
【院生が徹底解説】ChatGPTのベクトルデータベースとSQLの比較

今回は、このPineconeというベクトルデータベースに焦点を当てて、概念やPythonによる実装方法を解説します。
さらに、ベクトルデータベースであるPineconeと、リレーショナルデータベースのSQLを比較していますので、ぜひ参考にしてください。
Pineconeとは?
Pineconeを使い始める前に、概要について解説します。
Pineconeは、数十億ものデータを扱うことができ、高速なクエリ処理を実現するベクトルデータベースです。シンプルなAPIを備えているため、使いやすさが特徴です。
Pineconeのキーコンセプトは以下の通りです。
ベクトル検索
類似ベクトルの高速検索
ベクトル埋め込み
ベクトルの意味的類似性を表した情報
ベクトルデータベース
効率的なデータ管理と検索のための、ベクトル化と保存を実現するデータベース
まず、Pineconeの公式ページに移動しましょう。そして、「Sign Up for Free」をクリックして登録します。

Pineconeを利用するためにはAPIキーが必要なので、
登録が完了したら、左サイドバーから「API Keys」へと進んでください。

すると、以下のように「Environment」と「Value(API Key)」があります。2つともひかえておきましょう。

PineconeのHybrid Searchとは?
Pineconeでは、基本的なキーワード検索に加えて、セマンティック検索を行うことができます。セマンティック検索とは、文字よりもその意味を解釈して検索する機能です。
この「基本的なキーワード検索」と「セマンティック検索」を組み合わせたのが「Hybrid Search」です。
文の意味の類似性を測るために、以下のような手法が用いられます。
TF-IDF
BM25
word2vec/doc2vec
BERT
USE
より詳細な内容は、Pineconeの公式ページに記事があるので、気になる方はぜひ読んでみてください。
これ以降では、PineconeのHybrid Searchを使っていこうと思います。
Pineconeを使ってみた
早速Pineconeを、以下の順で試してみます。
Pineconeのインストールやインデックス作成
簡単なクエリ処理
Hybrid Searchでクエリ処理
公式ページにGoogle Colaboratoryが用意されているので、基本的には、その通りに実行していけば試すことができます。
クイックスタート
ここでは、Pineconeのインストールや、簡単なクエリ処理の実装から始めてみましょう。
まずは必要なパッケージのインストールです。
# パッケージのインストール
!pip install pinecone-client以下のような画面が出れば、インストール完了です。

次にPineconeの初期化を行います。先ほど取得した「Environment」と「Value(API Key)」を入力しましょう。
import pinecone
# Pineconeの初期化
pinecone.init(
api_key="<Pinecone_APIキー>",
environment="<Pinecone Environment>"
)次に、インデックスを作成します。ここで設定できる引数の詳細は、以下の通りです。
dimension
ベクトルの次元
整数を入力
metric
類似度の指標
euclidean: ユークリッド距離
cosine: コサイン類似度
dotproduct: ドット積
pod_type
コストタイプ
s1: 低コスト
p1: 適度なコスト
p2: 高コスト
また、一番上にインデックスの名前を付けましょう。ここでは「quickstart」と名付けています。
# インデックスの生成
pinecone.create_index(
"quickstart",
dimension=8,
metric="euclidean",
pod_type="p1"
)無料版ではインデックスは1つしか作れません。
ちなみに、以下のコードを実行すれば、作ったインデックス名を全て参照できます。
# インデックスのリストを取得取得
pinecone.list_indexes()また、Pineconeのマイページでも、インデックスが作成されたことを確認できます。

次に、クエリ処理をするために、作ったインデックスに接続します。
# インデックスに接続
index = pinecone.Index("quickstart")次に、データベースにデータを挿入していきます。ここでは「A」~「E」までが各データの名前で、[0.1, ~ , 0.1]などは、8次元のベクトルを表します。
# データの挿入
index.upsert([
("A", [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]),
("B", [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]),
("C", [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]),
("D", [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]),
("E", [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5])
])ちなみに、このベクトルの部分は、本来自分で入力するのではなく、深層学習技術などを用いて、生データから変換したベクトルを入力してください。
例えば、単語のデータベースを作りたい場合、Word2Vecなどで単語をベクトル化します。3次元のベクトルにする場合、以下のように入力することになるでしょう。
# データの挿入
index.upsert([
("りんご", [0.3, 0.1, 0.2]),
("ごりら", [1.2, 1.2, 1.2]),
("ラッパ", [0.3, 3.3, 2.3]),
("パセリ", [1.4, 0.8, 0.4]),
("リング", [5.5, 10.5, 3.5])
])この場合、単語とベクトルのセットになります。
インデックスの統計情報を参照したい場合は、以下のコードを実行してください。
# インデックスの統計の取得
index.describe_index_stats()以下のように表示されるはずです。

