Neo4jの自前構築に挑戦 - 無償版期限切れの対応

背景・目的
以前投稿した記事では、グラフ描画にNeo4j Auraを使用していましたが、無償版の有効期限が切れてしまい、サービスを利用できなくなりました。そこで今回は、Neo4jを自前で構築し、運用することにしました。また、以前の記事では実現できなかった、作成したグラフに対してChainlitで質問を行う機能にも挑戦してみました。
参考にした記事はこちらです:
これらの記事では、Neo4jの環境構築からPDFファイルをグラフ化する方法、そしてChainlitを利用した質問応答システムの設定まで、ステップごとに解説しています。
参考資料
今回は、日本オラクルの@ssfujita さんの記事を参考にさせていただきました。記事は非常に分かりやすく、簡潔に書かれており、大変助かりました。フジタさん、ありがとうございます!
ただ、オラクル社のクラウドサービス(OCI)は個人的に利用する財力がないため、今回はOpenAIの仕様に変更させていただきました。オラクル社には申し訳ありませんが、その点ご了承ください。
フォルダ構成
Neo4jのzipファイルを解凍し、「C:\」直下に配置しました。以下はそのツリー構造です。zipファイルのダウンロード方法については次のセクションで詳しく説明します。
C:\
├── bin # 実行ファイルを集めたフォルダ
├── conf # 設定情報を入力したconfファイルを集めたフォルダ
├── plugins # 利用するプラグインのライブラリを補完するフォルダ
├── labs # 実験的なコードや新しい技術、試作的な機能などを格納するフォルダ
└── ・・・・・サーバ側 環境設定
1. Neo4jのダウンロード
公式サイトからNeo4jのzipファイルをダウンロードします。使用したバージョンは`neo4j-community-5.24.1-windows.zip`です。
このような画面が表示されます
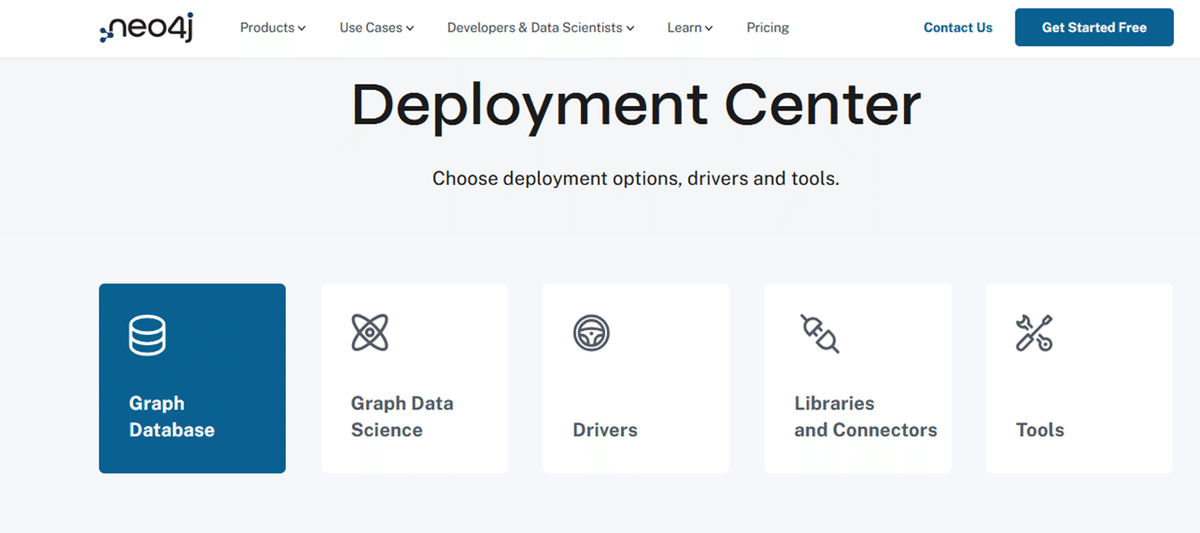
画面を下にスクロールして「Graph Database Self-Managed」というセクションに進み、赤枠で囲まれた部分からWindows用にダウンロードします。
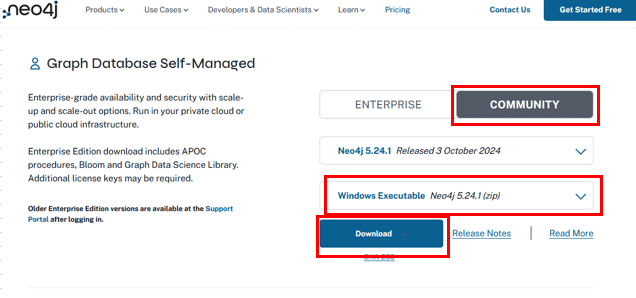
2. 解凍と配置
ダウンロードしたzipファイルを解凍し、任意の場所に配置します。私の場合はNeo4jを「C:\」直下に置きました。
3. 環境変数の設定
以下の環境変数を設定しました。
`NEO4J_HOME`:Neo4jのインストールパス
`PATH`:Neo4jのbinフォルダへのパスを追加
以下は、環境変数ダイアログで`NEO4J_HOME`を確認しているところを表しています。

4. 認証設定
初回起動時にはライセンス認証が必要です。以下のコマンドを使用して評価版ライセンスを承諾します。
