エンべディングとは?ファインチューニングとの違いやメリット・デメリットを解説

みなさん、ChatGPTを業務に活用する際に欠かせない技術「エンベディング」をご存知ですか?
弊社・株式会社WEELでは過去に、エンベディングとChatGPTの組み合わせで業務の工数を90%削減した開発事例があります。
また人気バーチャルタレントの分身を作る企画にも、このエンベディングが使われていて……
【💡技術ブログ「COVER Tech」更新情報💡】
— カバー株式会社 (@cover_corp) November 22, 2023
「AIこより爆誕!?の裏側」を公開💻
今回はAIこよりシステムの開発に関わったエンジニアより、開発の経緯や開発したシステムについて寄稿いただきました‼️
ご興味がある方は下記リンクよりご覧ください。https://t.co/GIxE085tkG#COVERTech #COVERnote pic.twitter.com/L27cj2Cez6
このように、今ホットな技術なんです。
当記事では、そんなエンベディングの生成AI分野での活躍ぶりを紹介!そのしくみやメリット・デメリット、開発事例までをお伝えしていきます。
完読いただくと、ChatGPTで自動化できる業務の幅が広がるはずです。
ぜひ最後までお読みください!
エンベディングとは?
「エンベディング / Embedding」とは、ベクトル空間上にデータを配置する技術です。
と、説明されてもその実態が掴みづらいですよね。そこでベクトル空間を「図書館の本棚」、各データを「書籍」に例えて考えてみましょう。
まずベクトル空間の特性として……
● 似た者同士のデータでは距離が小さい
● 互いに無関係なデータでは距離が大きい
というものが挙げられます。これを図書館の本棚で言い表すと、ジャンルごとに本棚が分けられている状態となります。そこに各データ、すなわち書籍を入れていくわけですが……
昆虫図鑑と魚図鑑
純文学とプログラミングの技術書
であれば前者、生き物の図鑑同士のほうを近くに置きたいですよね。その方が書籍を探しやすくなるはずです!
このようにして、検索性を損ねずに膨大なデータを格納する技術こそがエンベディングなのです。
ちなみにエンベディングは和訳すると「埋め込み」になります。ベクトル空間上にデータを埋め込むという言い回しです。
エンベディングの身近な活用例
エンベディングは、あらゆる検索エンジンの基礎となる技術です。入力内容に対して、ベクトル空間上で似ているデータを探して出力する、というのが検索エンジンの本質です。身近な例を3つ挙げると……
Googleのテキスト&画像検索
Netflixのレコメンデーションシステム
AIチャットボット
はすべて、エンベディングの上に成り立っています。
そう、みなさんがこの記事にたどり着いたのも、エンベディングのおかげなのです!
参考記事:AI のマルチツールのご紹介: ベクトル エンベディング | Google Cloud 公式ブログ
なお、エンベディングが使えるPythonライブラリ・Llamaindexについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→Llamaindexを使った開発とは?流れ、費用相場、開発事例を紹介
エンベディングが生成AI分野で使われる理由
先ほど紹介したとおり、エンベディングはAIチャットボットに欠かせない技術です。ここではなぜ、エンベディングと生成AIを組み合わせるのか、その理由を解説します。
まずは生成AI側の致命的な欠点からみていきましょう!
大規模言語モデル(LLM)の限界
そもそもAIチャットボットには、ChatGPTなどの大規模言語モデル(LLM)が使われています。このLLMは人間さながらの文章が生成できるのですが……
● ハルシネーション(事実とは異なる回答)が生じてしまう
● 自社データや専門知識など、ニッチな事実を知らない
● プロンプト(入力文)で示せる事実には限りがある
といった、致命的な欠点を抱えています。チャットボットとして運用する場合、なにか「必要な事実だけをプロンプトに添えてくれる技術」を組み合わせないと使い物になりません。
LLMの欠点を補うエンベディング
この「必要な事実だけをプロンプトに添えてくれる技術」こそがエンベディングです。LLMとエンベディングを組み合わせたAIチャットボットでは……
AIチャットボットのしくみ
ユーザーが質問する
質問に関連する事実をデータベースから検索する(RAG)
関連性の高い事実だけを質問に加筆する(Few-shot Learning)
事実に基づいた回答が生成される
というふうにして、回答の信ぴょう性を高めています。
実はこのエンベディング以外にも、生成AIに事実を学ばせる方法として「ファインチューニング / 追加学習」というものがあります。次の見出しで、両者の違いを比較していきましょう!