そして、いよいよクエリ検索です。適当なベクトルを入力して、データベースに対して検索をかけてみます。
下記のコードの「vector」の部分が、検索にかけるベクトルです。このベクトルに近い「データベース内のベクトル」の情報を何個か表示してくれます。何個表示するかは「top_k」で決めます。
# 類似のベクトルの取得
index.query(
vector=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3],
top_k=3,
include_values=True
)以下のように返ってきました。

ここでは、ベクトル[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]に対して、ベクトルC, D, Bが返ってきました。
「score」はユークリッド距離を表します。「距離が小さい=似ている」なので、「scoreが小さい=似ている」です。そのため、ベクトルCはまったく同じデータであることが分かります。
また、ベクトルD, Bともある程度似ています。
最後に、インデックスを削除したい場合は、以下のコードを実行してください。また、「quickstart」のところには、消したいインデックスの名前を入れてください。
# インデックスの削除
pinecone.delete_index("quickstart")次の実装のために、削除しておきましょう。
ここまでの方法は、一般的な使い方でした。
次に、Hybrid Searchという方法で、クエリ処理をする方法を見ていきましょう。
Hybrid Searchでクエリ処理
ここでは、文章データをデータベースに格納し、文章に対するクエリ処理を行っていきます。
まずは、サンプルデータとして以下の10個の文章を用意します。
all_sentences = [
"purple is the best city in the forest",
"No way chimps go bananas for snacks!",
"it is not often you find soggy bananas on the street",
"green should have smelled more tranquil but somehow it just tasted rotten",
"joyce enjoyed eating pancakes with ketchup",
"throwing bananas on to the street is not art",
"as the asteroid hurtled toward earth becky was upset her dentist appointment had been canceled",
"I'm getting way too old. I don't even buy green bananas anymore.",
"to get your way you must not bombard the road with yellow fruit",
"Time flies like an arrow; fruit flies like a banana"
]次に、「Sentence Transformers」というライブラリをインストールします。このライブラリを使うことで、文章の意味を表す「意味ベクトル」に変換することができます。
# Sentence Transformersのインストール
!pip install sentence_transformersインストールできたら、先ほどのサンプルデータを、実際に「意味ベクトル」に変換します。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v3_mpnet-base')
all_embeddings = model.encode(all_sentences)
all_embeddings.shape最終行の「all_embeddings.shape」の出力結果から、all_sentencesは埋め込みが10、次元が768ということが分かりました。この情報は、後のインデックス作成時に、ベクトルの次元を決めるために使います。
続いて、HuggingFaceのライブラリ「transfo-xl-wt103」を用いて、サンプルデータ文をトークン化します。
まずは、以下のインストールを実行してください。
!pip install sacremoses
インストールが完了したら、一度ランタイムを再起動してください。その後、もう一度これまでのセルを実行してください。
次に、以下のコードを実行して、トークン化を行います。
from transformers import AutoTokenizer
# transfo-xl tokenizer uses word-level encodings
tokenizer = AutoTokenizer.from_pretrained('transfo-xl-wt103')
all_tokens = [tokenizer.tokenize(sentence.lower()) for sentence in all_sentences]
all_tokens[0]これを実行すると、サンプルデータの1文目の以下の文、
"purple is the best city in the forest"
が、次のように単語に区切られます。
['purple', 'is', 'the', 'best', 'city', 'in', 'the', 'forest']
これは「基本的なキーワード検索」に必要なので、このようにトークン化します。
ここまで来たら、次にインデックス作成です。
import pinecone
pinecone.init(api_key="<Pinecone_APIキー>", environment="<Pinecone Environment>")
pinecone.list_indexes() # check if keyword-search index already exists
pinecone.create_index(name='keyword-search', dimension=all_embeddings.shape[1])
index = pinecone.Index('keyword-search')次に、作成したIndexに対して、先ほど作成した以下の2つのデータを、DBに格納します。
all_embeddings
all_tokens
upserts = []
for i, (embedding, tokens) in enumerate(zip(all_embeddings, all_tokens)):
upserts.append((str(i), embedding.tolist(), {'tokens': tokens}))
# then we upsert
index.upsert(vectors=upserts)格納が完了したので、さっそくクエリ処理をしていきましょう。まずはセマンティック検索単体で試してみます。
以下の文章をクエリ文として引数に渡し、この文と「意味的に類似した文章」の上位5文を表示させます。
"there is an art to getting your way and throwing bananas on to the street is not it"
以下のコードを実行してください。
query_sentence = "there is an art to getting your way and throwing bananas on to the street is not it"
xq = model.encode([query_sentence]).tolist()
result = index.query(xq, top_k=5, includeMetadata=True)
