
NoSQLについて学ぶ会

NoSQLとは何か
データは現代のビジネスにおける最も重要な資源の1つと言えるでしょう。データの蓄積、分析、利用は、事業戦略を立案し、競争優位性を保持する上で不可欠です。データベースはそのデータを管理する上で重要なツールですが、データベースのタイプや特性は多種多様です。
長い間、リレーショナルデータベースがデータ管理の主役でした。リレーショナルデータベースは、整理された行と列を持つテーブルにデータを格納し、複数のテーブル間のリレーションシップを定義することができます。その一方で、リレーショナルデータベースはスキーマが固定化されており、データの構造が変化するとその対応が困難であるという欠点も持っています。
ここで登場するのがNoSQLデータベースです。NoSQLとは、"Not Only SQL"を意味し、リレーショナルデータベースの制約にとらわれない新たなデータベースの形式を指します。NoSQLデータベースは、スキーマレスまたは半スキーマレスであることが特徴で、データの構造が頻繁に変化する場合や大量のデータを高速に処理する必要がある場合に適しています。
しかし、NoSQLはリレーショナルデータベースの代わりというよりは、特定のユースケースに対してより適したツールと言えるでしょう。NoSQLデータベースの中にもキーバリューストア、ドキュメントストア、ワイドカラムストア(カラムファミリーストア)、グラフデータベースなど、さまざまな種類が存在し、それぞれが異なる特性とユースケースを持っています。
本ブログでは、これらのNoSQLデータベースの主なタイプと特性について深く掘り下げ、それぞれがいつ最適で、またリレーショナルデータベースとどのように比較されるかを解説します。データを扱う全てのエンジニアにとって、リレーショナルデータベースだけでなくNoSQLデータベースの特性と利用シーンを理解することは、現代のデータ駆動型ビジネスを理解する上で不可欠です。
キーバリューストアとは
NoSQLデータベースの中でも最もシンプルな形式を持つのがキーバリューストアです。キーバリューストアは、その名の通り、一意のキーとそれに関連する値をペアとしてデータを保存します。このキーと値のペアは、データベース内で高速に取得・更新することが可能で、データのボリュームが大きくなっても性能を維持することができます。
具体的な例として、以下のようなキーバリューペアを考えられます。
"article:123": {
"title": "記事のタイトル",
"author": "筆者",
"body": "本文",
"tags": ["タグ1", "タグ2", "タグ3"],
"comments": ["comment:456", "comment:789"],
"related_articles": ["article:124", "article:125"]
}上記の場合、`article123`というのが記事を特定する一意のIDであり、それに記事の内容を表す値が紐づけられています。
キーバリューストアはスキーマレスであるため、値の形式は自由です。これは、値が単純な数字であろうと、複雑なJSONオブジェクトであろうと、データベースはそれを一切気にしません。また、新たなキーバリューペアを追加したり、既存のペアを更新したりするための操作もシンプルで、これも性能を高める要因となります。
このような特性から、キーバリューストアは一部の具体的なユースケースにおいて威力を発揮します。その一つが、大量のデータを迅速に書き込み、後からそれを高速に取得する必要がある場合です。例えば、ユーザーセッション情報の保存や、大規模なキャッシュレイヤとしての利用などが考えられます。また、単純なログデータの記録や、時間と共に変化する計測データのトラッキングなど、単純で迅速な書き込みが求められる場合にも適しています。
