
人気を50年間集め続ける技術、関係データベースを実践で学ぶ 〜RDB, SQL, ER図〜

プログラム自学案内の27回目です。前回の記事ではPostgreSQLの導入とカンタンな紹介をしました。今回はPostgreSQLの一番面白い機能、SQLによる集計、結合操作を実践的に紹介します。
この分野は、学習のコスパが高い分野と言えるはずです。なぜってこれからも、あと何十年かは使われ続ける技術でしょうから。SQLは発明されてから50年くらい経ちますが、いまだに主流の技術であり続けているのです(流行り廃りの激しいITの世界では稀なことだと思います)。
なお、前回までの記事はこちらからどうぞ。
RDB(関係データベース)って?
まずはRDBについて簡単に紹介します。RDBは relational database の略称で、日本語では リレーショナル・データベースとも、関係データベースとも、呼ばれます。
なお、前回の記事では、RDBMS という言葉がでてきましたが、これは単にRDBを扱うDB製品のこと、と理解しておけばよいでしょう。
ひとことで言えば、データをテーブル(表)に小分けするDB
ではRDBの説明です。ひとことでいえば、RDBとはデータをテーブル(table, 表)の形に小分けして管理するデータベースのこと、となります。表というものは、日常的に見慣れており、大変直感的ですから、RDBが発明されるや大人気になり、50年間その人気が続くのも無理ないことです。
RDBのテーブルは、ふつうの表とどう違うか
RDBのテーブルは先ほど述べたとおり、ひとことで言うなら表なのですが、ふつうの表とは違うところがあります。じつは、その違いこそが、RDBのキモなのです。違いを見てみましょう。
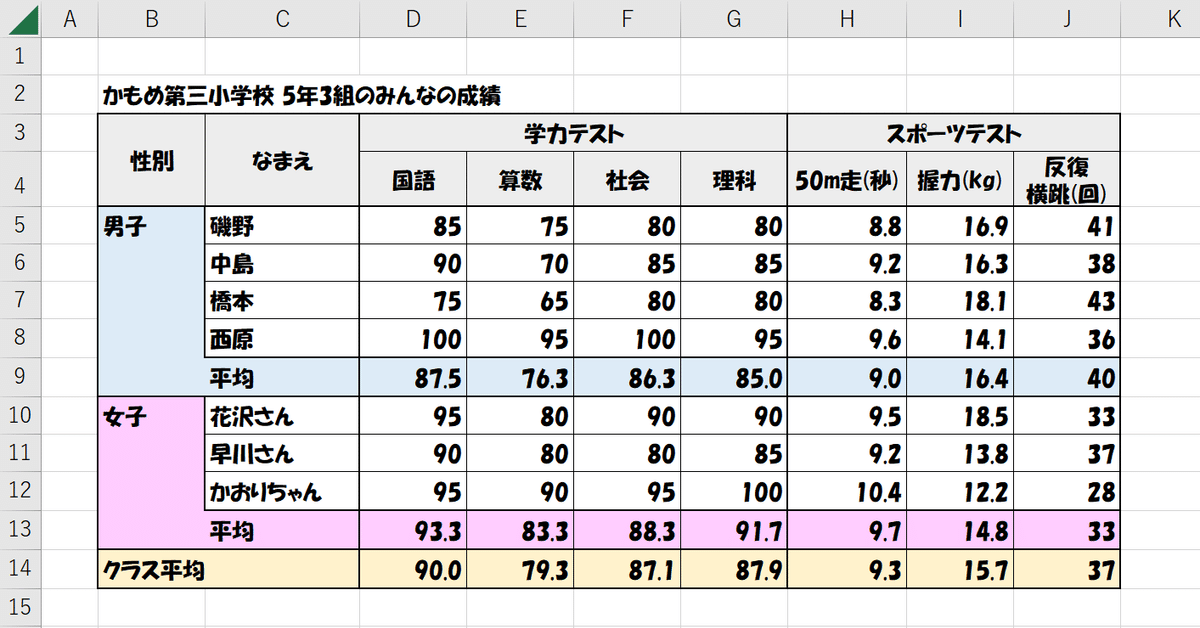
よくあるExcel表の例
こちらがよくある表の例です。
RDBのテーブルの例
上の表と同じデータを、RDBのテーブルに持たせた例を示します(RDBをグラフィカルに操作できるツール(PgAdmin) により表示させています)。「よくあるExcelで作られた表」と比べ、みづらく、表ひとつひとつの構造が素っ気ない感じがしますね。
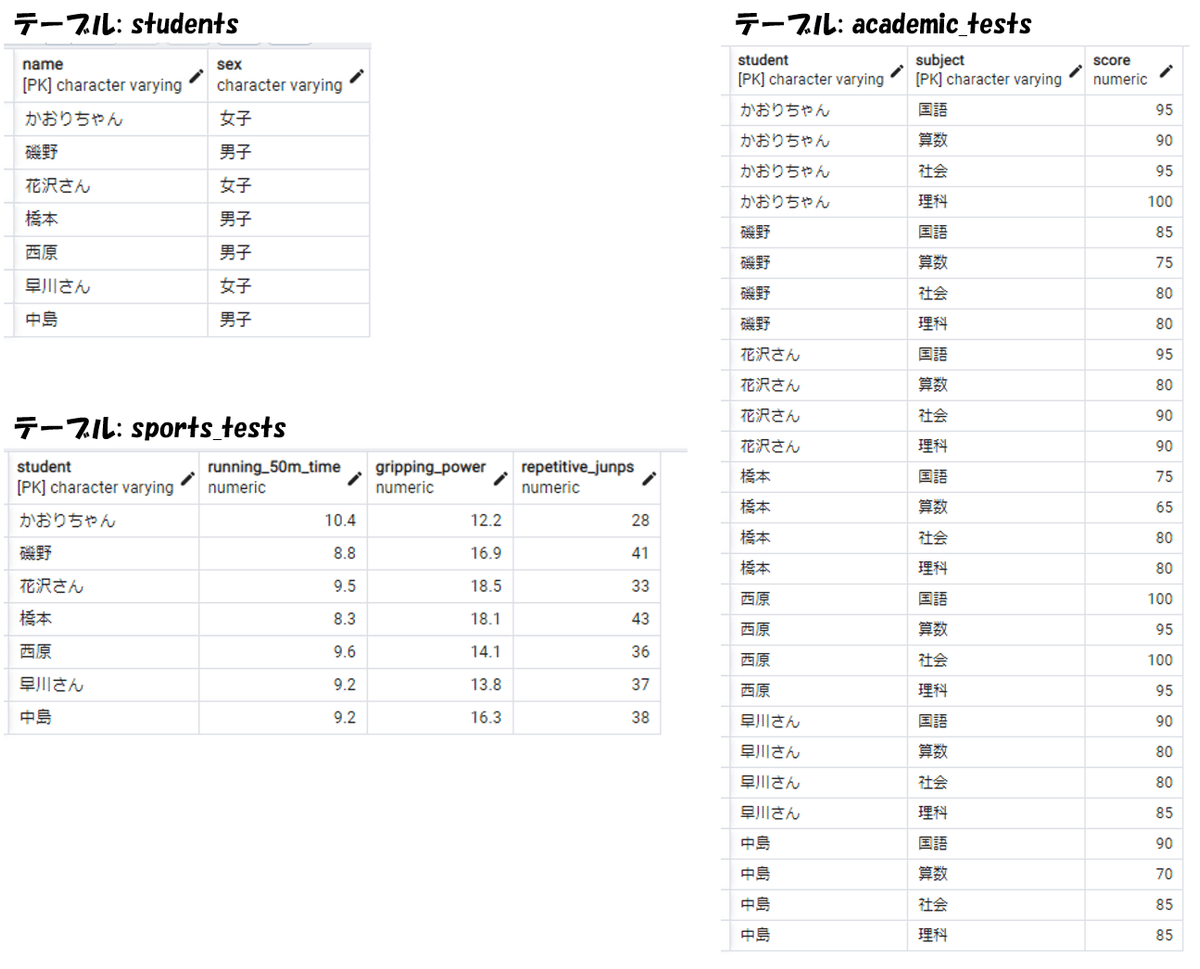
RDBのテーブルの構造
RDBのテーブルについて、とりあえず次の2つだけは覚えてください。
「テーブル定義」と「データ」に分かれている
行と列で性質が結構ちがう。ただのタテとヨコのちがいだけではない
さらに詳しめに、テーブルの構造を図解してみましょう。

テーブル名、列、主キーによって、テーブル定義が作られます。
列(column, カラムとも呼ばれます)は複数定義されます。
列には、列名のほかに、格納可能なデータの型が定義されます。
主キー(primary key, PK, Pキーとも呼ばれます)は1つ定義されます。
主キーとは、行の特定に 主に使われる列のことです。
2つ以上の列の組み合わせが主キーになることもあります。
行(row, record, レコードとも呼ばれます)の集まりとして、データが格納されます。