参考記事:検索により強化された生成 (RAG) | Prompt Engineering Guide
エンベディングとファインチューニングの違い
エンベディングもファインチューニングも、生成AIに事実を教えるための手法です。ただ、両者では……
【エンベディング】
データベースを生成AIに外付けする技術
【ファインチューニング】
データベースを生成AIのモデルそのものに取り込ませる技術
となっており、生成AIに対するアプローチが違います。結果として、下表のような具体的な違いがあらわれます。
エンベディング
学ばせる内容:自社データや専門知識など、ニッチな事実
変えられるもの:回答の精度・信ぴょう性
開発費用:比較的安価
用途:AIチャットボット / カスタマーサポート
ファインチューニング
学ばせる内容:業界に関する一般知識
変えられるもの:回答の口調や概念への理解度
開発費用:比較的高価(エンベディングの8倍程度)
用途:デジタルクローン / クリエイターの絵柄を再現する画像生成AI
両者のうち、高い精度が実現できて手軽なのはエンベディングのほうです。対してファインチューニングは、業務上の用途に向きません。
エンベディングを使うメリット3つ
ここではエンベディングと生成AIの組み合わせがもたらす、社内業務上のメリットを3つ紹介していきます!
社内データを回答に反映できる
エンベディングを使えば、本来LLMが知り得ないような事実まで回答に反映させられます。たとえば……
契約書
議事録
カタログ
マニュアル
機材の取扱説明書
といった社内データを扱う、AIツール・チャットボットが開発できるのです。これだけで、膨大な資料を人力で集める工程が省けますね。
回答の再現性が高められる
同じ命令を繰り返し入力した場合、素のLLMはその都度、回答をランダムに生成します。これでは再現性が低く、型が決まっている業務への応用が難しいですよね。
そこでエンベディングの出番です!エンベディングなら、LLMに社内文書や回答のテンプレートが示せます。さらに回答の参考元となったデータも表示できるのです。
ある程度ハルシネーションが抑えられる
LLMはしばしば、事実とは異なる回答つまり「ハルシネーション」を知ったかぶりで生成してしまいます。一般企業各社において、生成AIの導入がなかなか進まない理由はこのハルシネーションにあります。
この厄介なハルシネーションをある程度抑えてくれるのが、エンベディングです。社内データをプロンプト経由でLLMに示すことによって、その範囲内でなら正確な回答が生成されます。
なお、ハルシネーション等の生成AIのリスクについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→ChatGPTを企業利用するリスクと対策5選|実際の企業事例と共に解説
エンベディングを使うデメリット3つ
エンベディングと生成AIの組み合わせには、デメリットも存在します。
ここからは、業務活用時に限定して、エンベディングのデメリットを3つ紹介!まずは開発時のデメリットから、詳しくみていきましょう。
データ整形に手間がかかる
エンベディングを使って自社データをLLMに示す場合、データの品質が回答精度を左右します。そのため自社データの整形が必要なのです。
データの整形はExcelで完結するため、IT人材不在の一般企業でも取り組めます。ただ、その作業は以下のとおり煩雑です。
● 名寄せ:複数のデータを1つのファイルに統合する
● データクレンジング:データの表記を統一する
→重複の解消 / 空白の解消 / 全角半角の統一…etc.
