
【Petals】パラメーター100B超えのLLMを自宅のPCで動かす方法

皆さん、PetalsというLLMプラットフォームをご存知ですか?
なんと、大規模言語モデルが、Google Colabやご自宅のGPUで動かせるようになるんです。
え、、、ご存知ない!?まさかぁ(茶番)
扱えるモデルは、Llama2(70B)やFalcon(180B)などのパラメータ数が特級クラスのものばかり。誰でも、Google Colabさえあればこれらのモデルを動かせるんですよ!
やばくないですか!?やばいですよね!(脳死)
ということで、今回の記事ではPetalsというLLMプラットフォームの概要、導入、実際に使ってみた感想についてまとめています。
この記事を最後まで読むと、Petalsを理解できるようになります。
ぜひ最後までご覧ください!
Petalsの概要
Petalsは、家庭用のGPUやGoogle Colabを使用して、大規模な言語モデルを実行するためのプラットフォームです。動かせるモデルは、Llama 2(70B)、Falcon(180B)、BLOOM(176B)など、化け物クラスのパラメータ数を誇るLLMばかりです。
そんなPetalsの特徴は以下の4点です。
分散型パイプライン:Petalsは、高速なニューラルネットワークの推論のための分散型パイプラインとして動作します。モデルはいくつかのブロックに分割され、それぞれが異なるサーバー上でホストされます。
透明性:ブロックの各入力と出力はネットワーク上で送信されるため、モデルのレイヤー間にタスク固有のアダプタを挿入することが可能です。これにより、サーバー上の事前学習済みモデルを変更することなく、軽量な微調整が可能となります。
実用性:Petalsのインターフェースは、Transformersライブラリに非常に似ており、複雑なロジックなどは表示されず、分かりやすいUIになっています。