行は上下の並び順を持ちません(縦に並んでいません)。
「上から何行目」という方法で行を指定することではきません。
行は行名を持ちません。
かわりにその行の、主キーの列の値が、行名に似た役割をはたします。主キーのデータは、値の重複が許されません。
値の重複がないことを 一意性がある(unique, ユニーク) と言います。
データの追加・削除によって、行が増減しますが、列は増減しません。
行をまたいで、列方向の検索、集計ができます。
ですので、いい塩梅で縦長な形のテーブルを作るのがRDB利用のコツになります。
ざっとこんなところでしょうか。
現時点でいきなり全部理解したり覚えたりしようとしなくても、いいでしょう。絵と照らし合わせながら、何となく目を通すくらいの感じでよいでしょう。なぜなら、このあとSQLを学ぶと、テーブルへの理解は深まり、上で説明した内容は、自然と身につくはずですので。
RDB は SQLを使って操作する
RDBのもう一つの特徴は、SQL(Structured Query Language)という言語で操作されることです。
SQLは、さらに次の3つに分類されます。それぞれの分類の意味は、言葉の通りです(DCLのみちょっと意味が分かりづらいですが、ここでは、いったん無視してもらって構いません)
DDL(Data Definition Language, データ定義言語)
DML(Data Manipulation Language, データ操作言語)
DCL(Data Control Language、データ制御言語)
このなかで、とびきり面白く、かつ利用頻度も圧倒的なのがDMLです。
クエリの実践で学ぶSQL
SQLのなかでも華といえるのは、データの読み出し、検索、集計を行う命令です。これをクエリ(query, 問い合わせ)と言います。ちなみに、SQLという言葉に入っている Q の文字も、query の略語です。
この記事ではこれから、前回導入したPostgreSQLを使って、SQLでクエリを組み立てる練習をしてみたいと思います。易しいものから順に、全部で5題出しますよ!
準備
クエリをつかってデータの読み出し、集計をするためには、そのまえにまず、読み出し対象のデータが入ったテーブルがなければ始まりません。準備しましょう。
psql で PostgreSQL のDBにログインし、次のSQL文を実行してください(一度に全部コピペしてしまってかまいません)
CREATE TABLE students (
name VARCHAR,
sex VARCHAR,
PRIMARY KEY (name)
);
INSERT INTO students VALUES ('磯野', '男子');
INSERT INTO students VALUES ('中島', '男子');
INSERT INTO students VALUES ('橋本', '男子');
INSERT INTO students VALUES ('西原', '男子');
INSERT INTO students VALUES ('花沢さん', '女子');
