
一気通貫で実現するLlama3.2: ローカルLLMとローカルEmbeddingの構築

はじめに
前回、自宅のPCに軽量な「オープンLLM」であるLlama3.2を導入し、その性能を確認しました。レスポンスもまずまずで、緊急性の低いプロジェクトであれば十分に活用できることが分かりました。これは非常に喜ばしい結果です。
ただ、これだけでは「自前のRAG」を作成するにはまだ不十分です。もう一つ必要なものがあり、それが「embedding」です。これは文章をベクトル化する技術で、クラウドサービスではすでに利用可能ですが、オンプレミス環境でのオープンソースによる情報はなかなか見つかりませんでした。そんな中、以下の投稿記事でヒントを得て、「自前のembedding」を構築する手がかりを掴むことができました。
この記事には、embeddingモデルについても触れられていたので、「もしかしてollamaからpullすれば、自宅のPCにもembeddingモデルを持ってこれるんじゃない?」(若者風に)と思い、少し試してみたところ、無事に取得することができました。@misu007さんのおかげです。分かりやすい投稿記事、本当にありがとうございました!
結果的に、LLMからembeddingまで、すべてを「自前」で構築することができました。今回は「自前のembedding」構築と、その過程で直面した課題についてご紹介します。構築時にエラーなどで悩んだ際には、この記事が皆様の助けになれば幸いです。
embeddingモデルの導入
今回は、Ollamaのインストールが前提となります。まだインストールされていない方は、以下の投稿記事を参考にしていただければ幸いです。
インストールが完了したら、次に「コマンドプロンプト」または「PowerShell」で以下のコマンドを実行してください。(以下の説明はWindows OSを前提としています。)
モデルの違いがよく分からなかったため、今回は一般的に使われていそうな`mxbai-embed-large`を適用してみました。
ollama pull mxbai-embed-largeすると、以下のような画面が表示され、モデルのダウンロードが開始されます。