bin/neo4j-admin server license --accept-evaluation商用ライセンスの場合は次のコマンドを使用します。
bin/neo4j-admin server license --accept-commercial5. サーバ起動
次に、サーバを起動するために以下のコマンドを実行します。
bin\neo4j-admin server console6. APOCプラグインのインストール
PDFを読み込む際に発生したエラーです。
Could not use APOC procedures. Please ensure the APOC plugin is installed in Neo4j and that 'apoc.meta.data()' is allowed in Neo4j configurationこのエラーの解決のため、APOCプラグインをインストールします。
neo4j.confの修正
`conf`フォルダ内の`neo4j.conf`ファイルに以下の設定を追加します。
dbms.security.procedures.unrestricted=apoc.*
dbms.security.procedures.allowlist=apoc.*APOCライブラリの配置
また、APOCライブラリ(`apoc-5.24.1-core.jar`)を`plugins`フォルダに配置します。
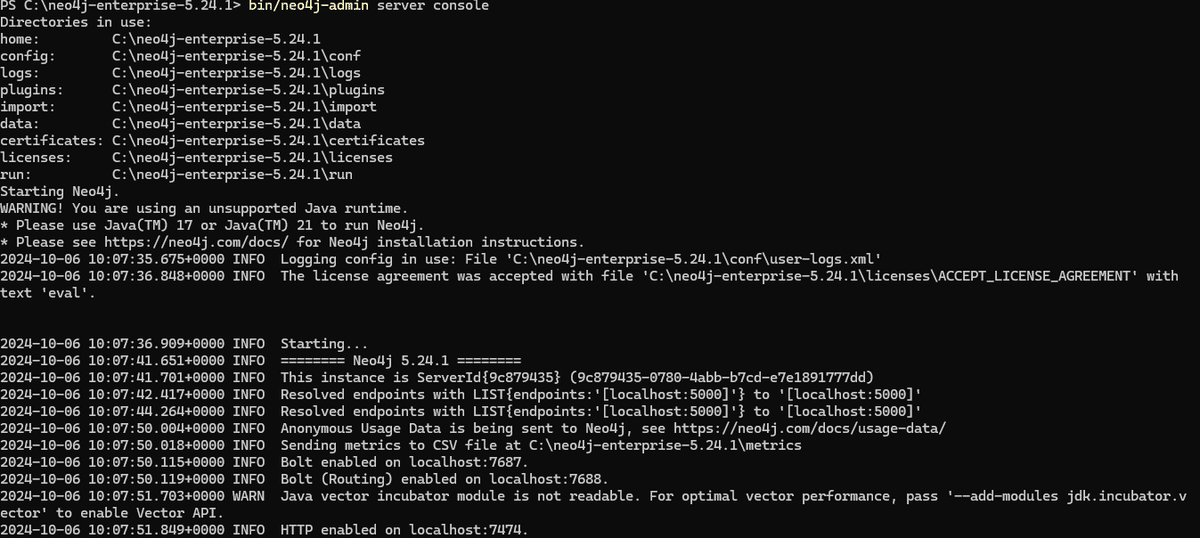
7. サーバ再起動
設定変更後はサーバを再起動し、APOCプラグインを読み込ませます。
bin/neo4j-admin server consoleやっと正常に起動しました。(エラー原因究明なども含め、所要時間2時間かかりました)
アプリ側 プログラム
1. .envファイルの設定
`Chainlit`での認証に必要な`.env`ファイルを作成し、APIキーなどを設定します。
chainlit create-secret`.env`ファイルの設定例:
CHAINLIT_AUTH_SECRET=your_secret_key今回のケースでは、自分で`.env`ファイルを`NEO4J_HOME`の直下に作成して、設定を行いました。
2. プログラムの構成
`Chainlit`を使用してPDFファイルの内容をNeo4jに保存し、質問応答を行うPythonプログラムを以下に示します。
冒頭でも述べましたが、@ssfujita(Shinjiro Fujita)さんのプログラムをOpenAI用にカスタマイズさせていただきました。
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from langchain_core.prompts import PromptTemplate
