
はじめてでもUTAU音源(連続音)を作ろう!

難しいことを考えずとりあえず音源が作れるようになることを目的とした記事です。
何もわからないけど音源を作りたいな~と思った時に音源制作がもう少しとっつきやすくなればいいな、という気持ち。
ノイズ処理とかクオリティを上げるための云々は一旦慣れてからでいいんじゃないかなって思うんです。
UTAU本体のダウンロードはこちら
0-1:UTAU音源の種類
代表的なものとして下記の三つがあります。
・単独音(CV)
・連続音(VCV)
・CVVC
本記事では連続音の制作をしていこうと思います。
単独音の方が簡単に作れるのですが、クオリティに関わらず連続音を1つでも作れれば音源制作にある程度慣れることが出来るだろうという意図です。
C=子音/V=母音 なので、
単独音:「あ」「か」のように一つの音声ファイルにつき1音だけ収録する。
連続音:「あんああいあうあ」「かんかかきかくか」のように一つの音声ファイルにつき複数の音を繋げて収録する。一音が「母音 子音 母音」のようになる。
CVVC:連続音と同じように収録するが、連続音より細かく音を分ける。「子音」「母音 子音」「子音」…というように音が分けられる。
ここら辺の細かい事は後々わかるようになってくると思うので一旦わからなくても問題ないです。
0-2:制作の流れ
1:収録
2:原音設定
3:周波数表生成
原音設定とか周波数表とか何?という感じですが、周波数表生成に関しては自動で処理されるので、実際に作業するのは収録と原音設定だけです。
原音設定は収録した音をUTAUで使用できるように切り分けたりする みたいな作業です。
1:収録
まずは収録をしましょう。
呪文を一定の音程・テンポで読み上げます。お経を読むみたいなイメージ。
下準備
今回は「OREMO」というソフトを使用します。
ダウンロードと解凍をしておいてください。
こちらは最新版を導入しておけばとりあえず問題はないと思います。
また、収録するにあたって読む文(録音リスト)と一定のテンポで読むためのガイドBGMが必要になります。
録音リスト
ガイドBGM
これらを選ぶにあたって、1回につき何音収録するか と どれくらいの速さで読むか を決める必要があります。
録音リストの「○モーラ」という部分がひとつの文に何個音が入っているのかになります。
例えば3モーラだったら「ああい」「いいう」のように一文3音、
5モーラなら「ああいあう」「いいあうえ」のように一文5音。
基本的にモーラ数が多いほど効率が良く、収録時間も短くなります。
ただし、モーラ数が多いとそれだけ連続で声を出し続けることになるので肺活量が必要だったり、そもそも長い文になるので読みづらくなったりします。
ガイドBGMは、どれくらいの早さで読むかとどの音程で読むかのガイドになります。
ガイドBGMが早ければ早いほど収録効率が上がり、肺活量も必要なくなりますが、完成した音源を歌わせた時に音が劣化しやすくなります。
逆にガイドBGMが遅ければ遅いほど収録効率は下がり、肺活量も必要になりますが、音の劣化は少なくなります。
個人的には120~140BPMあたりが丁度いいかなと思っています。
収録の準備
OREMOを起動します。
すると、こんな感じの画面が出ると思うので、まずは設定をします。

まず、ファイルの音名リストの読み込みから先ほどダウンロードした収録リストを読み込みます。

次に、オプションの収録方法の設定を開きます。

・録音モードを自動録音その2にします。
・BGMファイルから先ほどダウンロードしたガイドBGMを読み込みます。
収録したい音の高さに合わせて読み込んでください。
テキストファイル(.txt)ではなく音声ファイル(.wav)を読み込みます。

※キー(音の高さ)について
B:シ
A:ラ
G:ソ
F:ファ
E:ミ
D:レ
C:ド
ちょっとだけ収録しやすくなる設定
私が収録の際にしている設定です。少し楽になりますが、やらなくてもいい人は「収録!」まで飛ばしても大丈夫です。
表示からF0を表示をつけておきます。
これをしておくと収録した音域がわかるようになります。

オプションの詳細設定を開きます。
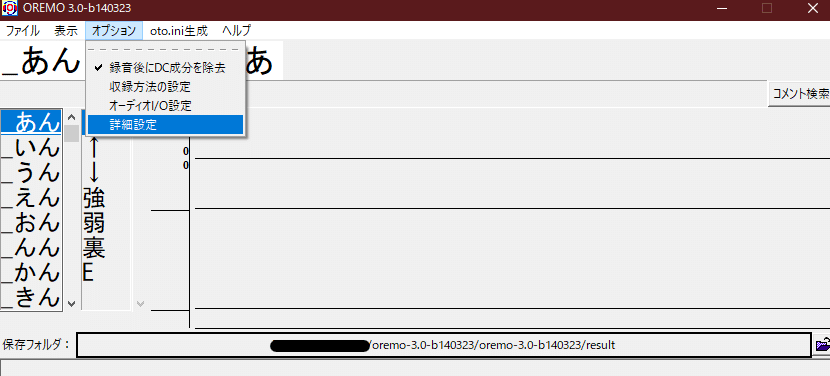
・「描画範囲を固定する」「各音の線の描画をする」「発声したい音の線を描画する」にチェックを入れます。
・「発声したい音の線を描画する」のターゲット音を自分が収録したいキーに設定します。
・「描画範囲を固定する」の最大値と最小値を設定します。
自分が収録したいキーから 半音も含めて大体2つくらい離れたキーにしておくと良いと思います。
(例:G3を収録したい場合、最大値はG3より2つ上のA3、最小値は2つ下のF3)