result結果は以下の通り。意味的に似ている文が、高い順に5つ並んでいます。
{'matches': [{'id': '5',
'metadata': {'tokens': ['throwing',
'bananas',
'on',
'to',
'the',
'street',
'is',
'not',
'art']},
'score': 0.732851684,
'values': []},
{'id': '8',
'metadata': {'tokens': ['to',
'get',
'your',
'way',
'you',
'must',
'not',
'bombard',
'the',
'road',
'with',
'yellow',
'fruit']},
'score': 0.57442683,
'values': []},
{'id': '2',
'metadata': {'tokens': ['it',
'is',
'not',
'often',
'you',
'find',
'soggy',
'bananas',
'on',
'the',
'street']},
'score': 0.500876725,
'values': []},
{'id': '1',
'metadata': {'tokens': ['no',
'way',
'chimps',
'go',
'bananas',
'for',
'snacks',
'!']},
'score': 0.376693577,
'values': []},
{'id': '9',
'metadata': {'tokens': ['time',
'flies',
'like',
'an',
'arrow',
';',
'fruit',
'flies',
'like',
'a',
'banana']},
'score': 0.338697404,
'values': []}],
'namespace': ''}次に、キーワード検索も絡めた「Hybrid Search」を実行してみます。
all_embeddings
all_tokens
upserts = []
for i, (embedding, tokens) in enumerate(zip(all_embeddings, all_tokens)):
upserts.append((str(i), embedding.tolist(), {'tokens': tokens}))
# then we upsert
index.upsert(vectors=upserts)格納が完了したので、さっそくクエリ処理をしていきましょう。まずはセマンティック検索単体で試してみます。
以下の文章をクエリ文として引数に渡し、この文と「意味的に類似した文章」の上位5文を表示させます。
"there is an art to getting your way and throwing bananas on to the street is not it"
以下のコードを実行してください。
query_sentence = "there is an art to getting your way and throwing bananas on to the street is not it"
xq = model.encode([query_sentence]).tolist()
result = index.query(xq, top_k=5, includeMetadata=True)
result結果は以下の通り。意味的に似ている文が、高い順に5つ並んでいます。
{'matches': [{'id': '5',
'metadata': {'tokens': ['throwing',
'bananas',
'on',
'to',
'the',
'street',
'is',
'not',
'art']},
'score': 0.732851684,
'values': []},
{'id': '8',
'metadata': {'tokens': ['to',
'get',
'your',
'way',
'you',
'must',
'not',
'bombard',
'the',
'road',
'with',
'yellow',
'fruit']},
'score': 0.57442683,
'values': []},
{'id': '2',
'metadata': {'tokens': ['it',
'is',
'not',
'often',
'you',
'find',
'soggy',
'bananas',
'on',
'the',
'street']},
'score': 0.500876725,
'values': []},
{'id': '1',
'metadata': {'tokens': ['no',
'way',
'chimps',
'go',
'bananas',
'for',
'snacks',
'!']},
'score': 0.376693577,
'values': []},
{'id': '9',
'metadata': {'tokens': ['time',
'flies',
'like',
'an',
'arrow',
';',
'fruit',
'flies',
'like',
'a',
'banana']},
'score': 0.338697404,
'values': []}],
'namespace': ''}次に、キーワード検索も絡めた「Hybrid Search」を実行してみます。
クエリを実行する際に「bananas」というトークンが含まれているデータのみを検索するように指定します。要は以下の条件のもと、フィルタリングをかけているのと同じです。
“there is an art to getting your way and throwing bananas on to the street is not it”という文章と意味的に似ている
「bananas」というトークンが含まれている
result = index.query(xq, top_k=10, filter={'tokens': 'bananas'})
for i in result['matches']:
print(all_sentences[int(i["id"])])結果、4行がヒットしました。
throwing bananas on to the street is not art
it is not often you find soggy bananas on the street
No way chimps go bananas for snacks!
I'm getting way too old. I don't even buy green bananas anymore.2.3 所感
所感ですが、データをベクトルとして保管し、ベクトルとしてすぐに取り出せるのは便利だなと思いました。
自然言語処理の解析をする際にも、単語や文章はベクトルで扱います。非構造されたデータを、生データのまま保管して、取り出してベクトル化するのではなく、ベクトル化された状態で取り出せるので、スムーズに自然言語の分析が行えそうです。
では、一体従来のデータベースとどのくらい違いがあるのか、検証したいと思います。
PineconeとSQLの比較
ここまでは、Pineconeの簡単な使い方を解説しました。
ここでは、ベクトルデータベースと従来のデータベースは、どのくらい性能に差があるのか検証したいと思います。
比較する処理内容は、
検索の計算スピード
コード記述量
です。
今回は、100次元のベクトルデータを検索します。ちなみに、100次元のベクトルデータは、LLMなどでも使われるほど高次元なデータです。
このベクトルデータをN個用意し、N=100, 500, 1000, 5000, 10000, 20000と変化させた時の、検索スピードを比較します。