from langchain_community.vectorstores import Neo4jVector
from langchain_openai import ChatOpenAI
from langchain_community.graphs import Neo4jGraph
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_community.chains.graph_qa.cypher import GraphCypherQAChain
from typing import Optional
import chainlit as cl
from langchain_openai import OpenAIEmbeddings
# Neo4j接続情報
url = "bolt://localhost:7687"
user = "neo4j"
pwd = "*****"
db_name = "neo4j"
# chainlitアカウント情報
chainlit_user = 'admin'
chainlit_pwd = 'admin'
# embeddingモデル設定
embedding_model = OpenAIEmbeddings(model='text-embedding-ada-002')
# LLM設定
llm = ChatOpenAI(model="gpt-4o-mini")
# Chainlitの認証設定
@cl.password_auth_callback
def auth_callback(username: str, password: str):
if (username, password) == (chainlit_user, chainlit_pwd):
return cl.User(
identifier=chainlit_user, metadata={"role": "user", "provider": "credentials"}
)
else:
return None
@cl.on_chat_start
async def on_chat_start():
# ファイルアップロードの処理
files = None
while files is None:
# chainlitのファイルアップロード機能を利用
files = await cl.AskFileMessage(
# ファイルの最大サイズ
max_size_mb=20,
# ファイルをアップロードさせる画面のメッセージ
content="PDFを選択してください。",
# PDFファイルを指定する
accept=["application/pdf"],
# タイムアウトなし
raise_on_timeout=False,
).send()
loader = PyPDFLoader(files[0].path)
