
機械学習を勉強してアニメのレコメンドシステムを作ってみた

1. はじめに
はじめまして。
この記事は、プログラミング初心者が、Pythonを使った機械学習を学んだアウトプットの一環として投稿するものになります。至らぬ点があるかと思いますが、暖かくご指摘・コメントいただければ幸いです。
2. きっかけ
高校生くらいの時に独学でウェブサイトを作ろうとして挫折したことがきっかけで、プログラミングに苦手意識を持っていました。
今はデザイナーをしているのですが、エンジニアさんと協働する上で、私に少しでもプログラミングの知識があればもっとコミュニケーションがしやすいのでは?と感じたことがきっかけで、3ヶ月間Pythonを使った機械学習を学んでみました。
環境
Python3
Macbook Air
Chrome
Google Colaboratory
3. 今回やってみたこと
今回はKaggleというサービスにあるデータとK近傍法という機械学習の分類手法を使い、特定のアニメタイトルを入力すると、そのアニメに近しいタイトルを10タイトル返してくれるレコメンド機能を作ってみます。
今回使用したデータ
Anime Recommendations Database
約73000人のユーザーが10点満点で評価した、約12000タイトルの
アニメ(アニメーション映画含む)スコアのデータです。
1️⃣ データの中身を見てみる
まずは上記のURLからデータをcsv形式でダウンロードします。

anime.csvというファイルとrating.csvというファイルがダウンロードされました!
Google Colaboratory上でどのようなデータなのか詳しく見てみます。
import pandas as pd
import numpy as np
df_anime = pd.read_csv('/anime.csv')
print(df_anime)
df_anime.head()
anime.csvは7つのカラム × 12294つのアニメから構成されているデータのようです。
anime_id ... 各アニメに付随する固有番号
name ... アニメタイトル
genre ... アニメのジャンル
type ... アニメーション映画も含まれるため、TVもしくはmovieに分かれる
episodes ... アニメの話数
rating ... 10点満点でつけたスコアの平均
members ... 採点したユーザー数
rating.csvのデータを見てみます。
df_rating = pd.read_csv('/rating.csv')
print(df_rating)
df_rating.head()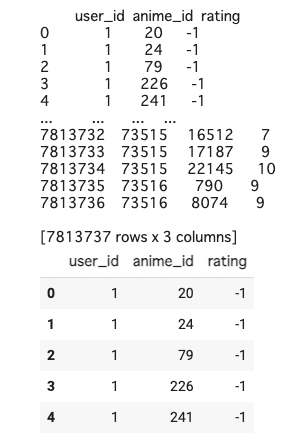
rating.csvは3つのカラムで構成されています。ただ、各ユーザーに対して回答していないデータも含まれているので780万行近くの凄まじい量があることが分かりました。
user_id ... 各ユーザーに付随する固有番号
anime_id ... 各アニメに付随する固有番号
rating ... ユーザーがつけた1から10のスコア ※ -1は未回答
2️⃣ 学習に使うデータを残して成形する
各ファイルに含まれる要素が分かったので、2つのファイルをマージさせた後に、今回の機械学習に用いるデータ以外を削除してデータを今よりも軽くなるように成形します。
まずは二つのファイルをanime_idをkeyにマージします。各ファイルにratingカラムが重複しているので、個別のユーザーがつけた方のスコアをrating_individualに、スコアの平均値をrating_meanに改名します。
# anime_idをkeyにマージする
df_merge = df_rating.merge(df_anime, left_on='anime_id', right_on='anime_id', suffixes=['_individual', '_mean'])
print(df_merge)
df_merge.head()
このようになりました!
