結果となった”と痛感した。これの原因としては、以下の2点が主なものだと考えている。
① Pythonを扱った経験が少ないことによる実力不足(問題に対するアプローチ方法の知識や経験の不足や、GoogleColaboの効率的な使い方が出来ていなかった等のツールの使用方法の問題)
② ブログなどをはじめとした先行者の成果から「新しい知識」を学ぶ姿勢が足りなかった(ブログやKaggleなどの参照による自学習、この点についてはチューターさんにブログを参考にする方法などの自学習法を教わったため実践していきたい)
これらは、今後仕事をしていく上で解決や習慣化が必須となるスキルであるので、Aidemy修了前に気づくことが出来たのは幸いだった。
上記のように反省点が多い自己評価ではあるが、実際の活動は成果物を作ることは非常に楽しかった。カウンセリングで自分の未熟さの指摘を受けながらも自分の知識が増えることが実感できたことは毎回の楽しみであった。
(特にカウンセリングやSlackによる、多くのチューターさんの意見を参考に出来た事は大きくやる気の向上に繋がった。このため「CDLE」の会員となり交流や意見交換をする事ができるようになる「E資格の合格」は自分の好奇心や知識欲にとって非常に魅力的であり、尚且つ今後の仕事に対してのモチベーションを維持・向上が図れる環境であるため、是非とも合格をしたいと強く感じた。)
また、この成果物作成を通じて気づけた事として「自発的な活動、特に自分自身が興味を持てる/積極的に物事に取り組める状態を作り出す事が、仕事をはじめとした物事の取り組みには必要なのだ」という考えを持てるようになった。
この考えを持てた要因は、「取り組み方や成果物の評価というのは自分ひとりで行うものではない」という事に、チューターさんやSlackで交流した方々などを通じて気づいたからだった。
Kaggleが良い例であるが、現代社会ではインターネットを通じて様々な情報や膨大なデータを個人が分析をして、”成果物”や”レポート”などを作ることが出来る。
だが、それらが設定したテーマに対して十分な情報やデータを活用・網羅した上で紹介・製作がされているかと言えば、十分とは言い難い部分が少なからずあると感じている。
しかし、不十分なデータ活用の中でも世界中の多くの人がKaggleを通じて情報発信をしている事実を目の当たりにし、その事実に感銘を受けると同時に「誰かが何とかしてくれる」という考えに甘えている自分がいることに恥ずかしさを覚えた。
上記の経験を通じて、データ情報などの有無は二次的な条件でしかなく、「自分がどれだけ主体的に動けるか」が未経験からIT分野に挑戦する私が直面しつづける問題だと気づけた。この問題には終わりがなく、文字通り働けなくなる状態(年齢)まで、取り組み続ける課題だと感じている。
また、今回のデータ分析や過去の研究論文を通じてはっきりしたことは、自分が「疑問を持ったことに対して、明確な解答・結論が出るまでは物事を投げ出さない性格」であり、「難解な問題や困難な課題であっても解決方法の思考や行動に対して『楽しさ』を覚える傾向がある」ことを客観的に自覚できたことである。これらが、Aidemyの受講を通じて得た一番の成果だと考えている。
最後になりますが、このような点から「Aidemy受講は『新しいキャリア形成』のよいスタートをすることが出来る環境である」と自信を持ってお読みになっている方にお伝えが出来ます。長くなりましたが、これで本成果物の結びとさせていただきます。