# テキスト抽出
pages = loader.load_and_split()
# テキスト分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=40)
docs = text_splitter.split_documents(pages)
# 分割結果を一時保存
lc_docs = []
for doc in docs:
lc_docs.append(Document(page_content=doc.page_content.replace("\n", ""), metadata={'source': files[0].name}))
# Neo4jへの接続情報を設定してgraphインスタンスを作成
graph = Neo4jGraph(
url=url,
username=user,
password=pwd,
database=db_name
)
# DB内のグラフを削除するクエリ
cypher = """
MATCH (n)
DETACH DELETE n;
"""
# 既存グラフを削除して前回の内容をリセット
graph.query(cypher)
# llmを使いドキュメントをグラフに変換するtransformerを作成
transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=["entity"], # ノードのラベルに「entity」を設定
node_properties=["text"], # ノードのプロパティに「text」を設定
relationship_properties=True # リレーションシップのプロパティ生成を「True」に設定
)
# ドキュメントをグラフに変換
graph_documents = transformer.convert_to_graph_documents(lc_docs)
# 変換したグラフをデータベースに保存
graph.add_graph_documents(graph_documents, include_source=True)
# ベクトルデータを含む検索用インデックス作成
index = Neo4jVector.from_existing_graph(
embedding=embedding_model,
url=url,
username=user,
password=pwd,
database=db_name,
node_label="entity", # 検索対象ノード
text_node_properties=["id", "text"], # 検索対象プロパティ
embedding_node_property="embedding", # ベクトルデータの保存先プロパティ
index_name="vector_index", # ベクトル検索用のインデックス名
keyword_index_name="entity_index", # 全文検索用のインデックス名