一方、キーバリューストアは、値の内部構造を解釈したり、操作する能力を欠いています。そのため、値内の特定のフィールドを基にデータを取得したり、複数のキーバリュー項目間のリレーションシップを表現したりすることは困難です。この特徴により、リレーショナルデータベースや他のNoSQLデータベースと比較した場合、使用できるクエリタイプが限定される可能性があります。
ドキュメントストア
ドキュメントストアは、JSONやXMLなどのセルフ記述型のデータフォーマットを用いて、構造化データを保存するデータベース型です。キーバリューストアと同様に、データはキーによってアクセスされますが、ドキュメントストアは値の内部構造を解釈し、その内容に基づいてクエリを発行する能力があるのがキーバリューストアとの大きな違いになります。
それぞれのドキュメントは、フィールドとそれに対応する値の組み合わせを持ち、フィールドはさまざまなデータ型を取りうることが可能です。また、ドキュメントはリレーショナルデータベースのテーブルに類似しており、個々のドキュメントはテーブルのレコードに相当し、フィールドはテーブルの列に相当します。ただし、ドキュメントストアでは各ドキュメントが独自のスキーマを持つことができ、フィールドの存在、数、型がドキュメントごとに異なることが許容されます。
これは、ドキュメントストアが半スキーマレス(またはスキーマフリー)であることを示しています。つまり、ドキュメントのスキーマを定義する必要はありませんが、それでもデータ構造を維持することが可能です。
例えば、次のようなJSONドキュメントを考えられます。
{
"_id": "123",
"title": "記事のタイトル",
"author": "筆者",
"body": "本文",
"tags": ["タグ1", "タグ2", "タグ3"],
"comments": [
{"_id": "456", "comment": "コメント1", "author": "コメント者1"},
{"_id": "789", "comment": "コメント2", "author": "コメント者2"}
],
"related_articles": ["124", "125"]
}
上記のドキュメントは、あるブログ記事の詳細を表しています。それぞれの記事はタイトル、筆者、本文、タグ、コメント、関連記事のフィールドを持つことができます。特に注目すべきは、commentsフィールドは配列であり、複数のコメント(それぞれが_id、コメント、筆者のフィールドを持つ)を持つことができる点です。
ドキュメントストアの主な利点の一つは、データが自己記述的であることです。つまり、フィールド名と値がドキュメントに含まれているため、データ構造を理解するのが容易であり、フィールドの追加、削除、変更が容易です。また、ネストされたデータ構造(配列やサブドキュメントなど)を自然に表現できるため、関連するデータを一緒に保存し、単一の操作で取得することが可能です。
一方、ドキュメントストアは、リレーショナルデータベースのような強力なトランザクション処理を持たず、一貫性と分離性の要件を満たすための柔軟性が制限される可能性があります。また、ドキュメント間でのデータの冗長性を管理するのは開発者の責任であり、これが無視されると、データの一貫性が損なわれる可能性があります。
ワイドカラムストア(カラムファミリストア)とは
ワイドカラムストア(またはカラムファミリストア)は、列指向のデータストレージ方式を採用したNoSQLデータベースです。名前が示唆するように、これらのデータベースは列ベースでデータを保存および取得します。
ワイドカラムストアの概念は少し複雑であり、しばしば理解するのが難しいとされます。しかし、基本的には、ワイドカラムストアは列ファミリというコンテナにデータを保存します。各列ファミリは行と列からなるテーブルのように考えることができますが、リレーショナルデータベースのテーブルとは異なり、ワイドカラムストアの列ファミリはフレキシブルなスキーマを持ちます。これにより、各行は任意の数と種類の列を持つことが可能となります。
