
GPUサポートに挑戦!Ollamaの処理速度向上を目指すWindowsセットアップガイド

はじめに
現在、自分のPCでOllamaを使用し、複数モデルの「処理速度」と「回答精度」に関する記事作成のため、朝から晩までフル稼働させています。PCも全力で処理をこなしているため、内蔵ファンの「ガーーー」という音が常に響いています。その結果、今朝は「電子レンジ」と「魚焼き機」を同時に使った際、普段は落ちないブレーカーがついに落ちてしまいました💦
そんなわけで、少しでも処理を速くしたいと思い、「GPUはどのくらい活用されているのだろう?」と気になり、確認してみることにしました。
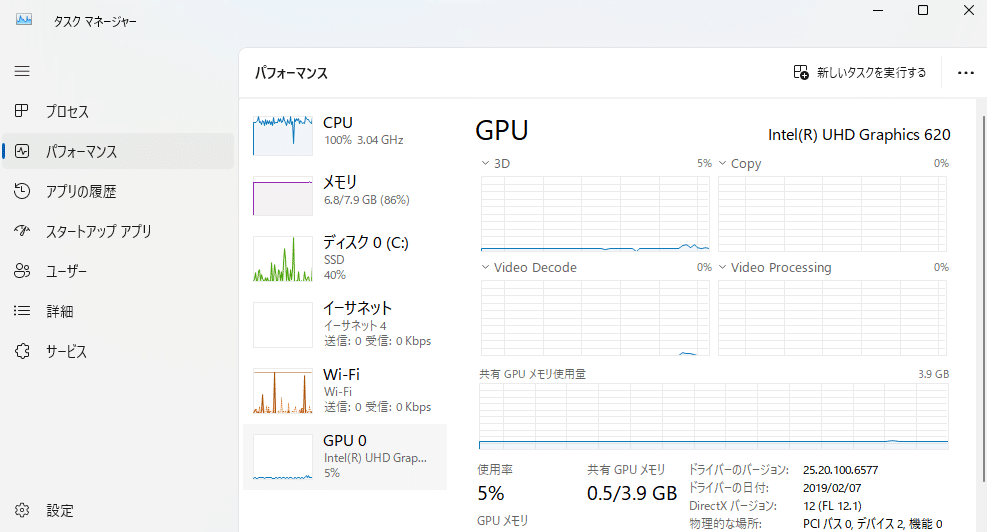
ご覧の通り、Ollamaで処理を実行しても、GPUはほとんど使われていません。調べたところ、Linux系OSでOllamaを使用する場合は、比較的簡単にGPUが活用できるようですが、Windows系OSでは少し工夫が必要なようです。そこでさらに調査を進めたところ、ちょうどこれから試そうとしている内容と同じことを扱った記事を見つけました。
@Koji_Hatayaさん、わかりやすく丁寧な記事を書いていただき、本当にありがとうございました!記事の内容をそのまま参考にさせていただいたおかげで、ほとんど問題なくスムーズに進めることができました。さすが@Koji_Hatayaさんです!
Windows系OSでOllamaがGPUを活用できるようにするためには、以下の手順が必要なようです。
`miniforge`のインストール
Pythonとそのパッケージ管理システムCondaを提供する軽量なディストリビューション。Appleシリコン(M1, M2チップ)やARMアーキテクチャに対応したパッケージを提供。
`IPEX-LLM`のインストール
`Intel`が提供する`PyTorch`拡張機能の一部で、特に大規模言語モデル(LLM)の最適化を目的としている。通常の`PyTorch`環境上で大規模言語モデルを効果的に実行するために、`Intel`アーキテクチャに最適化されたさまざまな性能向上技術が含まれている。
`llama.cpp`の実行環境セットアップ
Meta社の大規模言語モデル(`LLM`)「LLaMA(Large Language Model Meta AI)」を、効率的に動作させるための軽量なC++実装。このプロジェクトは、リソースが限られた環境、特にGPUを必要としないCPUのみの環境やモバイルデバイスで`LLaMA`モデルを動かすために開発されました。
`Ollama`サーバ起動
`Ollama`サーバを起動し、`Chainlit`や`Streamlit`を通じてローカルのLLMを活用した応答が可能になる。
それでは早速やってみます!
`miniforge`のインストール
以下のサイトからご自身のOSに合ったものをダウンロードします。私は`Windows x86_64版`をインストールしました。
このサイトの中に`README.md`があり、そこに各OSのインストールのためのモジュールについて記載があります。
ではexeファイルをダウンロードして、インストールをします。


上記ダイアログの様にチェックボックスがいくつか出てきましたが、上2つのチェックボックスをONにして、特に問題なくインストールができました。
`miniforge`をインストールすると、アイコンが表示されます。「管理者権限」で実行するのがよいようですので、マウスの右クリックをして「管理者として実行」を選択すればよいかと思います。

これを起動すると、プロンプト画面が表示されます。

今後は、この画面に対して、いろいろコマンドを打って行きます。
`IPEX-LLM`のインストール
`miniforge`から起動したプロンプトで、以下のコマンドを実行します。
conda create -n llm-cpp python=3.11
conda activate llm-cpp
pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0
pip install --pre --upgrade ipex-llm[cpp]`llm-cpp`という`Python`の仮想環境が作成され、「IPEX-LLM」がインストールされます。
`llama.cpp`の実行環境セットアップ
続けて`miniforge`で起動したプロンプトで、以下のコマンドを実行します。
mkdir llama-cpp
cd llama-cpp
conda activate llm-cpp
init-llama-cpp.bat
init-ollama.batこの後に、作成したディレクトリ`llm-cpp`にパスを通します。
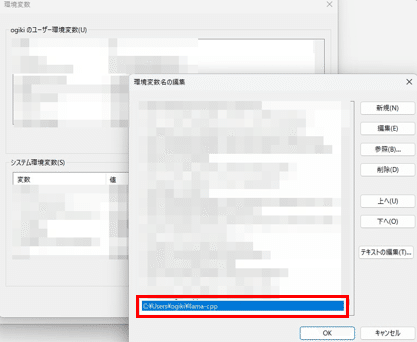
`Ollama`サーバ起動
ここまでの準備ができましたら、`Ollama`を起動します。
私の場合、

以前インストーラによる`Ollama`をインストールしており、競合する可能性があるので、インストーラによる`Ollama`は`Quit`します。
それでは、環境変数を予め設定して、`Ollama`を起動します。
conda activate llm-cpp
set OLLAMA_NUM_GPU=999
set no_proxy=localhost,127.0.0.1
set ZES_ENABLE_SYSMAN=1
set SYCL_CACHE_PERSISTENT=1
set OLLAMA_HOST=0.0.0.0
set OLLAMA_ORIGINS=*
(set SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1)これは外した方がパフォーマンス上がるかも
(ollama pull *** (複数モデルをPULL))
ollama serveまず`conda activate llm-cpp`で環境を整えて、環境変数をセットしてください。
初回はモデルが`PULL`されていないので、`llm`や`embedding`モデルを`PULL`してください。
その後`ollama serve`でサーバ起動することになります。
いろいろな記事では、「`llm`用にもう1つOllamaを起動させる」となっていますが、既に`PULL`しているので、私の場合はその必要がないように思います。
処理結果
幾つか流してみ

たのですが、GPUは利用されていませんでした。
うーん、なんでだろう...
よく見ると、intellのGPUはサポートされていない可能性有りでした。
非常に残念です。次回は「NVIDIA」で試してみましょうか…(高額なPCになっちゃうかな)