● マニュアル作成:クレンジングのルールを定める
このようにエンベディングでは活用の前段階にて、時間的・経済的なコストがかかってしまうのです。
回答速度が低下する
エンベディングとLLMを組み合わせた場合、回答の速度が低下します。これは毎度プロンプトをLLMに送る前に、ネットワーク経由でデータベースを確認する工程が挟まるためです。物理的な問題であるため、これを解決する手段はありません。
チャットボットを社外に公開する際、回答速度については期待しないほうがよいでしょう。
ハルシネーションがなくなるわけではない
たとえエンベディングを駆使したとしても、ハルシネーションを完全になくすことはできません。
例を挙げると、ごみ出し案内業務にてChatGPTの活用を試みた香川県三豊市では……
● 目標の正答率99%にわずかに届かず、正答率が94%で止まってしまった
● わずかでもハルシネーションが混ざると、市民や収集業者に迷惑がかかる
● 結局のところ、職員が回答を確認することとなった
という理由から、ChatGPTの導入を見送っています。絶対に間違えてはいけない業務では、まだまだ生身の人間が必要なのです。
参考記事:ChatGPTでの業務効率化を“断念”──正答率94%でも「ごみ出し案内」をAIに託せなかったワケ 三豊市と松尾研の半年間(1/2 ページ) – ITmedia NEWS
エンベディングを活用した開発事例3選!
ここからは、エンベディングを活用した開発事例を3つだけ紹介します。まずは、どの企業でも取り入れやすい社内業務での活用事例から、みていきましょう!
社内ヘルプデスク業務の自動化
エンベディングとLLMを組み合わせれば、社内のヘルプデスク業務の負担が減らせます。当記事では、GMOのグループ研究開発部門の例をみていきましょう。
GMOでは、自社のVPSサービス「Conoha」のAPIについて答えてくれるQ&Aツールを試作しているのですが……
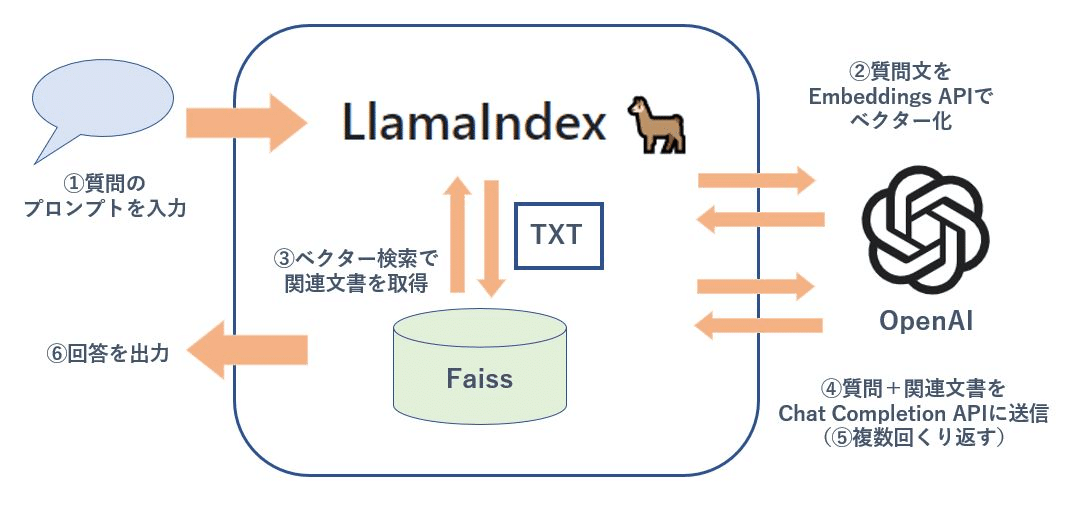
このように、エンベディング(Llamaindex)とChatGPTを駆使して、社内データを回答に反映させています。
参考記事:Llamaindex を用いた社内文書の ChatGPT QA ツールをチューニングする – GMOインターネットグループ グループ研究開発本部
社外向けのQ&Aツール
社外向けのカスタマーサポート業務でも、エンベディングとLLMが活躍します!