search_type="hybrid" # 検索タイプに「ハイブリッド」を設定
)
await cl.Message(content=f"`{files[0].name}` の準備が完了しました。").send()
# Cypherクエリ用のプロンプトテンプレート
template = """
Task: グラフデータベースに問い合わせるCypher文を生成する。
指示:
schemaで提供されている関係タイプとプロパティのみを使用してください。
提供されていない他の関係タイプやプロパティは使用しないでください。
schema:
{schema}
注意: 回答に説明や謝罪は含めないでください。
Cypher ステートメントを作成すること以外を問うような質問には回答しないでください。
生成された Cypher ステートメント以外のテキストを含めないでください。
質問: {question}"""
# プロンプトの設定
question_prompt = PromptTemplate(
template=template, # プロンプトテンプレートをセット
input_variables=["schema", "question"] # プロンプトに挿入する変数
)
# Cypherクエリを作成 → 実行 → 結果から回答を行うChainを作成
qa = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
cypher_prompt=question_prompt,
allow_dangerous_requests=True
)
# セッション登録
cl.user_session.set("runnable", qa)
@cl.on_message
async def on_message(message: cl.Message):
# セッション情報から設定を読み込み
runnable=cl.user_session.get("runnable")
# Chainlit設定
cb = cl.AsyncLangchainCallbackHandler(
stream_final_answer=True,
answer_prefix_tokens=["FINAL", "ANSWER"]
)
cb.answer_reached=True
# 回答生成
res=await runnable.ainvoke({"query": message.content}, callbacks=[cb])
# 回答表示
await cl.Message(content=f"\nAnswer:\n"+res['result']).send()以下に、特に説明した方が良いと思う点について、記述いたします。
接続設定