表示から音叉窓を表示をしておきます。

ガイド音選択で収録したいキーを設定しておきます。
収録音がわからなくなったら再生して音を確かめましょう。

収録!
収録をしていきましょう!
キーボードの「R」を押すことで録音が開始され、もう一度押すことで録音が止まります。
画面の左下に状態が表示されるので、「発声はじめ!」が表示されている間に収録をしましょう。
最初は一度声を出さずに流してみて、どのタイミングで声を出せばいいんだな、というのを確かめると良いと思います。
また、「発声はじめ!」が表示されている間は録音を止めることが出来ないので注意してください。





収録する際の注意点として、一文を途切れ途切れに読むのではなく、一文を繋げて読んでください。
イメージとしては下の動画のような感じです。(私はガイドBGMとして「RND.K式8モーラ向けガイドBGM (Dubstep MIX)」を使用しています。)
あとは最後までこの調子で収録するだけなのですが、
最後の方に出てくる「くぁ行」や、「ガ行」(鼻濁音で収録する「が行」)などは使用頻度が低かったり発声が難しかったりするので必ずしも収録する必要はないです。
慣れてきたり、必要だと思ったら収録する程度で問題ありません。
収録が終わったら、特に設定を変えていなければOREMOのフォルダ内のresultというフォルダに収録したデータが入っているので、デスクトップなどに わかりやすい名前のフォルダを新しく作って、中身を全てそちらに移しておいてください

2:原音設定
出来るだけ楽にできるような方法を解説しますが、恐らく慣れるまで(慣れても)一番大変な作業です。頑張りましょう。
結局原音設定って何?
先ほど収録した音声のことを原音と呼ぶのですが、その原音をUTAUで使えるように設定していく作業です。
ざっくりと説明すると以下のようなことを設定します。わからなくても作業はできるので一旦問題はないです。
・音の中でどこからどこまでを使うか
・音の始まりはどこか
・音の中で引き延ばしていい部分/引き延ばしてはいけない部分はどこか
・前の音と合成するときにどこまでを使がる部分として扱うか
下準備
今回は「SetParam」というソフトを使用します。
ダウンロードと解凍をしておいてください。
最新版をダウンロードしておけば問題ないと思います。
SetParamだけでもある程度の自動推定はできるのですが、今回は作業の短縮のために精度をよくするプラグインを使用します。
以下のMoresamplerとMoreLauncherをダウンロードと解凍をしておいてください。
Moresampler
MoreLauncher
MoreLauncherをSetParamのpluginsフォルダにフォルダごと入れてください。



(MoreLauncherのフォルダを開いたときに中身がこのような感じになっていれば問題なし)
Moresamplerはわかりやすい場所に置いておいてください。(本来はUTAUのエンジンとして使用するものなのでUTAUのフォルダに入れておくとよいかもしれないです。)
最後に、こちらをダウンロードして解凍もしておいてください。
原音設定の自動推定
SetParamを起動します。
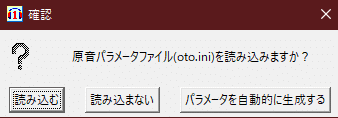
起動すると保存フォルダの選択が出てくると思うので、先ほど収録した原音が入ったフォルダを開いて、フォルダーの選択を押してください。

するとこのような画面が表示されるので、パラメータを自動的に生成するを選択します。
次の画面で、プラグインで自動推定の中のMoreLauncherを選択します。

するとこのような画面が出るので、順番に設定していきます。
初めに、1.の部分でMoresamplerを読み込んでください。
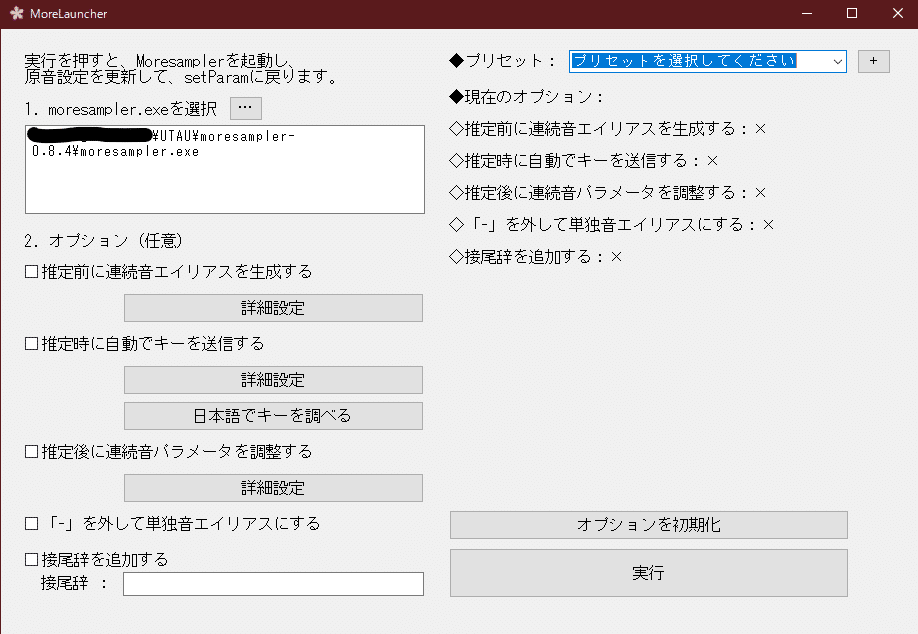
推定前に連続音エイリアスを生成するにチェックを入れて、詳細設定を開きます。