さらに、ベクトルデータを検索する際に、どのくらいコード量に違いがでるのかを比較します。コード記述量を抑えられれば、コードの加筆・修正も容易になり、効率的にデータベースを扱えるようになります。
まずはPineconeで処理してみます!
Pineconeで処理
まず、Pineconeを用いて、データの検索を行います。ソースコードは以下の通りです。
import pinecone
import numpy as np
import random, string
import time
import matplotlib.pyplot as plt
# ランダム文字列生成 (idの重複を避けるため)
def randomname(n):
return ''.join(random.choices(string.ascii_letters + string.digits, k=n))
# Pineconeの初期化
pinecone.init(
api_key="2d84de31-820b-4a30-b64f-55733e90c95f",
environment="asia-southeast1-gcp-free"
)
# インデックスの生成
pinecone.create_index(
"quickstart",
dimension=100,
pod_type="p1"
)
# インデックスに接続
index = pinecone.Index("quickstart")
# クエリベクトル
query_vector = np.random.normal(50,10,100).tolist()
data_sizes = [100, 400, 500, 4000, 5000, 10000] # データ量のリスト
execution_times = [] # 時間計算量を保存するリスト
for size in data_sizes:
for i in range(size):
# 正規分布に従う乱数ベクトル生成+データの挿入
index.upsert([
{"id": randomname(20), "values": np.random.normal(50,10,100).tolist()}
])
start_time = time.time()
# 類似のベクトルの取得
index.query(
vector=query_vector,
top_k=20,
include_values=True
)
end_time = time.time()
elapsed_time = end_time - start_time
execution_times.append(elapsed_time)
# 速度表示
plt.plot([100, 500, 1000, 5000, 10000, 20000], execution_times, marker='o')
plt.xlabel('data_size')
plt.ylabel('time')
plt.title('Pinecone')
plt.show()次に、SQLで同様の処理をします。
SQLで処理
先ほどは、Pineconeを使用して類似データ検索をしていました。ここでは、従来のデータベースである、リレーショナルデータベースで同様の処理をしてみます。以下の手順で実行します。
データベース作成
データ格納
データ抽出
類似度検索
そのために、ここではPythonライブラリの「sqlite3」を用います。ソースコードは以下の通りです。
import sqlite3
import numpy as np
import time
import matplotlib.pyplot as plt
data_sizes = [100, 400, 500, 4000, 5000, 10000] # データ量のリスト
execution_times = [] # 時間計算量を保存するリスト
# クエリベクトル
query_vector = np.random.normal(50,10,100).tolist()
# コサイン類似度
def cos_sim(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
# SQLiteデータベースの接続とカーソルの作成
conn = sqlite3.connect('keyword_search.db')
cursor = conn.cursor()
# テーブル作成
columns = ['id'] + [f'vector{i}' for i in range(1, 101)]
column_definitions = ', '.join([f'{column} INTEGER' for column in columns])
cursor.execute(f'CREATE TABLE database({column_definitions}, PRIMARY KEY (id))')
for size in data_sizes:
for i in range(size):
# データの挿入
vectors = np.random.normal(50,10,100).tolist() # ベクトルデータのリスト(長さは100)
vector_values = ', '.join([str(vector) for vector in vectors])
cursor.execute(f'INSERT INTO database({", ".join(columns)}) VALUES (NULL, {vector_values})')
# コミットして変更を確定
conn.commit()
start_time = time.time()
# データの抽出
cursor.execute('SELECT * FROM database')
rows = cursor.fetchall()
# query_vectorをNumPy配列に変換する
query_vector = np.array(query_vector)
# rows内の各行とのコサイン類似度を計算する
similarities = []
for row in rows:
# データベースから取得したベクトルをNumPy配列に変換する
db_vector = np.array(row[1:]) # ベクトルはid列以外の要素
# コサイン類似度を計算
similarity = np.dot(query_vector, db_vector) / (np.linalg.norm(query_vector) * np.linalg.norm(db_vector))
similarities.append(similarity)
# 上位20件のベクトルを取得する
top_indices = np.argsort(similarities)[::-1][:20] # 降順ソートして上位20件のインデックスを取得
top_vectors = []
for index in top_indices:
top_vectors.append(rows[index])
# 結果の表示
for vector in top_vectors:
print(vector)
end_time = time.time()
elapsed_time = end_time - start_time
execution_times.append(elapsed_time)
import matplotlib.pyplot as plt
plt.plot([100, 500, 1000, 5000, 10000, 20000], execution_times, marker='o')
plt.xlabel('data_size')
plt.ylabel('time')
plt.title('SQL')
plt.show()次に、いよいよ比較の結果を発表します。
検索スピードの比較結果
ベクトルデータを多くしていった時の、計算時間の推移をプロットすると、以下の通りになりました。

