議事録を自動生成したい!

議事録って新人やアシスタントが任されたりして、不毛な作業のひとつですよね。リモート会議全盛の時代になって、なんでもかんでも会議になるのですが、まぁ議事録作っておいてとか簡単に言われる訳です(私は言う方ですが。。)
で、新人君には訳のわからん内容の会議を聞いて四苦八苦して議事録つくる訳です。何を省いて、何を残すが腕の見せ所なんですがそもそも議論されている内容に興味なければやる気も起きない。リアルタイムで退屈な会議に参加して頑張って作るならまだしも、2時間くらいある会議の録音を後から聞いて文字起こししてから議事録まとめるなんてもう最悪な訳です。
1時間の会議を5時間かけて議事録にしたりとか。もう何やってるか分かんないですよね。そりゃ日本人の生産性低いって海外から言われる訳ですよ。
そんな訳で自動化な訳です。めんどくさい事は機械に任せようです。ずっとアシスタントさんから「やりたくないっす」とか言われ続けていて、でも仕事だからなーとお願いしてたんですが、何かいいソリューションはないかと。市販の文字起こしソフトも試したりしたのですが、技術専門用語多い会議だともう何がなんだかです。
で、ずーっと考えて続けていてつい最近このニュースを見たんですね。
おお、もうこれは試してみるしかないと。一応オープンソースだし、最近流行りのAI, DeepLearning使ってるし、いっちょやってみるかと。
Install
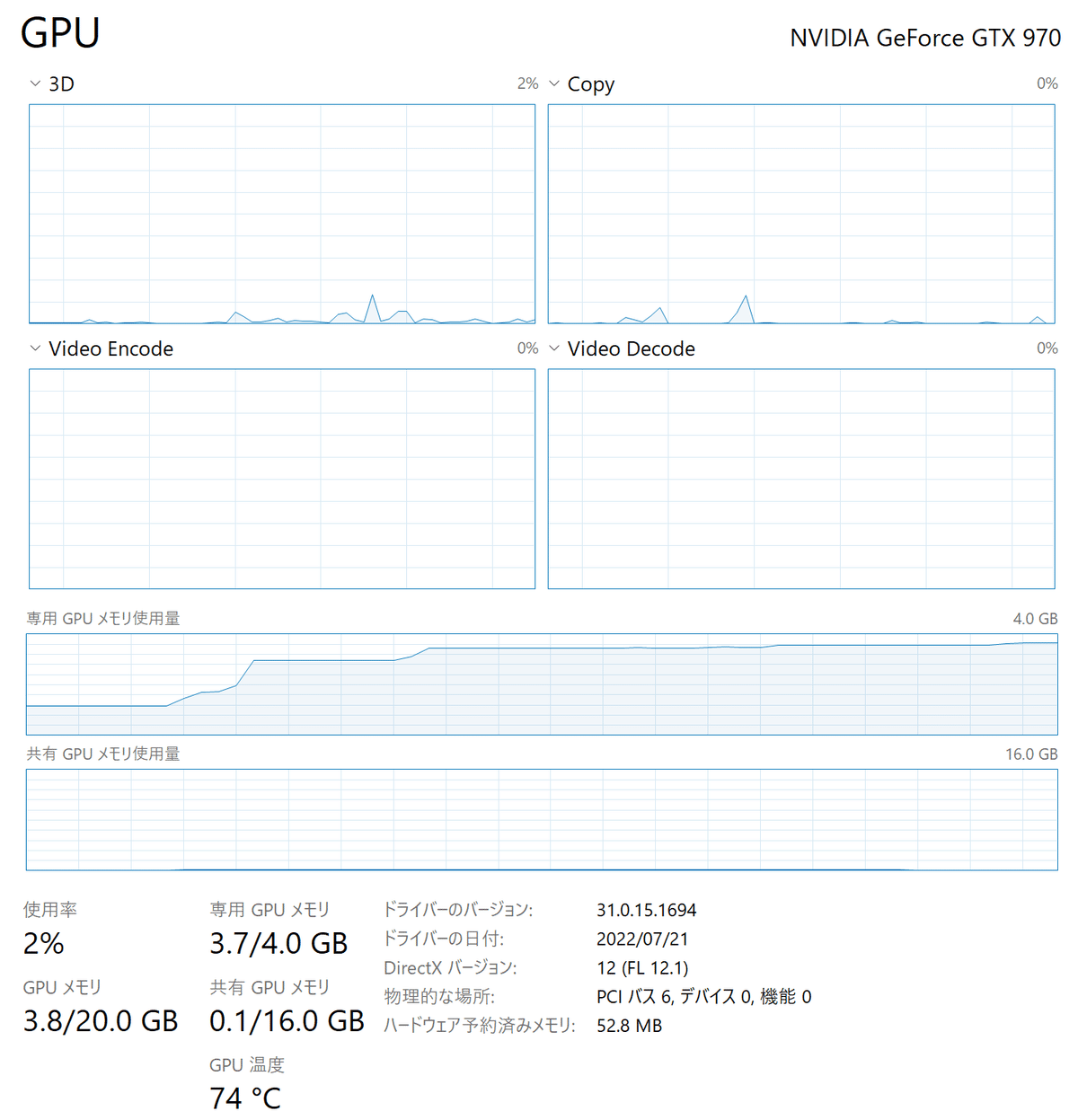
家のお古の一応GPU付きのWindows PCで試してみました。Anaconda上で動かしてます。Install方法とかは他の記事の方が詳しいので結果だけ書いておきますが、CUDAというNVIDIA GPU用のライブラリInstallだけちょっと手間取りました。先に入れておかないと後で入れるTorchからCUDAを使えないみたいでGPU上で動かせないです。