それでは、具体的なワイドカラムストアの例を以下に示します。
Row Key: 'Transaction123'
Column Family: 'Details'
Column: 'Transaction_Type', Value: 'Deposit'
Column: 'Amount', Value: '2000.00'
Column: 'Timestamp', Value: '2023-01-01T09:30:00Z'
Column Family: 'User_Details'
Column: 'User_ID', Value: 'User456'
Column: 'User_Name', Value: 'John Doe'
Column: 'Account_Number', Value: 'Account789'この例では、各取引(デポジット、ウィズドローなど)に対応する行が存在し、それぞれが一意のトランザクションID(ここでは 'Transaction123')を持つ行キーで識別されます。'Details'という名前の列ファミリーは取引の詳細(取引タイプ、額、タイムスタンプなど)を保持し、'User_Details'という名前の列ファミリーはユーザーに関連する詳細(ユーザーID、ユーザー名、アカウント番号など)を保持します。このように、ワイドカラムストアは複数の関連する属性をまとめて列ファミリーとして扱うことができ、必要な情報だけを効率的に取得することができます。
Row Key: 'Transaction124'
Column Family: 'Details'
Column: 'Transaction_Type', Value: 'Withdrawal'
Column: 'Amount', Value: '500.00'
Column: 'Timestamp', Value: '2023-01-01T10:00:00Z'
Column: 'ATM_Location', Value: 'Tokyo, Japan'
Column Family: 'User_Details'
Column: 'User_ID', Value: 'User789'
Column: 'User_Name', Value: 'Jane Doe'
Column: 'Account_Number', Value: 'Account321'一方、この例では新たな取引('Transaction124')が引き出し(Withdrawal)であるため、取引の詳細(Details)列ファミリーに'ATM_Location'という新たな列が追加されています。この列はこの特定の取引(引き出し)でのみ必要であり、他のすべての取引(例えばデポジット)では必要とされない情報です。
同様に、特定の取引に関連する他の特別な情報(例えば、海外での取引に対する通貨換算レートなど)がある場合、それらの情報を格納するための新たな列を動的に追加することが可能です。これがワイドカラムストアの主な特徴であり、その柔軟性とスケーラビリティを提供します。
ワイドカラムストアの主な利点は、大量のデータを高速に書き込み、読み取る能力にあります。これは、ワイドカラムストアが列ベースのデータストレージを採用しているためで、これにより特定の列のデータのみを高速に読み取ることが可能です。これは、分析クエリなど、特定の属性を持つ大量のデータを横断的に取得する必要がある場合に特に有効です。
また、ワイドカラムストアは、各行が異なるセットの列を持つことが可能であるため、非常にフレキシブルなデータモデリングが可能です。この特性は、時系列データ、地理空間データ、リアルタイム分析などのユースケースでよく利用されます。