ベンチマーク:Petalsは、同様のプラットフォームであるオフロードとの性能を比較して、レイテンシーが3〜25倍速いことが比較実験で示されています。
分散型パイプラインについてもう少し詳しく説明すると、Petalsで大規模なモデルを動かせるのは、、BitTorrentのようなP2Pの通信手法をとっているからです。
P2Pを使うと、容量の大きなファイルを大勢のユーザーで分散し共有することができます。BitTorrentの技術は、高速で効率的なデータ転送を可能にするため、Petalsプラットフォームは大規模なモデルもスムーズに動作させることができるということですね。
さらにPetalsは、ファインチューニングやサンプリング方法も使用できるため、多様な用途に対応しています。
ここまでPetalsの概要をご説明してきましたが、ここからは実際に使いながら機能を紹介していきます。
なお、Llama2について詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Llama 2】オープンソース版ChatGPTの使い方〜ChatGPTとの比較まで
Petalsの料金体系
Petalsはオープンソースプロジェクトであり、GitHubから無料でダウンロードして使用することができます。
ただし、Google Colab Pro / Pro + を使う場合、月額1,179円 / 5,767円がかかります。
それでは、気になるPetalsの導入方法を見ていきましょう。
Petalsの導入方法
以下のGoogle Colabファイルにアクセスします。
Petals - Getting started with Llama 2 and Stable Beluga 2 (GPU Colab)
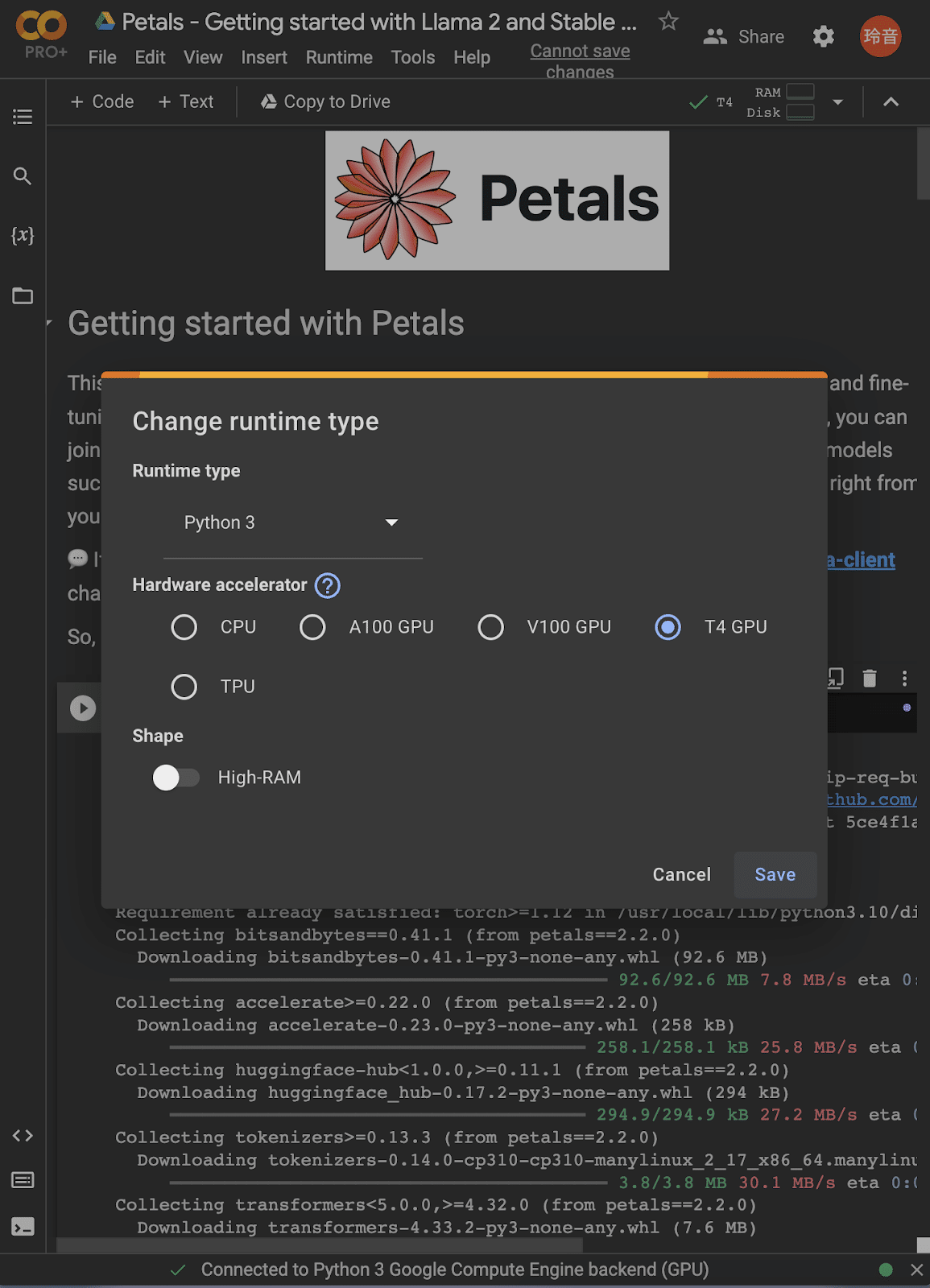