INSERT INTO students VALUES ('早川さん', '女子');
INSERT INTO students VALUES ('かおりちゃん', '女子');
CREATE TABLE academic_tests (
student VARCHAR,
subject VARCHAR,
score DECIMAL,
PRIMARY KEY (student, subject),
FOREIGN KEY (student) REFERENCES students (name)
);
INSERT INTO academic_tests VALUES ('磯野', '国語', 85);
INSERT INTO academic_tests VALUES ('中島', '国語', 90);
INSERT INTO academic_tests VALUES ('橋本', '国語', 75);
INSERT INTO academic_tests VALUES ('西原', '国語', 100);
INSERT INTO academic_tests VALUES ('花沢さん', '国語', 95);
INSERT INTO academic_tests VALUES ('早川さん', '国語', 90);
INSERT INTO academic_tests VALUES ('かおりちゃん', '国語', 95);
INSERT INTO academic_tests VALUES ('磯野', '算数', 75);
INSERT INTO academic_tests VALUES ('中島', '算数', 70);
INSERT INTO academic_tests VALUES ('橋本', '算数', 65);
INSERT INTO academic_tests VALUES ('西原', '算数', 95);
INSERT INTO academic_tests VALUES ('花沢さん', '算数', 80);
INSERT INTO academic_tests VALUES ('早川さん', '算数', 80);
INSERT INTO academic_tests VALUES ('かおりちゃん', '算数', 90);
INSERT INTO academic_tests VALUES ('磯野', '理科', 80);
INSERT INTO academic_tests VALUES ('中島', '理科', 85);
INSERT INTO academic_tests VALUES ('橋本', '理科', 80);
INSERT INTO academic_tests VALUES ('西原', '理科', 95);
INSERT INTO academic_tests VALUES ('花沢さん', '理科', 90);
INSERT INTO academic_tests VALUES ('早川さん', '理科', 85);