一方、ワイドカラムストアは、リレーショナルデータベースのような厳格なトランザクション保証を持たないことが多いです。そのため、複数の操作を一連のトランザクションとして処理する必要がある場合、または複数の列ファミリ間での関連性を持つデータを扱う場合には、ワイドカラムストアが適していない場合があります。
また、ワイドカラムストアは一般的に、データ構造が一定の予測可能性を持ち、大量のデータを処理する必要があるユースケースに最適です。そのため、スキーマが頻繁に変更されるような状況では、ワイドカラムストアのデータモデリングの複雑さが障壁となる可能性があります。
グラフデーターベースとは
グラフデータベースは、エンティティ間の関係性を最も自然に表現できるタイプのNoSQLデータベースです。これらのデータベースは、エンティティ(通常は「ノード」または「頂点」と呼ばれます)とそれらの間の関係性(通常は「エッジ」または「リンク」と呼ばれます)を明確に記述するために設計されています。
エッジは方向性を持つことができ、さらに各エッジにはメタデータを付与することができます。これにより、エンティティ間の複雑な関係性を詳細に表現することが可能となります。
それでは、グラフデータベースのイメージを以下に示します。
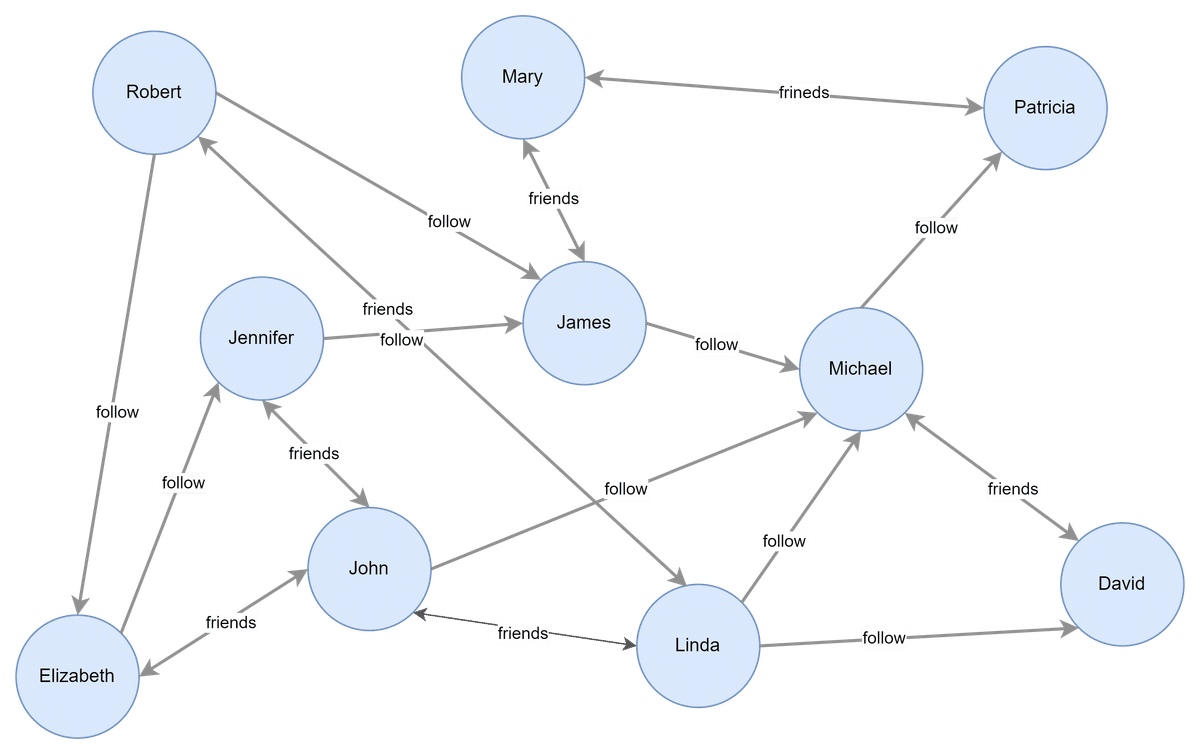
上図のように、複雑な人間関係を表したい、SNSサービスなどにおいては、グラフデータベースが特に有用な領域の1つです。ユーザーはノードとして表現され、友人関係やフォロー関係はエッジで表現します。エッジは方向性を持つため、片方向のフォローまたは相互の友人関係を明確に表現することが可能です。
このように、グラフデータベースは、エンティティ間の関係性が問題の本質である場合に非常に有力です。ソーシャルネットワーキング、推奨システム、フレームワークネットワークなどがこれに該当します。また、グラフデータベースは、パターンを検出したり、最短経路を見つけたりするための高度なクエリをサポートしています。
一方で、グラフデータベースは、単純なリストや大量の非構造化データの管理には向いていません。また、データの形式がしっかりと定義され、エンティティ間の関係性が明確でない場合や、トランザクション性が強く要求される場合には、他のタイプのデータベースが適しているかもしれません。
リレーショナルデータベースとNoSQLデータベースの比較
リレーショナルデータベース(RDBMS)は、長い間データ管理の主要なパラダイムであり、ビジネスインテリジェンス、レポート作成、トランザクション処理などの分野で広く使われてきました。これに対し、NoSQLデータベースは、大量のデータをリアルタイムで処理する必要性、データモデリングの自由度、そして水平スケーリングの需要が増えたことに対応する形で登場しました。
この章では、4つの観点からリレーショナルデータベースとNoSQLデータベースの比較をしていきます。
スキーマの柔軟性
スキーマの柔軟性について考えると、RDBMSはスキーマが固定されているため、データ構造の変更は困難です。一方、NoSQLデータベースはスキーマレスであり、データモデルの変更が容易です。これは、急速に変化するビジネス要件に対応するための柔軟性を提供します。
スケーリング
RDBMSは一般的に垂直スケーリングが必要とします。これは、データ量やトランザクションの増加に対応するためには、より高性能のハードウェアにアップグレードすることが必要という意味です。それに対し、NoSQLデータベースは水平スケーリングを可能にします。これはデータと負荷を複数のサーバに分散することを可能にします。これはデータと負荷を複数のサーバーに分散することで、大量のデータとトランザクションを処理する能力を持つということです。
データモデリング
リレーショナルデータベースは正規化されたテーブル構造とリレーションシップに基づいています。これはデータの一貫性と整合性を保つことに重点を置いています。一方で、NoSQLデータベースはキー値ストア、ドキュメントストア、カラムストア、グラフデータベースなど、さまざまなデータモデルをサポートしており、アプリケーションの具体的な要件に応じたデータモデリングを可能にします。