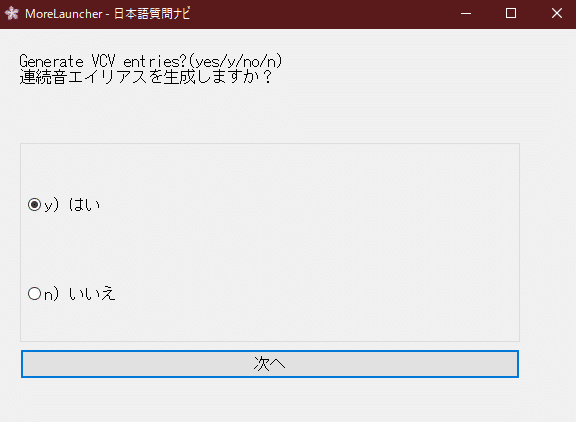
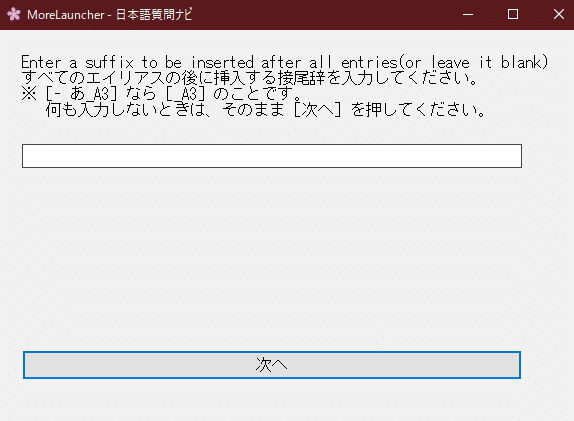
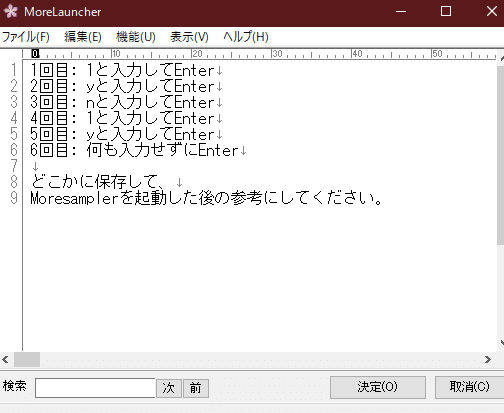
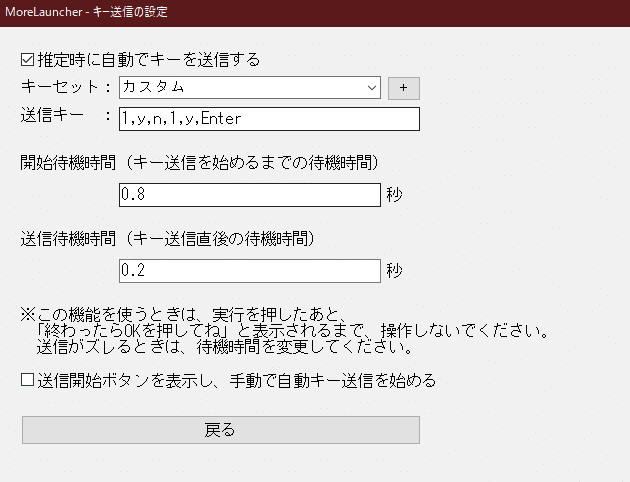
推定時に自動でキーを送信するにチェックを入れて日本語でキーを調べるを開きます。

以下のように設定していって下さい





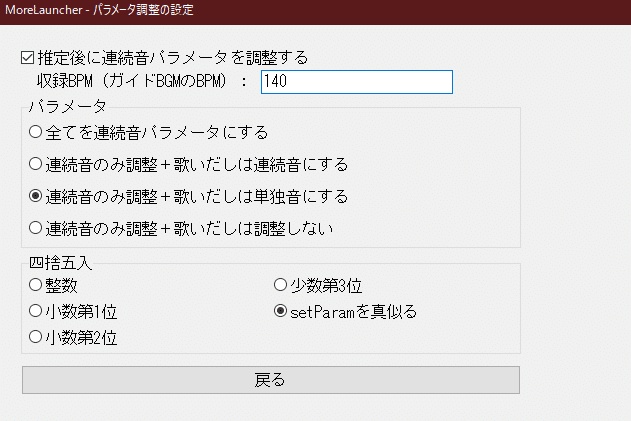
推定後に連続音パラメータを調整するにチェックを入れて詳細設定を開きます。
下記のように設定します。収録BPMはあなたが収録したガイドBGMのものと同じにしてください。
終わったら「戻る」
プリセットを設定します。「_連続音_収録BPM〇〇」のうち、あなたが収録したガイドBGMのBPMと同じものに設定してください。
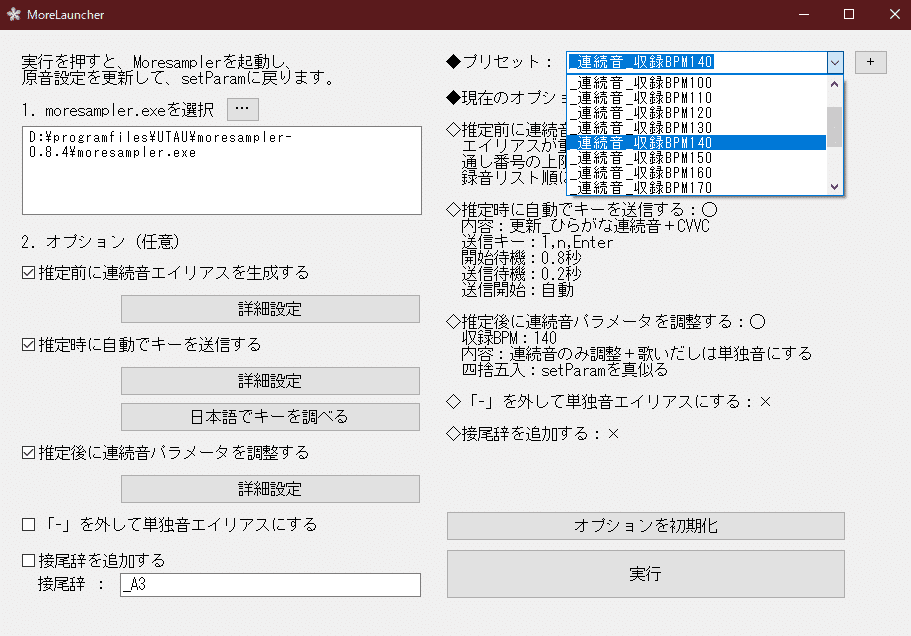
設定が終わったら「実行」をクリックして、「終わったらOKを押してね」と表示されるまでは何の操作も行わないでください(PCに触れないでください。)
コマンドプロンプト(黒い画面)に「続行するには何かキーを押してください…」と表示されたらMoreLauncherの「OK」を押してください