株式会社システムサーバーが開発した、LINEアプリ上で自社ブログの内容について質疑応答ができるチャットボットについて、しくみをみてみると……
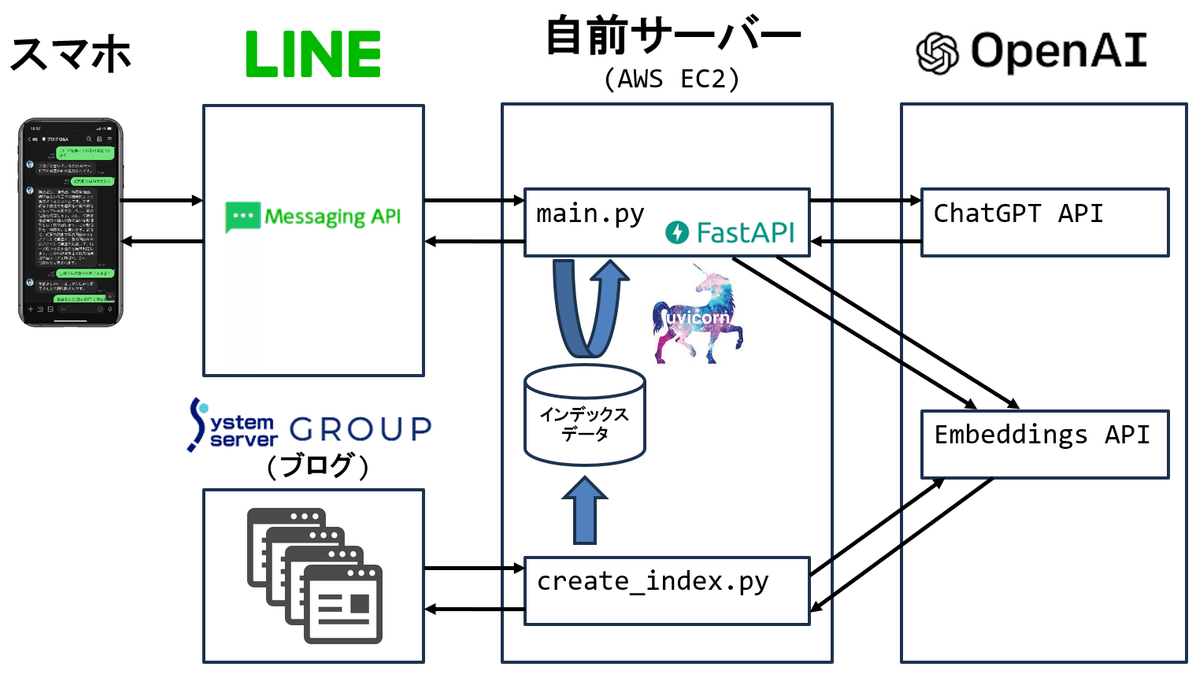
このように、自社ブログの内容をエンベディング(Llamaindex)でインデックスデータに格納しています。
参考記事:ChatGPT API と LlamaIndex でブログのQ&A Chatbotを作ってみた
バーチャルタレントのデジタルクローン
エンターテイメント業界でも、エンベディングとLLMが活躍しています。今回取り上げるのは、大手VTuber事務所を運営しているカバー株式会社の事例です。
同社に所属する登録者数100万人超えの人気VTuber・博衣こよりさんの企画で、自身のデジタルクローン『AIこより』と対話するというものがあるのですが……

このように『AIこより』の記憶システムにも、エンベディングが活用されているんです!エンベディングによって、過去のやり取りの記憶を実現しています。
参考記事:AIこより爆誕!?の裏側
エンベディング×生成AIで業務を効率化しよう!
当記事では、生成AIの弱点を補ってくれる技術「エンベディング」について紹介しました。以下でもう一度、エンベディングの特徴を振り返っていきましょう!
【エンベディングの基本】
● 類似度を使って、データをベクトル空間に格納する
● エンベディングしたデータは検索性に優れている
【生成AI分野でのエンベディング】
● LLMに外付けする形で、AIツールやチャットボットを構成する
● LLMが知り得ない事実を補ってくれる
● 質問に関連する事実だけをLLMに示す
このような強みをもつエンベディングはしばしば、業務用のAIツールやチャットボットに組み込まれています。