良い点
単一言語だとかなり精度が良い。ほぼ違和感のない日本語(または英語)テキストを吐いてくれる
日英混合の会議録音(一応外資企業なんで日英混合な会議が多いんですよ。。)を読み込ませると日本語モデルを指定すると日本語の部分だけを、英語モデルを指定すると英語の部分だけを文字起こししてくれます。
別途比較の為に試したMicrosoft Office365のMicrosoft Streamでの自動Transcript機能よりも精度が高い場合があります
GPU使うとそれなりに早い(Smallモデルを使うと1時間の会議録音を30分くらいで処理が終わる)
Deep Learningを家のPCで実行している優越感に浸れる。え?
いまいちな点
日英混合の録音だとうまくいかない(上記でそれぞれの言語で文字起こししてくれると書きましたが、うまくいけばで、ダメな場合は途中であきらめちゃったりします)
Microsoft Streamではこのあきらめる事はなかったです
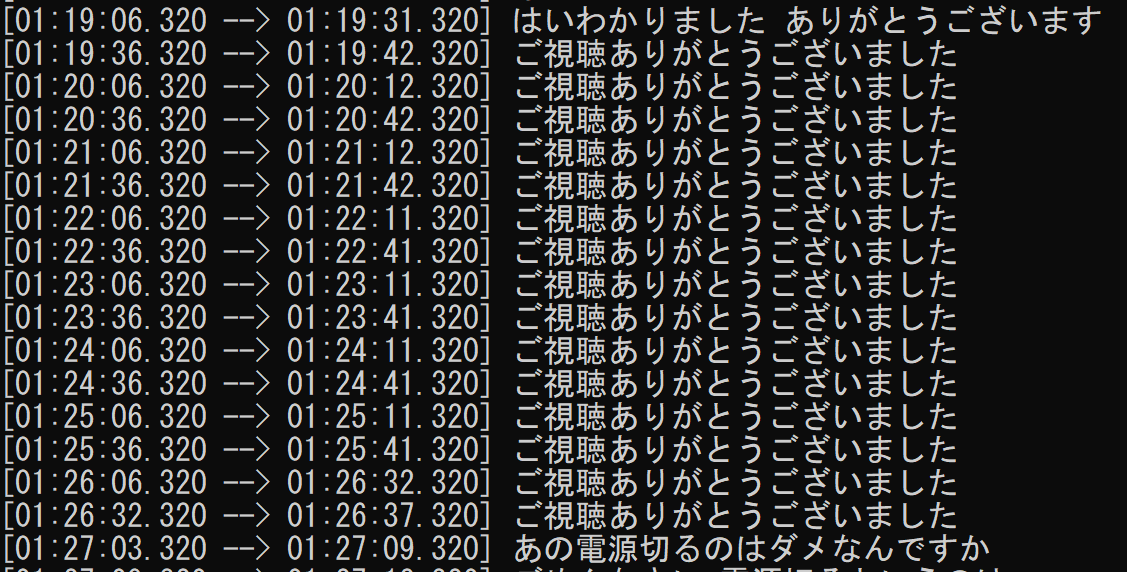
無音時間が長いとうまくいかない。なんだかわかりませんが、変な文章が連発したりします。例えば以下。学習データがYoutubeとかの文字起こしを使ってるんでしょうね。。他にもチャンネル登録お願いしますとか出たり。いや会議でチャンネル登録お願いしませんからね。。
これもMicrosoft Streamでは起きませんでした
一番精度の良いLargeモデルだとGPUのVRAMが12GBくらい必要なので、そもそも動かせる環境が限られている。うちのPCには4GBしか載ってない良いGPU買ってもいいけど、ちょとお高い。。
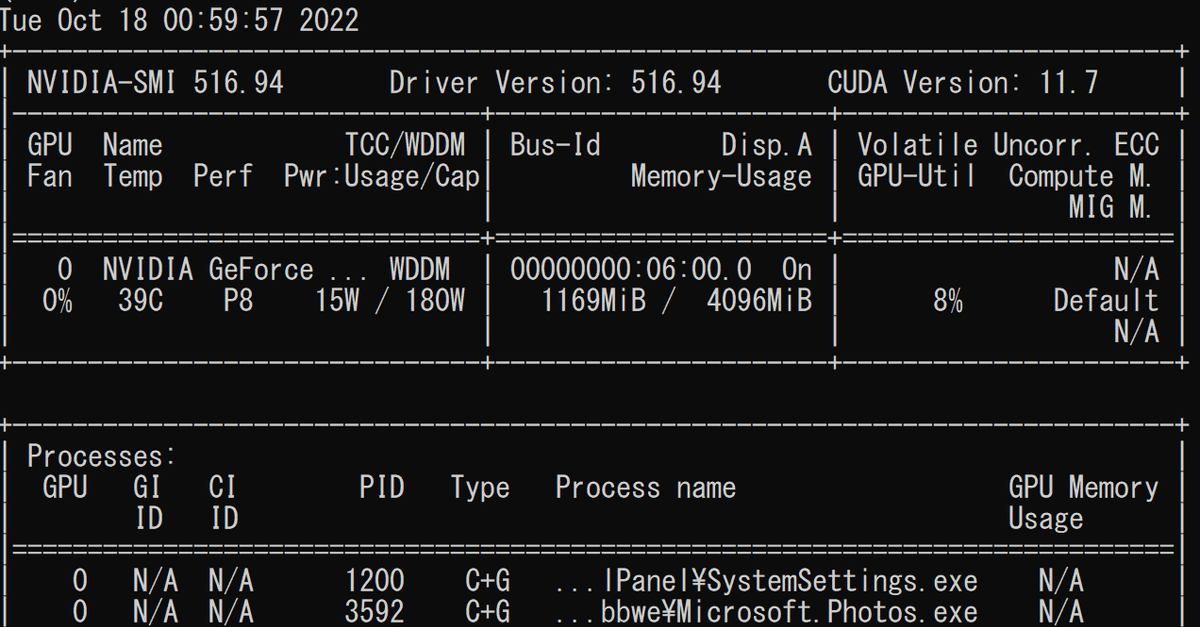
以下の様なエラーで怒られます。。(Microsoft StreamだとクラウドでやってくれるのでGPUの心配なし!)
