
Diffusionモデルの生成画像の多様性とリアリティを同時に高めるCLIPとは?

概要
この論文は、テキストから画像を生成する技術において、画像の多様性と品質の両方を高める新しいアプローチを提供します。これは、画像生成AIの進化において重要なステップです。特に、CLIPに基づくモデルを使用することで、よりリアルで多様な画像を生成できるようになり、この分野のさらなる発展に寄与する可能性があります。

文献情報
タイトル
著者
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen
出版日
2022年4月13日
背景
この論文は、テキスト条件付きの画像生成に関する最新の研究を紹介しています。最近のコンピュータビジョンの進歩は、大規模なキャプション付き画像データセットを使用してモデルをスケーリングすることによって推進されています。CLIPというモデルは、画像の堅牢な表現を学ぶことに成功しています。CLIPの埋め込みは、画像配布のシフトに対する堅牢性や印象的なゼロショット能力など、望ましい特性を持っています。一方で、拡散モデルは画像や動画生成タスクにおいて最先端の結果をもたらしています。しかし、拡散モデルはサンプルの多様性を犠牲にして画像の忠実度を向上させる傾向があります。
課題
テキスト条件付きの画像生成において、高い忠実度と多様性のバランスをとることが挑戦でした。CLIP埋め込みを活用することで、画像の多様性を向上させつつ、写実性やキャプションの類似性を損なうことなく画像を生成する方法が求められています。また、CLIPの共同埋め込み空間を利用して、言語による画像の操作をゼロショットで実現する方法も探求されています。
論文のメインアイデア
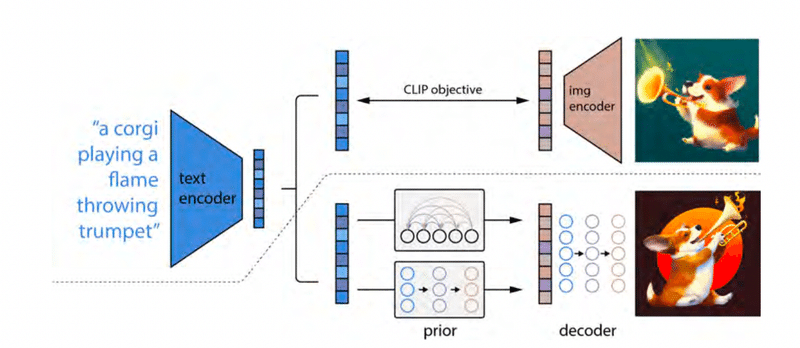
この論文では、画像生成AIにおける新しいアプローチを提案しています。主なアイデアは、テキストから画像を生成するために、CLIP(Contrastive Language–Image Pretraining)に基づく二段階モデルを使用することです。具体的には、以下の二つのステップで構成されています。
プライオリ(事前)モデル:このモデルは、テキストキャプションからCLIP画像埋め込み(イメージの表現)を生成します。
デコーダー(解読器)モデル:このモデルは、先のプライオリモデルで生成された画像埋め込みに基づいて、実際の画像を生成します。
このアプローチの特徴は、CLIPの持つ強力なテキストと画像の関連性を利用して、より多様でフォトリアリスティックな画像を生成することができる点にあります。また、CLIP埋め込みを利用することで、言語に基づく画像の操作(例えば、テキストの変更による画像の変化)も可能になります。
実験された内容のまとめ
この論文では、テキストから画像を生成するためのunCLIPシステムが紹介されています。このシステムは、テキストキャプションからCLIP画像エンベディングを生成するための「prior」と、CLIP画像エンベディングに基づいて画像を生成する「decoder」の2つの主要なコンポーネントから構成されています。
unCLIPシステムの重要な特徴は、異なる条件設定での画像生成能力です。たとえば、テキストキャプションのみをデコーダに入力する場合、またはテキストキャプションとCLIPテキストエンベディングを組み合わせて入力する場合などが挙げられます。これらの異なる設定で生成された画像は、品質やキャプションの類似性において比較が行われています。
さらに、unCLIPシステムは、人間による評価を通して、写実性、キャプションの類似性、サンプルの多様性においてGLIDEシステムと比較されています。これらの評価では、様々なガイダンススケールを使用して、unCLIPとGLIDEが生成した画像の品質を比較しています。unCLIPは、ガイダンススケールを上げても、内容のセマンティックな多様性を維持することが観察されています。
実験結果のまとめ
unCLIPシステムの実験結果は以下の通りです:
キャプションのみの条件:テキストキャプションのみを用いた場合、結果は最も低い品質を示しました。
テキストエンベディングの利用:テキストキャプションとCLIPテキストエンベディングを組み合わせた場合、より良い結果が得られました。
CLIP画像エンベディングの利用:CLIP画像エンベディングを利用した場合、最も良い結果が得られました。これは、FIDスコア(画像品質の指標)や人間による評価においても確認されています。
unCLIP vs GLIDE:人間による評価では、unCLIPはGLIDEに比べて、写実性とキャプションの類似性において優れていることが示されています。また、ガイダンススケールを上げてもセマンティックな多様性が維持されることも明らかになっています。
今後の展望
技術的発展の可能性: この研究は、テキスト条件付き画像生成の分野における新しい可能性を提示しています。将来的には、さらに高度な技術やアプローチが開発され、より現実的で詳細な画像生成が可能になることが期待されます。
応用分野の拡大: CLIPに基づくこの技術は、広告、エンターテインメント、教育など、多岐にわたる分野での応用が考えられます。特に、ユーザーの入力に基づいてカスタマイズされたコンテンツの生成に利用できる可能性があります。
注意点
倫理的・社会的リスク: AIによる画像生成は、偽情報の拡散や著作権侵害など、様々な倫理的および社会的な問題を引き起こす可能性があります。これらのリスクに対処するために、適切なガイドラインや規制が必要です。
バイアスと品質の問題: トレーニングデータに含まれるバイアスが生成された画像に反映される可能性があります。また、生成された画像の品質や現実性についても、常に注意深く評価する必要があります。
まとめ
この論文は、CLIPを活用したテキスト条件付き画像生成モデルの開発を通じて、画像生成の分野において重要な進歩を示しています。提案されたモデルは、画像の多様性とリアリズムを同時に高めることに成功しており、これからの応用範囲の拡大が期待されます。しかしながら、技術的進歩に伴う倫理的・社会的なリスクに対しても注意が必要です。今後、この分野の発展には、技術的な進化だけでなく、倫理的な課題への取り組みも重要になってくるでしょう。
この記事が気に入ったらサポートをしてみませんか?