クエリ言語
RDBMSとNoSQLでは、クエリ言語の選択肢も異なります。RDBMSではSQL(Structured Query Language)が使用され、強力なデータ操作と分析機能を提供します。それに対し、NoSQLデータベースのクエリ言語はデータベースのタイプとプロバイダによって異なります。これは、SQLと比較してシンプルな場合もあれば、より複雑な場合もあります。
このように、リレーショナルデータベースとNoSQLにはそれぞれの特徴があり、ビジネス要件、データアクセスパターン、そしてスケーラビリティの要求に基づいて、最適なデータベース技術を選ぶことが大切になります。
混合データベース設計の例
現代のアプリケーションは多種多様なデータを取り扱い、そのデータに対する要求も非常に多様化しています。それらの要求に対応するためには、一つのデータベースタイプだけではなく、混合データベース設計がしばしば有効です。
例えば、あるECサイトでは商品データ、顧客データ、取引データなど多種多様なデータを扱うことがあります。これらのデータはそれぞれ異なる性質を持ち、それぞれ適切なデータモデルを必要とします。
商品データはその属性が多種多様であり、構造が柔軟であることが求められます。そのため、ドキュメント型のNoSQLデータベースが適しています。商品名、価格、詳細説明、カテゴリなどの情報をJSON形式で保持し、商品の属性が追加・変更されたときも柔軟に対応することが可能です。
一方で、顧客データや取引データは、データの整合性と一貫性が重要です。そのため、これらのデータはリレーショナルデータベースで管理することが適しています。顧客IDや取引IDをキーに、それぞれのデータを正規化されたテーブルに格納します。
さらに、商品の関連性や顧客間の関連性を扱う場合は、グラフデータベースが有用です。例えば、「この商品を買った人はこんな商品も買っています」や「この顧客と似た嗜好を持つ顧客はこんな人です」などの情報を効率的に取得することができます。
このように、データの性質と要求に応じて最適なデータベースタイプを選択し、それらを組み合わせることで、アプリケーションのパフォーマンスと拡張性を最大化することができます。混合データベース設計は、データを効率的に扱い、アプリケーションの成長と変化に対応する強力な手段となります。
まとめ
この記事では、リレーショナルデータベースとNoSQLデータベースの違いとそれぞれの特性、また、それらを組み合わせた混合データベース設計について説明しました。
リレーショナルデータベースは、データの整合性と一貫性を確保する上で優れた能力を持っていますが、その構造は固定的であるため、データの形式が変わったり、大量のデータを取り扱う場合には限界があります。
それに対して、NoSQLデータベースは、ドキュメント型、ワイドカラム型、キーバリュー型、グラフ型といった複数の形式があり、それぞれが異なる用途や要求に対応できます。これらは柔軟性とスケーラビリティを重視して設計されており、大量のデータや動的なデータ構造に対応することが可能です。
これらを組み合わせた混合データベース設計は、データの特性やアプリケーションの要求に応じて最適なデータベースを選択し、それらを統合することで、パフォーマンスの向上や効率的なデータ管理を実現します。
今後のアプリケーション開発においては、一つのデータベースタイプにこだわらず、それぞれの特性を理解し、適切に組み合わせることで、より効率的で柔軟なデータ管理を行うことが求められます。データベースの選択と設計は、アプリケーションの成功に大きな影響を与えるため、その理解と活用はますます重要になってきています。
この記事が少しでもデータベース設計について考えている方の手助けになれば嬉しく思います。
ここまで、読んでいただきありがとうございます。