`success`と表示されたので、無事に処理が成功したようです。これで、embeddingモデルの取り込みが完了しました。
プログラムの紹介
今回は、ベクトル・データベース(`SQLite`)にデータを登録するプログラム(`chroma_retriever.py`)と、そのデータベースを使用して質問に対して回答を行うプログラム(`chroma_streamlit.py`)をご紹介します。
まず、データベースに登録するプログラムについてです。
import glob
import os
import xml.etree.ElementTree as ET
from dotenv import load_dotenv
from langchain.text_splitter import CharacterTextSplitter
from langchain_chroma import Chroma
import ollama
load_dotenv()
docs = []
# 埋め込み関数のラッパーを作成
class OllamaEmbeddingFunction:
def __init__(self, model):
self.model = model
def embed_documents(self, texts):
embeddings = []
for text in texts:
response = ollama.embeddings(model=self.model, prompt=text)
embeddings.append(response['embedding'])
return embeddings # ここで計算した埋め込みを返します
# 取り出したい名前空間-タグ名
name_spaces_tag_names = [
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PublicationNumber",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PublicationDate",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}RegistrationDate",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}ApplicationNumberText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PartyIdentifier",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}EntityName",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PostalAddressText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PatentCitationText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PersonFullName",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}P",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}FigureReference",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}PlainLanguageDesignationText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}FilingDate",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}InventionTitle",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}MainClassification",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}FurtherClassification",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}PatentClassificationText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}SearchFieldText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}ClaimText",
]
def set_element(level, trees, el):
trees.append({"tag" : el.tag, "attrib" : el.attrib, "content_page" :el.text})
def set_child(level, trees, el):
set_element(level, trees, el)
for child in el:
set_child(level+1, trees, child)
def parse_and_get_element(input_file):
tmp_elements = []
new_elements = []
tree = ET.parse(input_file)
root = tree.getroot()
set_child(1, tmp_elements, root)
for name_space_tag_name in name_spaces_tag_names:
for tmp_element in tmp_elements:
if tmp_element["tag"] == name_space_tag_name:
new_elements.append(tmp_element)
return new_elements
title = ""
entryName = ""
patentCitationText = ""
files = glob.glob(os.path.join("C:/Users/ogiki/JPB_2023185", "**/*.*"), recursive=True)
for file in files:
base, ext = os.path.splitext(file)
if ext == '.xml':
topic_name = os.path.splitext(os.path.basename(file))[0]
print(file)
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0)
new_elements = parse_and_get_element(file)
for new_element in new_elements:
try:
text = new_element["content_page"]
tag = new_element["tag"]
title = text if tag == "{http://www.wipo.int/standards/XMLSchema/ST96/Patent}InventionTitle" else ""
entryName = text if tag == "{http://www.wipo.int/standards/XMLSchema/ST96/Common}EntityName" else ""
patentCitationText = text if tag == "{http://www.wipo.int/standards/XMLSchema/ST96/Common}PatentCitationText" else ""
documents = text_splitter.create_documents(texts=[text], metadatas=[{
"name": topic_name,
"source": file,
"tag": tag,
"title": title,
"entry_name": entryName,
"patent_citation_text" : patentCitationText}]
)
docs.extend(documents)
except Exception as e:
continue
# OllamaEmbeddingFunctionのインスタンスを作成
embedding_function = OllamaEmbeddingFunction(model='mxbai-embed-large')
db = Chroma(persist_directory="C:/Users/ogiki/vectorDB/local_llm_chroma", embedding_function=embedding_function)
intv = 500
ln = len(docs)
max_loop = int(ln / intv) + 1
for i in range(max_loop):
splitted_documents = text_splitter.split_documents(docs[intv * i : intv * (i+1)])
db.add_documents(splitted_documents)このプログラムでは、埋め込み処理を自前のOllamaEmbeddingFunctionを使って行うようにしています。
# OllamaEmbeddingFunctionのインスタンスを作成
embedding_function = OllamaEmbeddingFunction(model='mxbai-embed-large')また、必要なライブラリの`import`部分も追加しています。
import ollamaOpenAIの埋め込み(Embedding)関数とは異なる挙動を持つため、互換性を保つためにラッパー関数を作成し、処理に適用しています。
# 埋め込み関数のラッパーを作成
class OllamaEmbeddingFunction:
def __init__(self, model):
self.model = model
def embed_documents(self, texts):
embeddings = []
for text in texts:
response = ollama.embeddings(model=self.model, prompt=text)
embeddings.append(response['embedding'])
return embeddings # ここで計算した埋め込みを返します次に、質問に対して回答を行うプログラムをご紹介します。
import streamlit as st
from langchain_community.chat_models.ollama import ChatOllama
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
from langchain.vectorstores import Chroma
import ollama
# 埋め込み関数のラッパーを作成
class OllamaEmbeddingFunction:
def __init__(self, model):
self.model = model
def embed_documents(self, texts):
embeddings = []
for text in texts:
response = ollama.embeddings(model=self.model, prompt=text)
embeddings.append(response['embedding'])
return embeddings # ここで計算した埋め込みを返します
def embed_query(self, query):
response = ollama.embeddings(model=self.model, prompt=query)
return response['embedding'] # クエリの埋め込みを返す
embedding_function = OllamaEmbeddingFunction(model='mxbai-embed-large')
chat = ChatOllama(model="llama3.2", temperature=0)
database = Chroma(
persist_directory="C:/Users/ogiki/vectorDB/local_llm_chroma",
embedding_function=embedding_function
)
prompt = PromptTemplate(template="""文章を元に質問に答えてください。
文章:
{document}
質問: {query}
""", input_variables=["document", "query"])
# =====================================================
st.title("特許検索システム")
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
input_message = st.chat_input("準備ができました!メッセージを入力してください!")
text_input = st.text_input("ここに番号を入力してください")
if input_message:
st.session_state.messages.append({"role": "user", "content": input_message})
print(f"入力されたメッセージ: {input_message}")
with st.chat_message("user"):
st.markdown(input_message)
with st.chat_message("assistant"):
# ----- VectorDBからドキュメントを取得 (ローカルEmbeddingを利用) -----
documents = database.similarity_search_with_score(input_message, k=3, filter={"name":text_input})
documents_string = ""
for document in documents:
print("---------------document.metadata---------------")
print(document[0].metadata)
print(document[1])
documents_string += f"""
---------------------------
{document[0].page_content}
"""
print("---------------documents_string---------------")
print(input_message)
print(documents_string)
# ----- プロンプトを基に回答をもらう (ローカルLLMを利用) -----
result = chat([
HumanMessage(content=prompt.format(document=documents_string,
query=input_message))
])
st.markdown(result.content)
st.session_state.messages.append({"role": "assistant", "content": result.content})こちらのプログラムには、以下のクラス(`OllamaEmbeddingFunction`)が追加されています。これが今までの部分と異なる点です。エラーの原因を特定し、このラッパー関数を解決策として考えるのに多くの時間と労力を費やしました。次章でその内容について説明いたします。
# 埋め込み関数のラッパーを作成
class OllamaEmbeddingFunction:
def __init__(self, model):
self.model = model
def embed_documents(self, texts):
embeddings = []
for text in texts:
response = ollama.embeddings(model=self.model, prompt=text)
embeddings.append(response['embedding'])
return embeddings # ここで計算した埋め込みを返します
def embed_query(self, query):
response = ollama.embeddings(model=self.model, prompt=query)
return response['embedding'] # クエリの埋め込みを返す苦労したポイント
ラッパー関数の導入(思いついた経緯)
今回のプログラミングで最も苦労したのは、既存のプログラムを流用する際に、利用ライブラリ内部でエラーが発生し、その解決に多くの時間を要した点です。これまではエラーが発生しても自分のプログラムを修正すればよかったのですが、ライブラリ内部のエラーでは、原因の特定や対応策の確定が容易ではありませんでした。
例えば、以下のようなエラーが発生しました。