URLは`bolt://`の場合はポートが`7687`のようでしたので、そのように設定しました。また、`user`や`db_name`はデフォルトでは`neo4j`になっているようでしたので、そのまま使ってみました。
# Neo4j接続情報
url = "bolt://localhost:7687"
user = "neo4j"
pwd = "*****"
db_name = "neo4j"LLMの選択
OpenAIのモデルである、`gpt-4o-mini`を採用しました。お財布事情によるものです・・・
# LLM設定
llm = ChatOpenAI(model="gpt-4o-mini")Embeddingモデルの選択
OpenAIのモデルを使用しました。
embedding_model = OpenAIEmbeddings(model='text-embedding-ada-002')認証設定
適宜、認証設定も行っています。思い切り流用させていただきました。
# Chainlitの認証設定
@cl.password_auth_callback
def auth_callback(username: str, password: str):
if (username, password) == (chainlit_user, chainlit_pwd):
return cl.User(
identifier=chainlit_user, metadata={"role": "user", "provider": "credentials"}
)
else:
return None
実行
`Chainlit`が正常に起動しました。
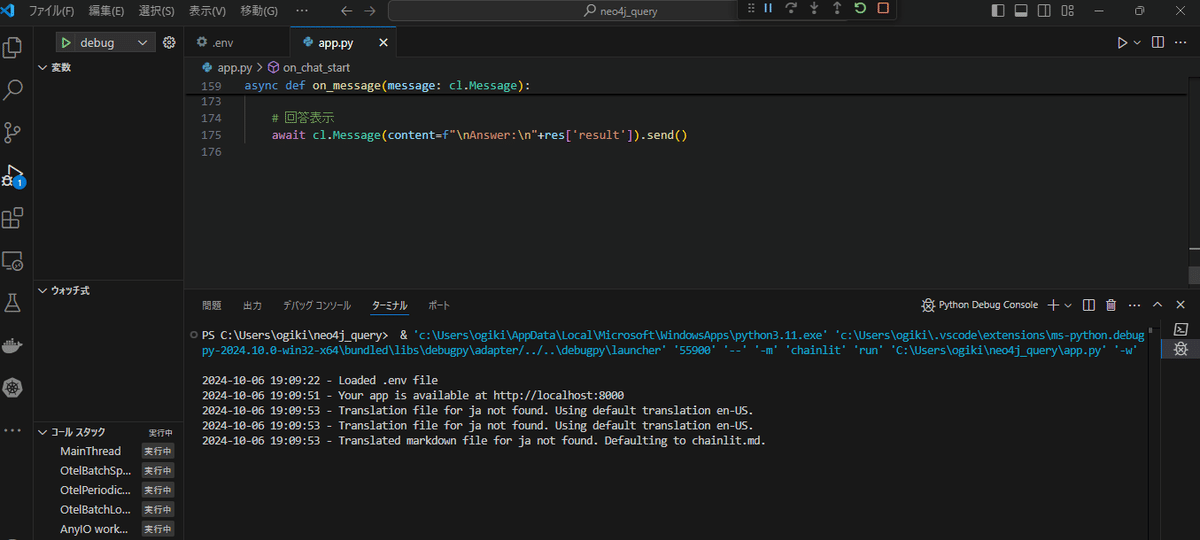
こちらが開発環境のVSCodeのイメージ画像です。
それから、こちらがWebブラウザです。

では、`Chainlit`にPDFファイルを投入してみます。正常に処理がされたようです。`chainlit`ではうんともすんとも言わないので、少し不安になりましたが、VSCodeでは完了していることを確認することができました。

プロンプト表示
では、Neo4jをみてみます。(ドキドキ)



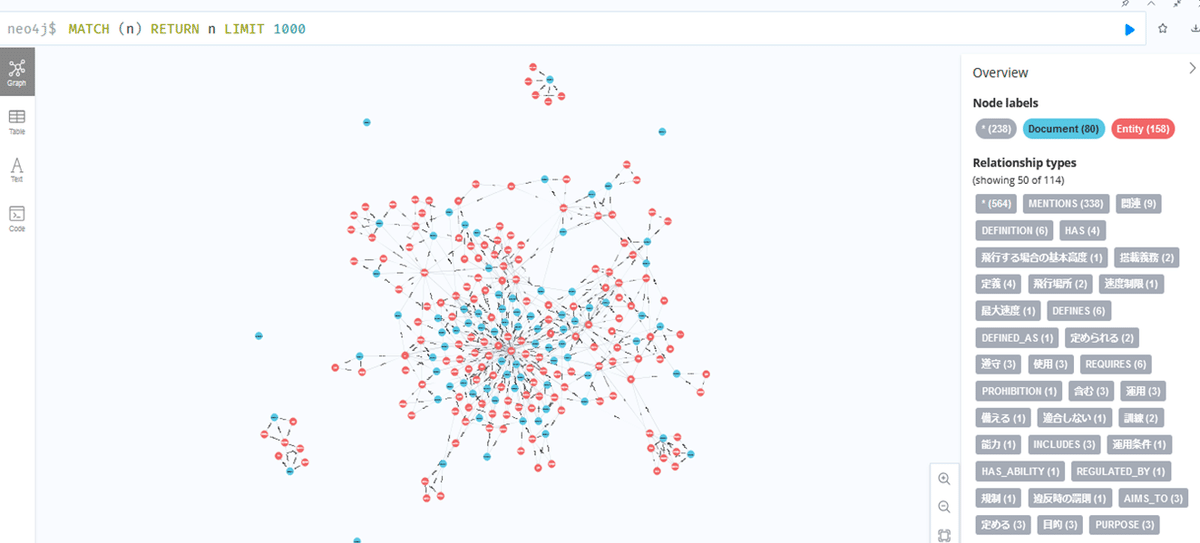
なんか出てるみたいですね。成功したように見えます。
これで、チャットの質問に答えるためのネタがそろいました。
質問受信時
では、データは出来上がったようなので、質問を投げてみることにします。
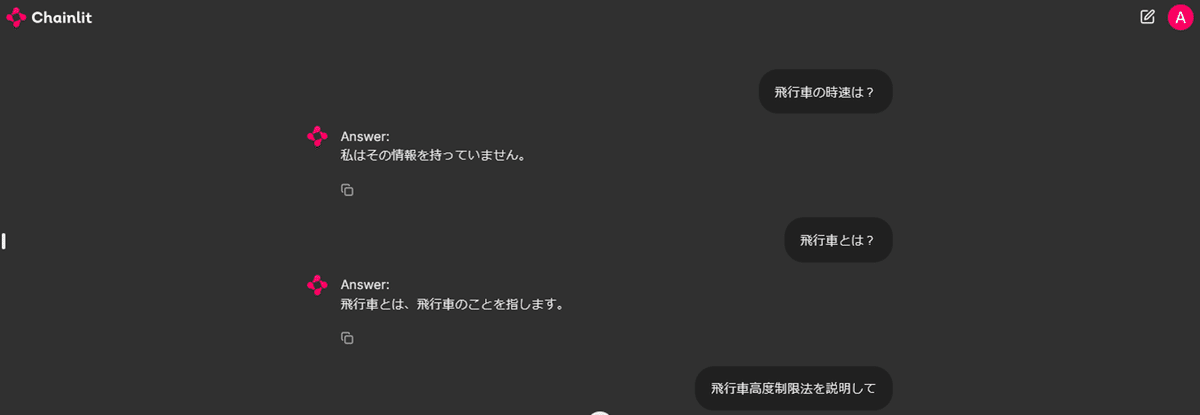
おお、なんとか食らいついてきた…
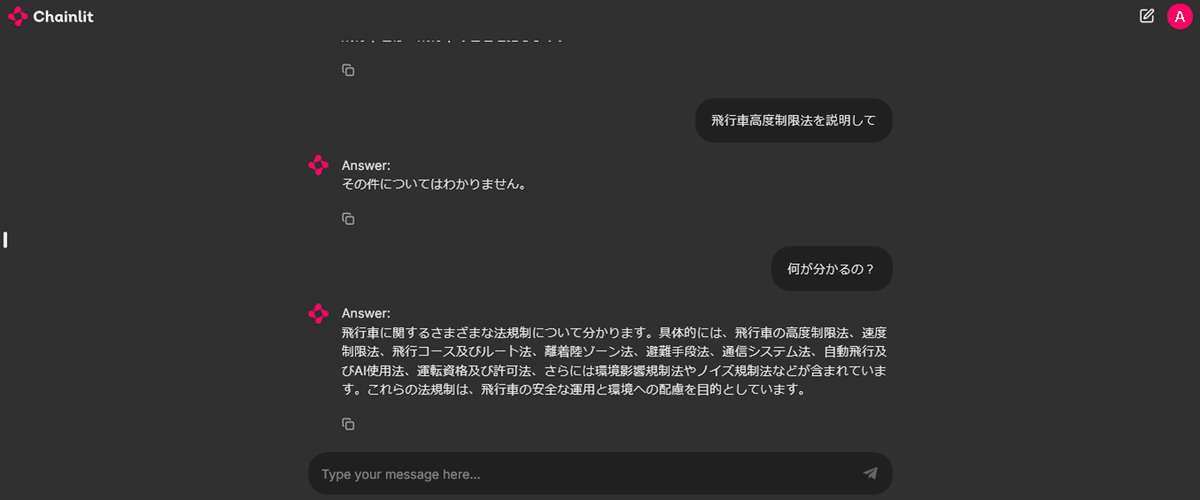
おわりに
今回の試みで、無事に`Neo4j`を自前で構築し、グラフを描画できるようになりました。しかし、回答の質が向上したかはまだ不明です。今後は、`GPT-4o`や他の高性能なモデルに切り替えて改善を図りたいと思います。