今回は類似するアニメを10個返してくれるレコメンド機能を作るので、アニメーション映画を含むと10個中何個も同じシリーズもので埋め尽くされる可能性があります。(エヴァで検索したら劇場版エヴァばっかり出てくるみたいな)
そこで、typeカラムを使ってTVと記載のあるもののみ使用します。
# typeがTVのもののみ残す
df_merge = df_merge[df_merge['type'] == 'TV']
print(df_merge)
行が減っているので無事に削除できたようです。
次に、評価数が3000に満たないアニメ(マイナーなアニメ)をレコメンド対象から外します。
# 評価数が3000以上あるもののみ残す
df_merge = df_merge[df_merge['members'] >= 3000]最後に、今回使うuser_id、anime_id、name、rating_individualのデータを残し、それ以外のカラムを削除します。
ついでに、同じユーザーが重複してスコアをつけたものがあるかもしれないので、user_idとnameを使って省いておきます。
# 使用するカラムのみ残す
df_merge = df_merge[['user_id', 'anime_id', 'name', 'rating_individual']]
# 評価の重複を省く
df_merge = df_merge.drop_duplicates(['user_id', 'name'])
df_merge.head()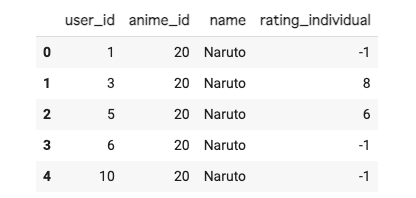
これで学習に用いるデータを用意できました。
3️⃣ K近傍法で学習モデルをつくる
いよいよ学習モデルをつくっていきます。今回はK近傍法で、brute(力任せ検索)とcosine(コサイン類似度)を使います。
K近傍法とは
K近傍法とは、機械学習の分類に使われる手法の一つで、与えられた学習データをベクトル空間上にプロットして、そこから距離が近い順に任意の数を取得し、その多数決でデータが属するクラスを推定するというものです。
詳しくはWikipedia先生を参照ください。
# モジュール読み込み
from sklearn.neighbors import NearestNeighbors
knn = NearestNeighbors(algorithm='brute', metric='cosine')
# 処理済みのデータを読み込み
model_knn = knn.fit(df_merge)用意したデータを読み込んで学習させようとすると以下のようなエラーが出てきました。
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-7-f264c6ead7e4> in <module>()
9
10 # 処理済みのデータを読み込み
---> 11 model_knn = knn.fit(df_merge)
12
5 frames
/usr/local/lib/python3.7/dist-packages/numpy/core/_asarray.py in asarray(a, dtype, order)
81
82 """
---> 83 return array(a, dtype, copy=False, order=order)
84
85
ValueError: could not convert string to float: 'Naruto'nameカラムが各アニメタイトル(Narutoのような)になっているため、文字列を扱っているstring型から、浮動小数点数を扱うfloat型に変換できませんと言われてしまっています。
そこで、学習させるデータの各行をnameに、各列をuser_idに変えてデータの中身がスコアのみになるよう変形し直してみます。また、変形するとほとんどのデータがNAになってしまうので(各ユーザーに対して、評価していないアニメがたくさんあるため)、NAを-1に置き換える処理も付け加えます。
NAを0ではなく-1に置き換えている理由
扱っているデータは各ユーザーが0から10のスコアでアニメを評価しているものになります。そのため、NAを0に置き換えると、ユーザーがそのアニメに対して0点のスコアをつけたことと同義になります。今回はユーザーが評価したスコアを元にアニメ同士の距離の近さを算出して学習をさせるため、NAの評価されていないアニメは、10点のスコアをつけたアニメから1番距離が遠くなるように、-1に置き換える処理にしています。
# 行をname、列をuser_idに変形
df_merge_pivot = df_merge.pivot(index='name', columns='user_id', values='rating_individual').fillna(-1)
df_merge_pivot.head()
変形できたので、もう一度学習させてみます。
# モジュール読み込み
from sklearn.neighbors import NearestNeighbors
knn = NearestNeighbors(algorithm='brute', metric='cosine')
# 処理済みのデータを読み込み
model_knn = knn.fit(df_merge_pivot)エラーは出ず、うまく学習できたようです。
次はdef文を使って、特定のアニメタイトルを入れたらそのアニメに近しいタイトルを10タイトル返してくれる関数を記述していきます。