画面上部のメニューバーからRuntime →Change runtime type をクリックします。

GPUを選択します。今回は、共有したColabファイルの初期設定のまま、T4 GPUを使いました。
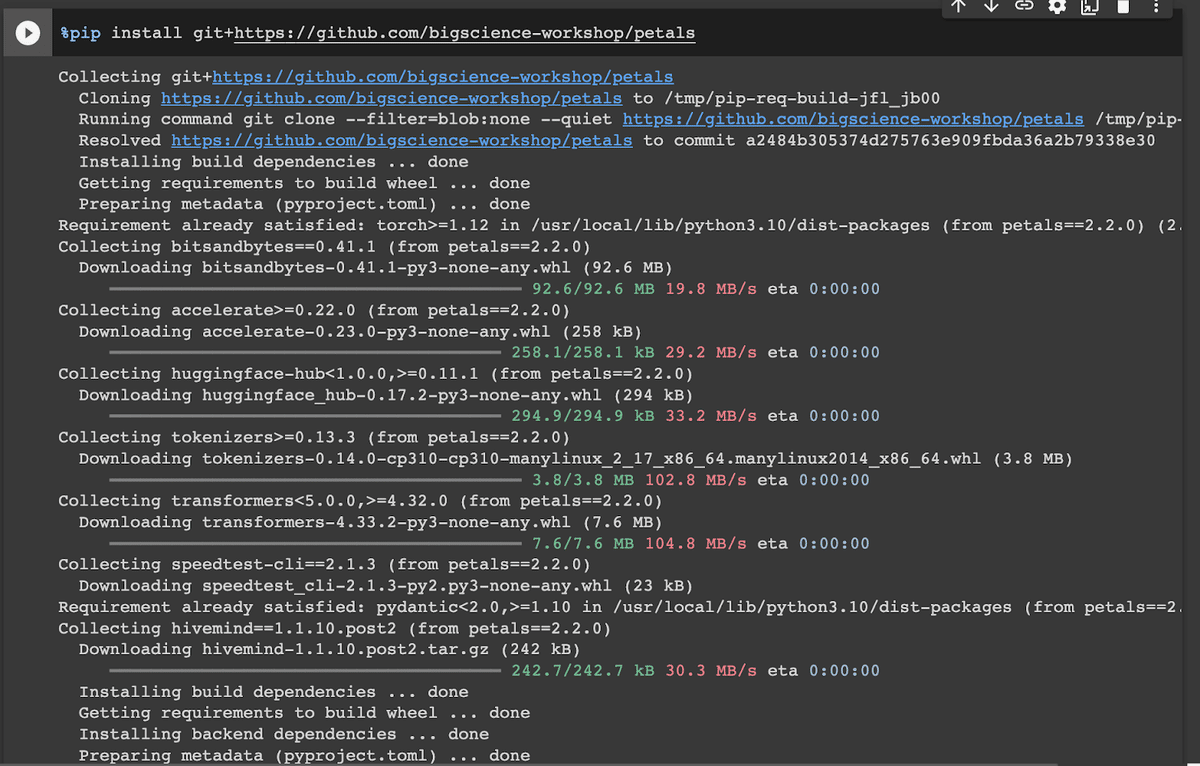
以下を実行しPetalsのパッケージをインストールします。
%pip install git+https://github.com/bigscience-workshop/petals実行すると以下のような画面になります。
次に、以下を実行し、StableBeluga2というモデルをロードします。
import torch
from transformers import AutoTokenizer
from petals import AutoDistributedModelForCausalLM
model_name = "petals-team/StableBeluga2"
# You could also use "meta-llama/Llama-2-70b-chat-hf" or any other supported model from 🤗 Model Hub
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, add_bos_token=False)
model = AutoDistributedModelForCausalLM.from_pretrained(model_name)
model = model.cuda()このようになったら準備完了です。

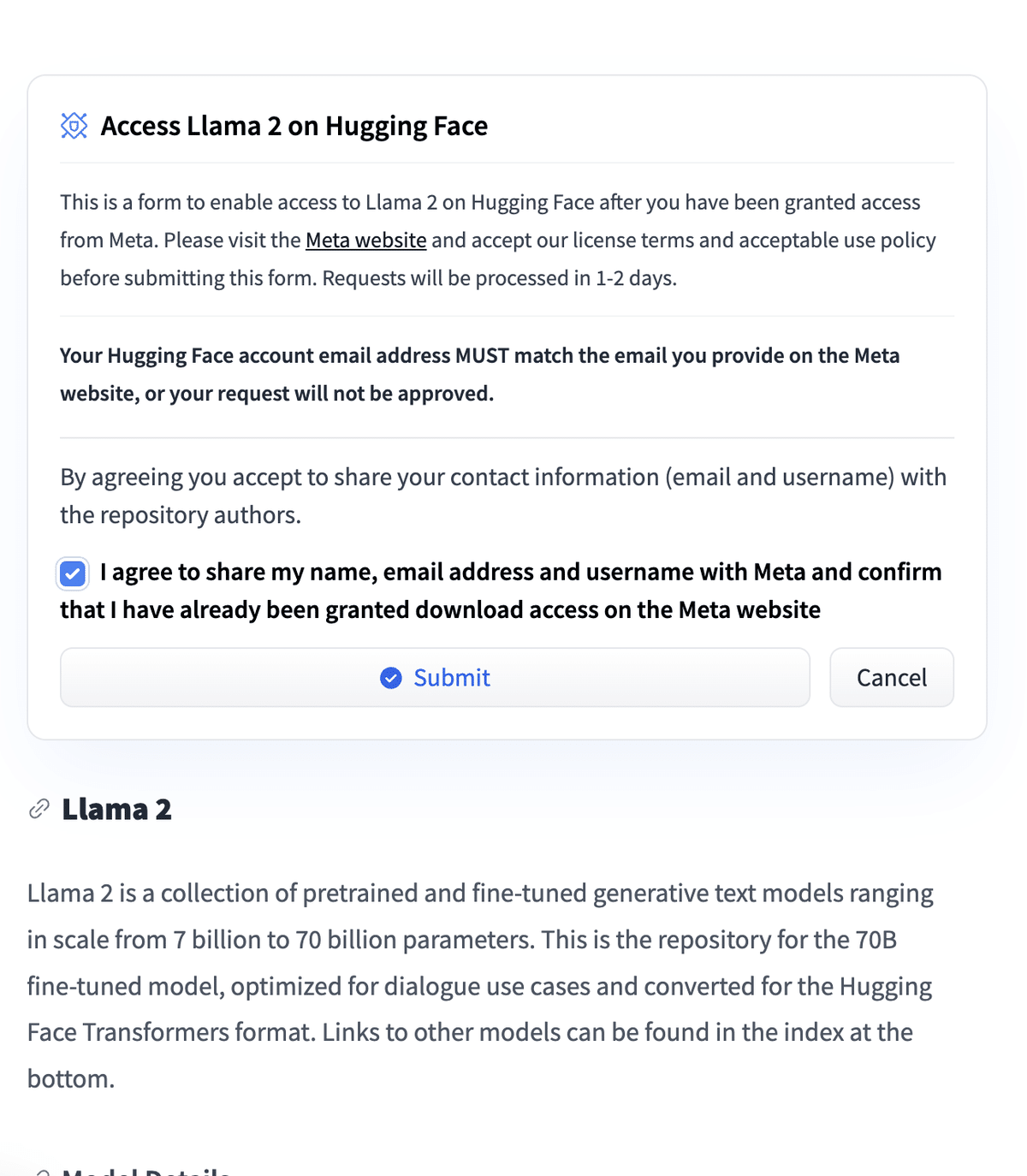
ちなみに、"meta-llama/Llama-2-70b-chat-hf"モデルを使う場合は、Metaにアクセストークンをリクエストする必要がありますので、以下の手順でリクエストを送信してください。