そうするとSetParamが動くようになり、原音が読み込まれた状態になります。
スペクトルが表示されていなかったりするかもしれませんが、設定は一旦後でやるので画面の表示に違いがあっても大丈夫です。

一旦上書き保存をしてSetParamを閉じます。
上書きしていいか確認が入ると思いますが、「はい」で大丈夫です。
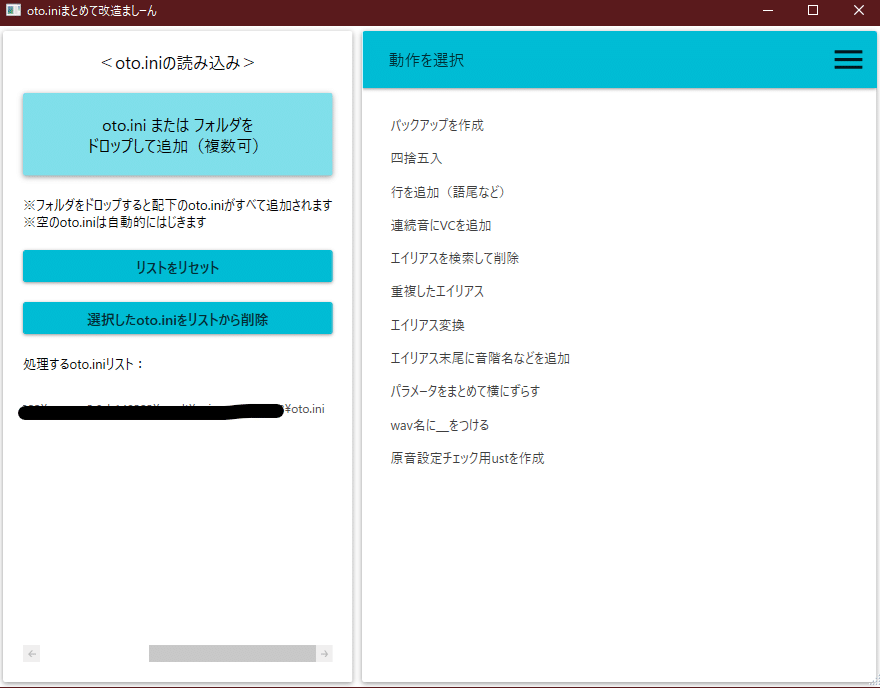
次にotoiniまとめて改造ましーんを開きます。
こんな感じの画面が開かれるので、原音と同じフォルダに生成されているoto.ini(拡張子が見える設定にしていない場合はoto)というファイルを左上のoto.ini または フォルダをドロップして追加というところにドラッグ&ドロップします。


左下に表示されれば成功です。
次に重複したエイリアスを開きます。

重複を自動的に削除 と 数字付きのエイリアスを削除を行います。

両方終わったらotoiniまとめて改造ましーんを閉じて、もう一度SetParamを開きます。
先ほどのようにフォルダを選択して、この部分でoto.iniを読み込みます。

oto.iniを開きます。
先ほどと同じような画面が開かれます。
SetParamの設定
ここで一旦SetParamの設定をします。
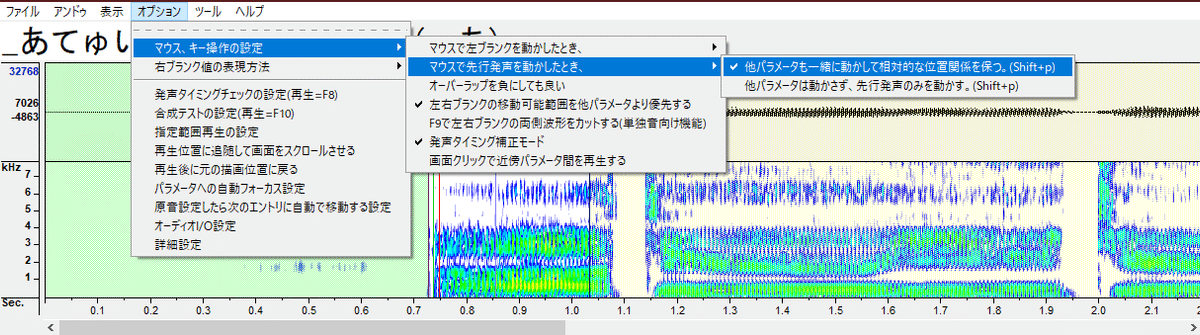
・「オプション」の「マウス、キー操作の設定」の「マウスで左ブランクを動かしたとき、」の「他パラメータは動かさず、左ブランクのみを動かす」を選択します。
・「オプション」の「マウス、キー操作の設定」の「マウスで先行発声を動かしたとき、」の「他パラメータも一緒に動かして相対的な位置関係を保つ」を選択します。
・「オプション」の「マウス、キー操作の設定」の「発声タイミング補正モード」にチェックを入れます。