INSERT INTO academic_tests VALUES ('かおりちゃん', '理科', 100);
INSERT INTO academic_tests VALUES ('磯野', '社会', 80);
INSERT INTO academic_tests VALUES ('中島', '社会', 85);
INSERT INTO academic_tests VALUES ('橋本', '社会', 80);
INSERT INTO academic_tests VALUES ('西原', '社会', 100);
INSERT INTO academic_tests VALUES ('花沢さん', '社会', 90);
INSERT INTO academic_tests VALUES ('早川さん', '社会', 80);
INSERT INTO academic_tests VALUES ('かおりちゃん', '社会', 95);
CREATE TABLE sports_tests (
student VARCHAR,
running_50m_time DECIMAL,
gripping_power DECIMAL,
repetitive_junps DECIMAL,
PRIMARY KEY (student),
FOREIGN KEY (student) REFERENCES students (name)
);
INSERT INTO sports_tests VALUES ('磯野', 8.8, 16.9, 41);
INSERT INTO sports_tests VALUES ('中島', 9.2, 16.3, 38);
INSERT INTO sports_tests VALUES ('橋本', 8.3, 18.1, 43);
INSERT INTO sports_tests VALUES ('西原', 9.6, 14.1, 36);
INSERT INTO sports_tests VALUES ('花沢さん', 9.5, 18.5, 33);
INSERT INTO sports_tests VALUES ('早川さん', 9.2, 13.8, 37);
INSERT INTO sports_tests VALUES ('かおりちゃん', 10.4, 12.2, 28);
;これで、RDBの説明で用いた画像そのままのデータが作られたはずです。つぎのクエリを実行し、確かめてください。
SELECT * FROM students;
SELECT * FROM academic_tests;
SELECT * FROM sports_tests;第1問: 列の選択, 列の別名 (SELECT, AS, FROM)
ではここからは、SQLを読者自身で調べ、SQL文を読者自身で作ってみましょう。
最初に学ぶのは、列の選択、列の別名の付与です。下の画像のとおり、sports_testsテーブルから、生徒名と50m走のタイムを抜きだし、日本語の列見出しで表示したいです。どのようなSQL文を実行すればいいでしょうか?