これは`chroma_retriever.py`でのエラーです。
db.add_documents(splitted_documents) # <==ここで発生`db`がディクショナリ型データの中で`embed_documents`を必要としているようですが、そのようなデータが見当たりません。`OpenAI`の埋め込みを使用していた際にはエラーがなかったため、その時は`embed_documents`が存在していたのでしょう。しかし、`Ollama`ではそれが欠損しているため、影響を与えない解決策としてラッパーを思いつきました。
このラッパー(`OllamaEmbeddingFunction`)は、コンストラクタで`model`を引数として受け取り、それをメンバ変数として保存します。また、`embed_documents()`では渡されたテキストを埋め込み、`embeddings`に追加します。この修正により、`chroma_retriever.py`は正常に処理を続行できるようになりました。
次に`chroma_streamlit.py`ですが、同じラッパーをこのファイルにも定義したため、同じエラーは回避できました。しかし、新たに以下のエラーが発生しました。もうお手上げです…

最後の手段として、ChatGPTの`gpt-4o`無料枠を利用し、いろいろ質問をしてみました。その結果、先ほどのラッパーに`embed_query()`を追加するという提案を受けました。このアイデアは私には全く思い浮かばなかったのですが、一旦そのまま受け入れて実行してみました。
# 埋め込み関数のラッパーを作成
class OllamaEmbeddingFunction:
def __init__(self, model):
self.model = model
def embed_documents(self, texts):
embeddings = []
for text in texts:
response = ollama.embeddings(model=self.model, prompt=text)
embeddings.append(response['embedding'])
return embeddings # ここで計算した埋め込みを返します
def embed_query(self, query):
response = ollama.embeddings(model=self.model, prompt=query)
return response['embedding'] # クエリの埋め込みを返すこれにより、無事に回答を得られるようになりました。ついに念願の「自前一気通貫」が実現しました!
実行結果
chroma_retriever.py
処理実行時間がかなりかかりました。OpenAIを適用していた場合は1,000ファイルで約30分でしたが、Ollamaを使用すると、2ファイルで30分程度かかってしまいました。あまりに時間がかかったため、一時的に2ファイルのみをベクトル・データベースに登録しました。
chroma_streamlit.py
こちらはそれほど時間を要せずに起動しました。また、検索結果も20〜40秒程度で返ってきました。生成AIに対して3つの質問をしてみました。
質問 | フューリンの意味は?
私はフューリンについての理解が不十分ですが、恐らく誤りです。

ログからは一応ベクトル・データベースから候補を取得しているようですが、得られた情報が薄いため、LLMに対して平均的な回答を求めている様子です。

質問 | フューリンのマウス実験のことをおしえて
こちらも一般的な回答のように見えます。ログを確認してみます。

こちらも、ベクトル・データベースから候補を取得している様子が見受けられますが、情報が薄いため、LLMに対して平均的な回答を求めているようです。

ベクトル・データベースからの取得結果は満足いくものではないため、回答の信頼性は今後の課題ですが、データを取得できたことは確認できました。
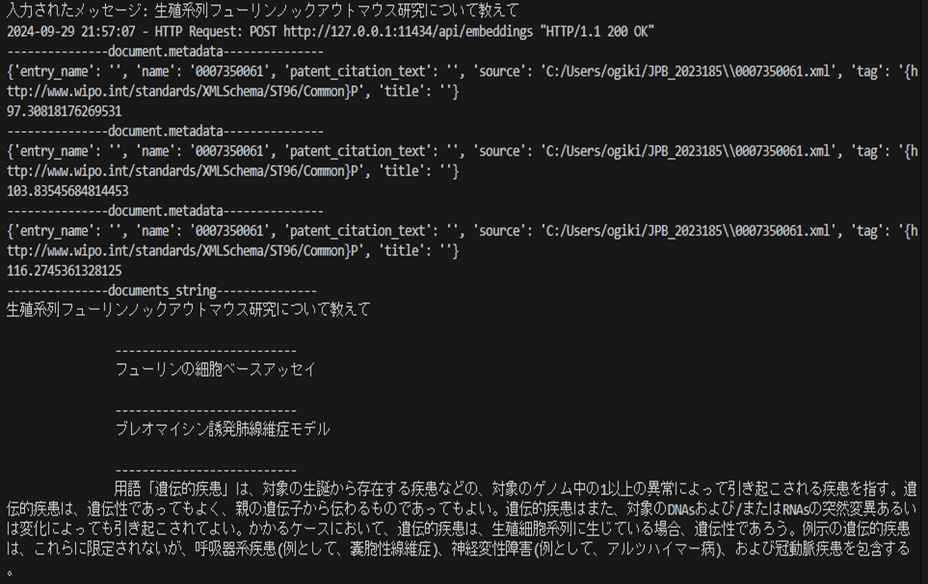
質問 | 生殖系列フューリンノックアウトマウス研究について教えて
最後の質問です。こちらの回答は充実しているように見えます。

ログ結果も確認してみると、やはり最後の候補でしっかり情報を取得しているようで、充実した回答のように見えています。
おわりに
ついに「全て自前でLLMを構築」を達成しました!ただ、特に埋め込みの性能には課題があるため、他のモデルでも試してみたいと思います。これで完全にクローズドなLLMが実現できることを証明できました。
最後までご覧いただき、ありがとうございました。