まずは、こちらのURLにアクセスします。
meta-llama/Llama-2-70b-chat-hf
下にスクロールするとこんな画面があるので、「I agree…」にチェックを入れて、Submitを押しましょう
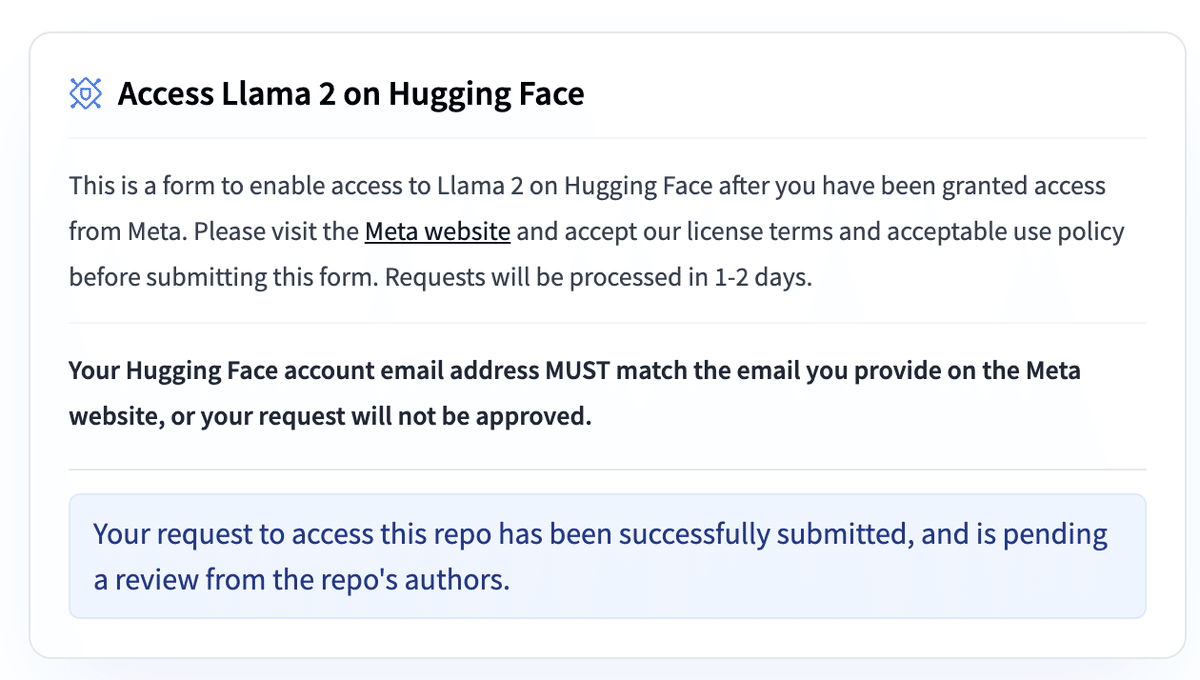
以下のように、リクエストに成功と出たらOKです。
次にHugging Faceのアクセストークンを取得します。
Hugging Faceにログインした状態で、以下のページにアクセスします。
New tokenをクリックして生成します。

終わったら、Google Colabで、以下のコマンドを実行。
!huggingface-cli login --token your-access-tokenLogin successfulと出たらOKです!

Llama-2-70b-chat-hf モデルを選択して実行する。
import torch
from transformers import AutoTokenizer
from petals import AutoDistributedModelForCausalLM
model_name = "meta-llama/Llama-2-70b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, add_bos_token=False)
model = AutoDistributedModelForCausalLM.from_pretrained(model_name)
model = model.cuda()以下のようになっていたらOKです!

Petalsを実際に使ってみた
これ以降は、以下の記事からご確認ください。
他の記事もご覧になりたい方は、こちらをご覧ください。