# ユーザー評価が似ているアニメを取得
def similar_rating_animes(anime_name, num=100, verbose=False):
# 指定したアニメタイトルの評価を取り出してusers_ratingに代入
users_rating = df_merge_pivot.iloc[df_merge_pivot.index == anime_name].values.reshape(1, -1)
# 学習結果から指定したアニメとコサイン類似度が近いアニメを取得する
distance, index = model_knn.kneighbors(users_rating, n_neighbors=num+1)
df_result = df_merge_pivot.iloc[index.flatten()]
df_result['distance'] = distance.flatten()
df_result['name'] = df_result.index.map(lambda x: df_anime.loc[df_anime['name'] == x, 'name'].values[0])
# 入力されたアニメと同じタイトルのものを結果に反映しない
df_result = df_result.drop(anime_name)
if verbose:
print('【{0}】 とユーザー評価が似ているアニメ'.format(anime_name))
for idx, res in df_result.iterrows():
print('\t{0}'.format(res['name']))
return df_result
result = similar_rating_animes('ここにアニメタイトルを入れる', num=10, verbose=True)上記でsimilar_rating_animesという関数を作りました。引数にアニメタイトルを入力して実行すれば結果が表示されるはずです!試してみましょう。
4️⃣ 結果から精度をみてみる
まずは私の大好きなアニメ「ハイキュー!!」を入れてみます。
result = similar_rating_animes('Haikyuu!!', num=10, verbose=True)※ 今回はanime_csvファイルにあるタイトルと完全に一致するものを抽出する都合上、データが配布されていたKaggleのページからnameカラムを参照して、探したいアニメタイトルの英語表記を入力しています。

ハイキュー!!の二期アニメが一番上に出てきました。他にも黒子のバスケやFree!、弱虫ペダルなどスポーツを題材にしたアニメかつ女性人気も高そうなタイトルが並んでいるので、精度は悪くないのではないでしょうか。
次にジャンルの違うアニメも入力してみます。
少女漫画が原作の「アオハライド」というタイトルを入力してみましょう。
result = similar_rating_animes('Ao Haru Ride', num=10, verbose=True)
アオハライドと同じ別冊マーガレットで連載されていた漫画が原作のオオカミ少女と黒王子が一番上に出てきましたね。好きっていいなよ。、月刊少女野崎くん、となりの怪物くんなどなど実写化もされた人気の高い少女漫画が原作のアニメが並んでいます。
最後に、みんな大好き「ドラゴンボール」の類似アニメを検索してみましょう。
result = similar_rating_animes('Dragon Ball', num=10, verbose=True)
デジモンアドベンチャーやポケモン、鋼の錬金術師など老若男女に愛される名作アニメが出てきていることからこちらも精度としては悪くなさそうです。
4. 考察
結果を見てみると概ね悪くなさそうですが、ドラゴンボールZ、ドラゴンボールGT、ドラゴンボール改などのドラゴンボール関連作品も多く入ってきてしまいました。
ハイキュー!!の結果にもありましたが、同タイトルの二期や別シリーズのアニメはタイトルが1文字でも違えば別作品として結果に表示されてしまうので、類似アニメを検索するという目的から見ればノイズになってしまうかもしれません。
アニメタイトルの最初から指定した文字数分だけ一致したものを同じタイトルとして扱うように処理を付け加えたり、文の類似度を計算する関数を使って同じシリーズを見つけ出すといったような処理で、ノイズを軽減できるかもしれません。改善の余地ありですね!
5. さいごに
いかがでしたか?
今回はKaggleのAnime Recommendations Databaseを使って機械学習を行いってみました。
イメージ通り動くものを作れたことは、機械学習を勉強し続けるモチベーションにもなりますし、何より楽しいですね!
面白いデータが転がっているKaggleや環境構築が不要ですぐに実装を始められるGoogle Colaboratoryなどの便利なサービスは私のような機械学習初学者の強い味方でした...!
今回は配布されていたanime_csvファイルとanime_ratingファイルの中からユーザーがつけたスコアデータを使用しましたが、anime_csvファイルの中には各アニメに対してgenreというアニメのジャンルが入っているカラムもあります。
そちらも使うと、より精度高くレコメンドできるシステムになりそうです。また時間を見つけて挑戦してみたいと思います!
最後までお付き合いいただき、ありがとうございました!
機械学習やプログラミングをはじめたての方の参考になれば嬉しいです!