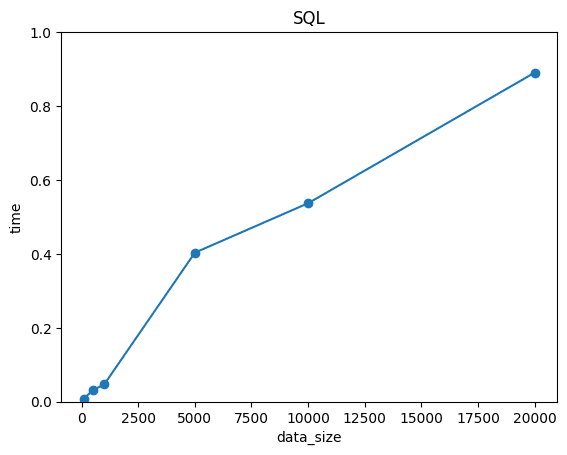

結果を見ると、SQLは小規模なデータでは計算スピードが早いが、データが大規模化すると大幅に時間が増えることが分かります。
一方で、pineconeはサンプルサイズによらず、常に0.5付近を推移していることが分かります。計算スピードに関しては、N=10000付近でSQLよりも早くなっています。
この結果から、NLPやLLMのように「大量の高次元データを扱うタスク」では、ベクトルDBの方が効率的になることが分かります。
では、コード記述量の方は、どうなったでしょうか?
コード量の比較結果
コード記述量は、Pineconeに比べてSQLの方が多かったです。
要因としては、Pineconeと違って、SQLでは、
クエリ処理の際に、DBからデータをわざわざ取り出さないといけない
ベクトルの類似度を計算する実装を、自分で行う必要がある
という面倒が追加されたからだと考えられます。
やはり、LLMやデータ解析などでベクトルは必ず使うデータ型なので、ベクトルのままデータベースに格納できるベクトルデータベースの方が、圧倒的に便利です。
また、SQLの場合、生データのままの格納になるので、わざわざ取り出した生データをベクトルに直す必要があり面倒です。さらに、類似データの検索という観点でも、Pineconeだとライブラリ側で類似度を勝手に計算してくれて、そのままデータを表示してくれます。
一方で、SQLの場合は、データをすべて取り出してベクトルに直し、さらに1つずつ類似度を計算する処理を、自分で実装する必要があります。
そのあたりも自動で行ってくれるPineconeの方が、コード記述量も抑えられて、やはり便利です。
このことから、非構造化データ、つまりベクトルデータを扱うようなタスクでは、Pineconeの方が、効率的にコーディング・管理することが可能です。
なお、ベクトルデータベースについて知りたい方はこちらをご覧ください。
→【院生が徹底解説】ChatGPTのベクトルデータベースとは?
まとめ
Pineconeは、数十億ものデータを扱うことができ、高速なクエリ処理を実現するベクトルデータベースです。PineconeのAPIを利用するためにも、Pineconeの公式ページで、「Sign Up for Free」をクリックして登録しておきましょう。
Pineconeでは、「基本的なキーワード検索」と「セマンティック検索」を組み合わせた「Hybrid Search」をおこなうことができます。
SQLは小規模なデータでは計算スピードが早いが、データが大規模化すると大幅に時間が増えることが分かります。
コード記述量は、Pineconeに比べてSQLの方が多かったです。
要因としては、Pineconeと違って、SQLでは、
クエリ処理の際に、DBからデータをわざわざ取り出さないといけない
ベクトルの類似度を計算する実装を、自分で行う必要がある
という面倒が追加されたからだと考えられます。