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 4.00 GiB total capacity; 3.29 GiB already allocated; 0 bytes free; 3.54 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONFで、無理にCPUで動かそうとするとめちゃくちゃ遅い(自分のPCだと1分の文字起こしに1時間くらいかかった。。)
ぱっと思いつく改善点としては。。
話者分離はリモート会議ソフト側でしてくれれば、英語話者部分、日本語話者部分別々のチャンネルにしてくれれば解決できそうな気がする。
または逐一30秒ごとに言語判定するとか。(処理速度が遅くなるだろうけど。。)
言語モデルのUpdateが出来たら技術専門用語、社内専門用語、人物名とか名詞に強くなると思うのでより精度があがると思いますね。話者区別もできるだろうし
Microsoft StreamはTranscriptを編集するとそれを元に学習するって記載があるんですが、本当かな?
という訳でなんだか偉そうに文句ばっかり書いちゃいましたが、オープンソースでここまで精度が良いのは凄いし、まだまだ発展途上な気がするので今後より良いVersionやWhisperをエンジンにしたアプリが出てくるのではないでしょうか。
自分で貢献出来たらいいんですけどね。。。そこは、まだまだ修行が足りない様で。。
結論
後は文字起こししても、そのまま議事録にはならないのでそこから先の要約部分はやっぱり人間の頭脳が必要な点です。文章要約AI使えばそれなりにまとまるのだろうか。いやなかなか難しいでしょう。。完全自動化には程遠いですね。
人間ってまだまだすごい!
おまけ
Whisper実行中のGPU状態。メモリ上に展開してGPU温度がどんどん高くなってめっちゃ頑張って行列計算してるんだなって感じる。。