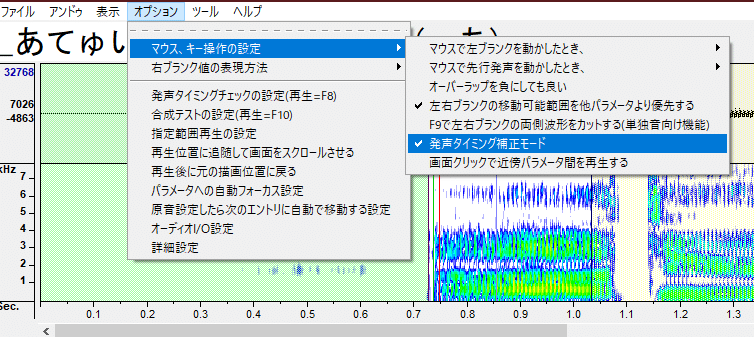
・「表示」の「スペクトルを表示」にチェックを入れます。
・「オプション」の「詳細設定」を開き、左の中央上位にある「スペクトルの色」を「color2」にします。



原音設定!
一旦、連続音の形式と用語についてまとめます。
連続音は「- あ」「a い」のように表記されます。
アルファベットの部分は前の音の母音です。[-/a/i/u/e/o/n]の7種類があります。
なので、「a い」を再生すると「ぁい」という感じになります。
「-」は前に音がない部分、「n」は「ん」です。
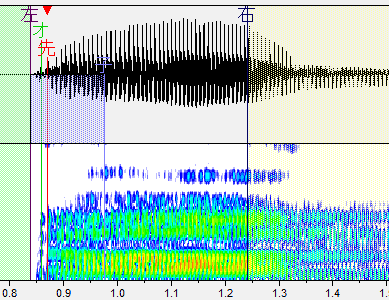
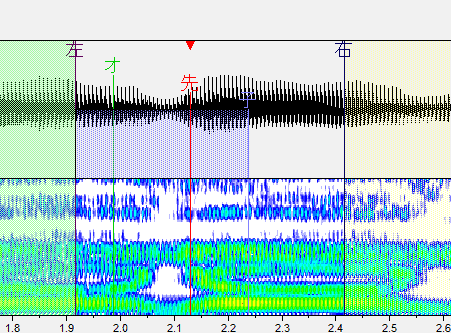
・左ブランク:「左」と書かれた線です。音が始まるところ。これより前の部分は再生されません。
・オーバーラップ:「オ」と書かれた緑の線です。前の音と重なるところ。この部分が前の音と合成されます。連続音だとアルファベットで表記される部分がこれになります。
・先行発声:「先」と書かれた赤い線です。発声の始まるタイミングです。これがズレるとリズム音痴になってしまいます。基本的には子音と母音の間に設定します。
・固定範囲:「子」と書かれた線です。子音と母音が完全に分かれるまでの範囲です。音を伸ばした時に、この範囲の音は引き延ばされません。(ここが引き延ばされると ねっとりした発音になります。)
・右ブランク:「右」と書かれた線です。音が終わるところ。これより後ろの部分は再生されません。出来る限り広い方が良いですが、ギリギリすぎると次の音が入ったりしてしまうのである程度内側に設定しましょう。
連続音を設定するにあたって、最初の音(「-」の音)以外は基本的に「左ブランク」と「オーバーラップ」を動かしてはいけません。(先行発声を動かしたときに一緒に移動するのは大丈夫。)
SetParamでよく使う操作
・Ctrl+スペースキー:選択範囲を再生します。
・矢印キーの上下:前の音/次の音に移ります。
・マウス:線をドラッグして動かすことで設定を行います。
この時点である程度しっかり設定されているのですが、一部ずれてしまっている部分があるのでそこを修正していきます。
多少のズレは問題ないので、
「次の音の子音が入ってしまっていないか」
「最初の音の子音が切れてしまっていないか」
「先行発声(赤い線)がズレすぎていないか」
「表記と音声にズレがないか」
辺りを確かめていきましょう。
基本的には先行発声を動かして全体を動かせばいいのですが、「次の音の子音が入ってしまっている」場合は右ブランク、「最初の音の子音が切れている」場合は左ブランクを動かしてください。
以下に 行ごとに大体どのあたりに設定すると良いかを並べるので、確認しながら修正をかけてください。
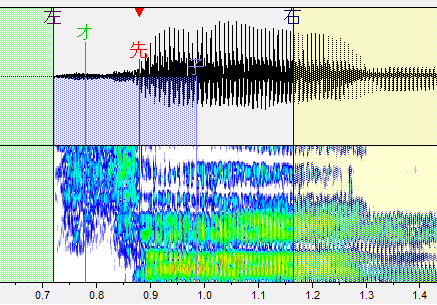
あ行の最初の音
発声直後くらいに設定します。端よりも気持ち内側くらいに先行発声を置きましょう。
あ行の2番目以降の音
前の母音と音が違う場合(「a あ」などではない場合)はスペクトル(下の青と緑の方)に変化がある部分があるので、その変化部分の気持ち内側に先行発声を置くと良いです。
前の母音と音が同じ場合は変化がほぼないので[Ctrl+スペースキー]で聴きながら先行発声の位置を決めましょう。大体で大丈夫です。
最初の行にして一番設定しづらい行なので頑張りましょう。
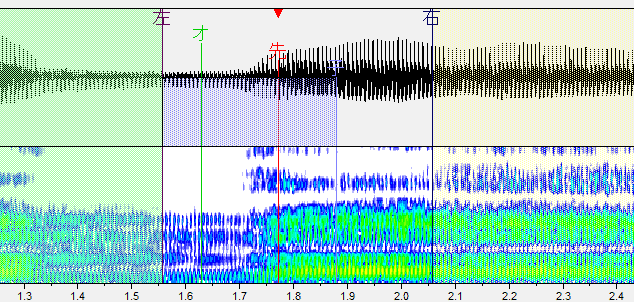



か行
子音と母音の間に先行発声を置きます。波形(上の黒い方)で見るとわかりやすいです。


が行
子音と母音の間に先行発声を置きます。気持ち内側くらい。

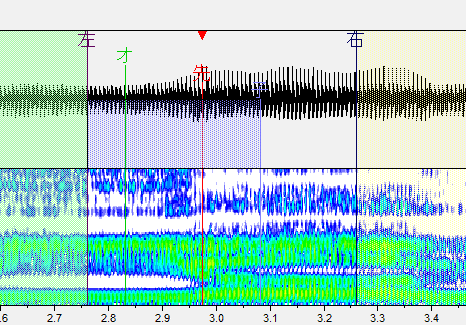
さ行
子音と母音の間に先行発声を置きます。
自動推定で次の子音が入りやすいので右ブランクもしっかり確認しましょう。

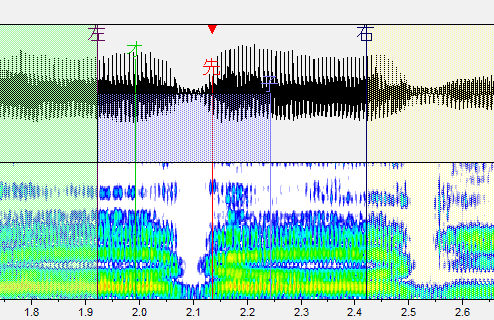
ざ行
子音と母音の間に先行発声を置きます。気持ち内側に置くと良いです。
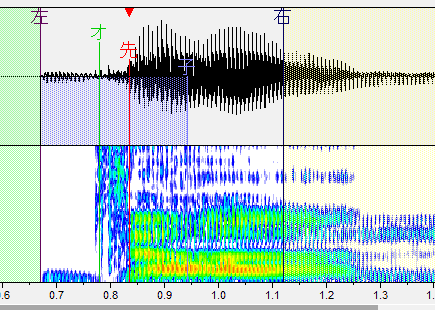
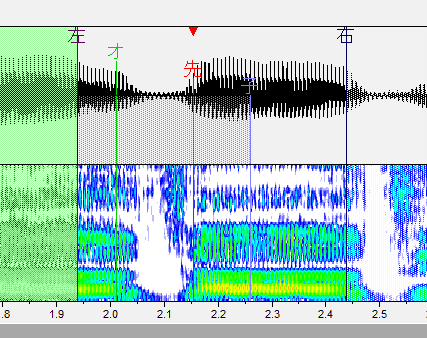
た行
子音と母音の間に先行発声を配置します。「ち」(ch)も同じように設定します。

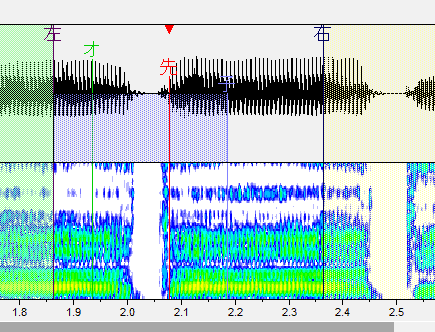

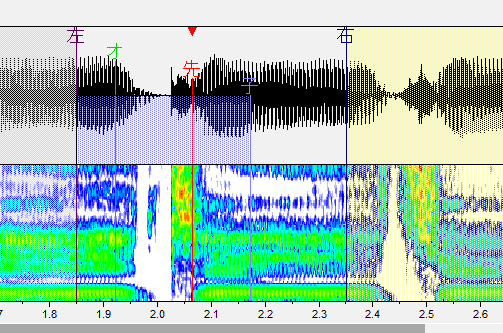
だ行
子音と母音の間に先行発声を配置します。気持ち内側に。
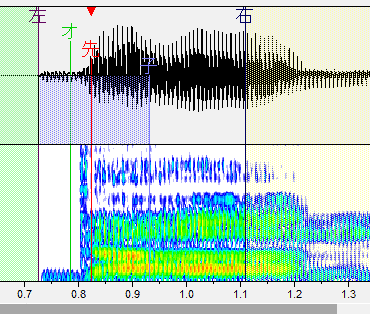

な行
スペクトルが変化し始める部分に先行発声を置きます。
最初の音以外は波形の変化でもわかりやすいかも。

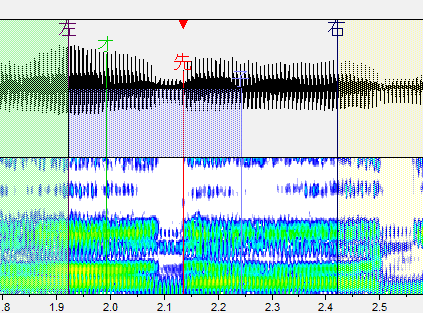
は行
スペクトルの変化箇所に先行発声を置きます。
子音の母音の境目がわかりやすい場合はそっちでも判断できます。


ば行
子音と母音の間に先行発声を置きます。

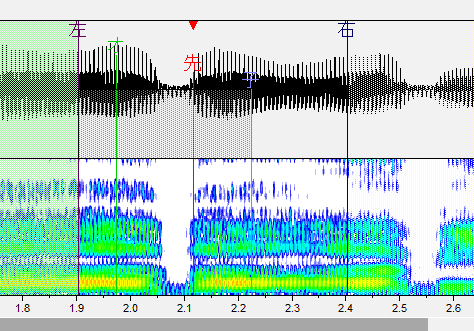
ぱ行
子音と母音の間に先行発声を置きます。
子音が小さいのでスペクトルで判断すると良いです。
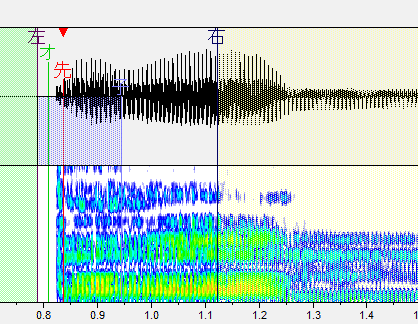
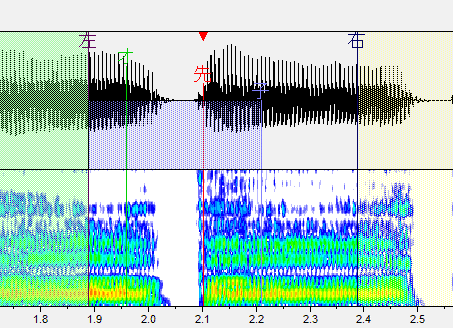
ま行
スペクトルの変化箇所に先行発声を置きます。
子音の母音の境目がわかりやすい場合はそっちでも判断できます。


や行
スペクトルで変化が大きい部分の気持ち内側くらいに先行発声を置きます。
子音と母音が完全に分かれるまでの範囲が長く、発音がねっとりとしやすいので固定範囲は気持ち広めに設定すると良いです。
「あ行」くらい設定しづらい部分があるので注意しましょう。

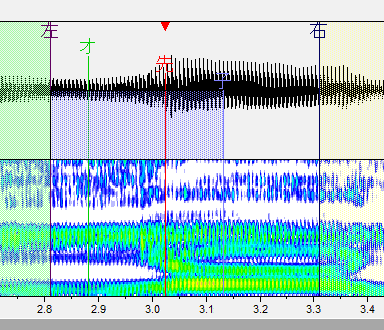
ら行
スペクトルの変化箇所に先行発声を置きます。
子音の母音の境目がわかりやすい場合はそっちでも判断できます。
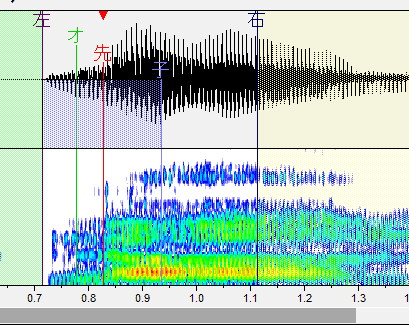

わ行
スペクトルの変化箇所に先行発声を置きます。気持ち内側に置くと良いです。
子音の母音の境目がわかりやすい場合はそっちでも判断できます。
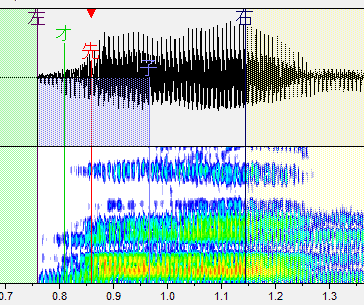

- ん
発声直後くらいに設定します。端よりも気持ち内側くらいに先行発声を置きましょう。
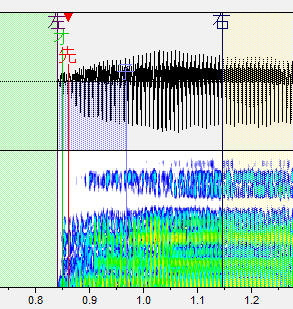
n ん
変化がほぼないので[Ctrl+スペースキー]で聴きながら先行発声の位置を決めましょう。大体で大丈夫です。

大体設定出来たら、後は音源を使いながら気になるところを修正すると良いです。
そのため、ここまで来たら原音設定は一旦終わりとします。
上書き保存をしてSetParamを閉じます。
3:周波数表生成
SpeedWagonというソフトを使用するのが一番楽だと思います。
ダウンロードと解凍をしておいてください。
Speedwagon_DandD.exeを開きます。

すると、白い小さな画面が表示されるので、ここに原音をすべて選択してドラッグ&ドロップしてください。

すると、コマンドプロンプト(黒い画面)が表示されるのでしばらく待ちます。
「続行するには何かキーを押してください…」と表示されたら終了です。
エンターキーなどを押せばコマンドプロンプトが終了されます。

フォルダの中に原音と同じような名前のファイル(.frq)がたくさん生成されていれば成功です。

これでUTAU音源自体は完成です。
お疲れさまでした!
4:見た目の設定
UTAU音源が完成したとはいえ、このまま使うと 歌ってくれはするけどアイコンも何も表示されない状態になってしまいます。

アイコンとか説明書きとか欲しくないですか!
ということで説明をします。
まず、アイコン画像を用意します。
100×100の.bmpファイルにしてください
次に、「character」という名前のテキストファイルを用意します。
中身はこんな感じで書きます。

name=キャラの名前
author=声を当てた人
image=〇〇.bmp(アイコンのファイル)
web=(サイトのURL/あればで良いです)
version:ver1.0(更新したらここを変えていくと良いです)
sample=〇〇.wav(サンプルにしたいファイル名を設定します。何も書かない場合原音がランダムで選ばれます。)
名前を付けて保存で、文字コードを「ANSI」にしてください。(そうしないと文字化けしてしまいます。)

最後に「readme」という名前のテキストファイルを用意します
中身は何を書いてもいいです。音源の説明欄に表示されます。
こちらも、名前を付けて保存で、文字コードを「ANSI」にしてください。(そうしないと文字化けしてしまいます。)
これで、UTAUで使用した時にアイコンや説明が表示されるようになります!
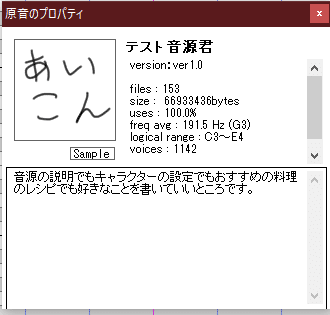
以上!
宣伝:筆者の音源
「天底音ネイ」という音源を配布しています。
沢山表情音源があるので良ければお迎えしてみてね!
これ以降はおまけパートです。
おまけ1:UTAU音源を使いながら原音設定を修正する
UTAUで使っている間って、原音設定を修正しても反映してくれないんですよね。音源を再読み込みしないといけないけどちょっと面倒…なので、ショートカットキーでできるようにしてしまいましょう!
utaukeというプラグインを導入します。

UTAUの「plugins」フォルダに解凍して入れてください。

UTAUを起動して、「ツール」の「プラグイン」の中の「utauke」を起動します。
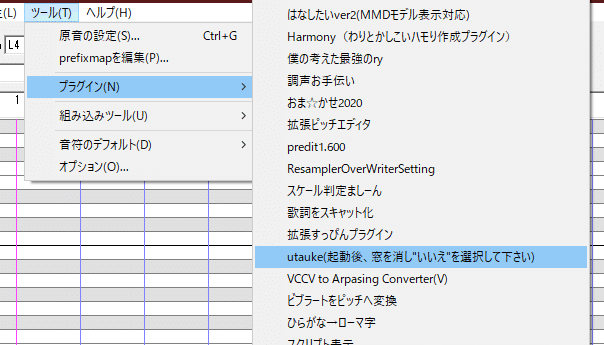
起動したら書いてある通り×で窓を消して「いいえ」を押してください

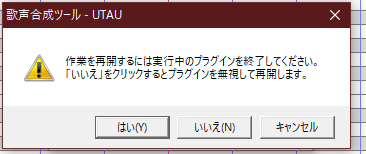
これでutaukeが起動しました。
タスクバーにutaukeがあれば成功です。

この状態で[Ctrl+Alt+G]を押すと原音設定がリロードされるようになります。

なので、SetParamを起動しながらUTAUを使用し、原音設定がおかしい感じのする部分があったらSetParamで修正、UTAU上で[Ctrl+Alt+G]で原音設定がリロードされて修正した原音設定が反映されるようになります。
便利!
おまけ2:多音階音源を作ろう!
Q.多音階音源って何?
A.たくさんの音階を収録することで、収録した音階から離れて音が劣化してしまうのを抑制した音源。
UTAU音源は物量が正義だと思います(諸説あり)
まず、別々の音階で音源を収録します。
フォルダは音階ごとに分けましょう。

次に、原音設定を済ませます。
原音設定が終わったら、「ツール」の「エイリアス一括変更」を開きます。

規則変換の部分に「%m%s〇〇」と入力します。
〇〇の部分は収録した音階を書いてください。
入力したら「全wavに対して実行」を行ってください。

そうすると、音名の後に音階名が付きます。
この状態で上書き保存してください。
これを収録したすべての音階でやります。
フォルダ構成をこのようにします。
この階層(フォルダだけで原音ファイル自体はない階層)にもoto.iniがないと音源が読み込まれなくなってしまうので、どこかからoto.iniをコピーしてきましょう。中には何も書かれている必要が無いのでメモ帳などで開いて消してしまいましょう。
逆に言うと何を書いても良いので小ネタを仕込んでおくのもまた一興。

UTAUで音源を読み込み、「ツール」の「prefixmapを編集」を開きます。

この画面で、「どこからどこまでの音階はどの原音を使う」という設定をします。
右のリストの音階をshiftキーを押しながら複数選択して、「後(Suffix)」に設定したい音階(収録したもの)を書いて「セット」を押します。
尚、UTAUの処理において音を上げるより音を下げる方が音の劣化が激しいので、上下を均一に設定するより上の方が多くなるように設定した方が良いです。
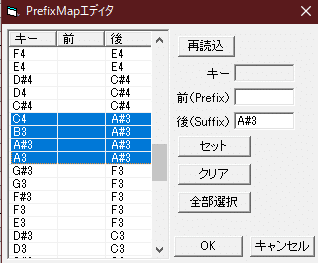

一番下から一番上までしっかり設定しましょう。

あとは「OK」を押せば音源の多音階化は終わりです。
音源のフォルダの中にprefix.mapというファイルが追加されていたら成功です。
さいごに
とりあえずで連続音を作ってみよう!という記事だったので細かい部分は本当に省いています。ノイズ処理や原音設定の細かい処理だったりは慣れてなんとなく わかってきてから調べてみると とっつきやすいと思うよ!というスタンスです。
創作って楽しいですよね。良いUTAUライフを!
わからない所や質問、追記してほしいことなどがあればコメントの方にお願いします。