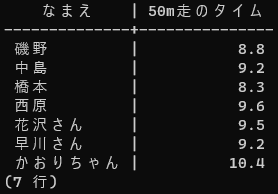
SQL の SELECT, FROM, AS の各単語の使い方をしらべて、既にあるテーブルから、このような表を出力するSQL文を作ってみてください。
第2問: 絞り込みとソート (WHERE, ORDER BY)
つぎは 絞り込み と ソート です。なお、ソート(sort) とは、値の小さい順や大きい順で並べ替えることを言います。
下の画像のとおり、academic_testsテーブルから、国語の点数だけを抜き出し、成績の良い順に表示してみましょう。

SQL の WHERE, ORDER BY の使い方を調べて、第1問で学んだフレーズと組み合わせて、このような表を出力するSQL文を作ってみてください。
第3問: 集計 (GROUP BY, AVG)
つぎは 集計 です。次の画像のとおり、academic_testsテーブルから、各科目の平均点を集計してみます。
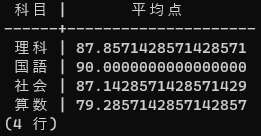
これまでの問題で学んだフレーズに加え、SQL の GROUP BY, AVG の使い方を調べれば、このような表が出力できるはずです。
第4問: 結合 (INNER JOIN)
いよいよRDB最大の見せ場、結合です。次の画像のとおり、50m走のタイムを早い順に、生徒の性別とともに表示させてみましょう。

これをやるには、sports_testsテーブルとstudentsテーブルを、それぞれのテーブルに入っている生徒の名前で突き合わせて結合します。
これまでの問題で学んだフレーズに加え、SQL の INNER JOIN の使い方を調べれば、このような表を出力するSQL文が作れるはずです。
第5問: 応用問題
最後にちょっと難易度をあげてみます。次の画像の通り、科目×性別ごとの筆記テストの平均点を集計して、表にしてみましょう。
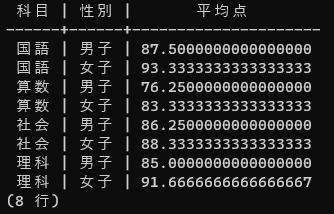
これまでの問題で学んだ、ソート、結合、集計の技をうまく組み合わせれば、このような表を出力するSQL文が作れます。
どうですか、できましたか。
SQLには、ほかにどんなフレーズが?
あとは、大体つぎのフレーズを一通り試して、ざっくり理解しておけば、ひとまずはいいんじゃないでしょうか。
DDL
基本
CREATE TABLE / CREATE INDEX / CREATE VIEW / DROP TABLE / ALTER TABLEデータ型
VARCHAR / INTEGER / DECIMAL / DATE / TIMESTAMP列制約
NOT NULL / UNIQUE / PRIMARY KEY / FOREIGN KEY
DML
基本
INSERT INTO VALUES / SELECT / UPDATE / DELETE並べ替え
ORDER BY / ASC / DESC絞り込み
WHERE / LIKE / BETWEEN / IN / EXISTS集約・集計
DISTINCT / GROUP BY / HAVING / COUNT / SUM / MAX / MIN / AVG結合
INNER JOIN / LEFT OUTER JOIN
ここまで知っておけば、IPAの基本・応用情報技術者試験のデータベース問題くらいなら、解けるようになるはずです(たぶん)。
ER図の紹介
最後に、ER図(Entity-Relationship Diagram, ERD, 実体関連図)を紹介します。
現実のコンピュータシステムでは、たくさんの数のテーブルがつくられます(10テーブルを超えるのはザラ、多いと100テーブルを超えます)。こういうときに、その全体像の把握に役立つのが ER図 です。
ER図の記法には様々な流儀があるのですが、概ね次の点で共通しています。
1つのテーブルを1つの四角として書く
四角のなかにテーブルが持つ列名を書く
列名のなかでは主キーの列を一番上に書き、主キーと分かるようにする
テーブル間の関係を、線でつないで示す
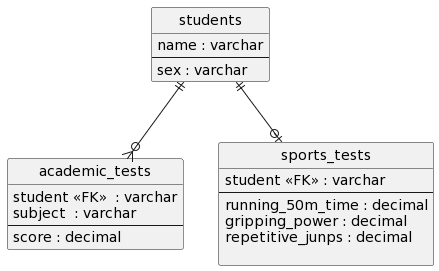
今回の記事で使ったテーブルたちをER図にすると、例えばこんな感じになります。(ちなみに、この画像のER図は PlantUMLというツールを使って描きました。ER図を描くツールは他にもあるので、興味がある方は調べてみてください。)
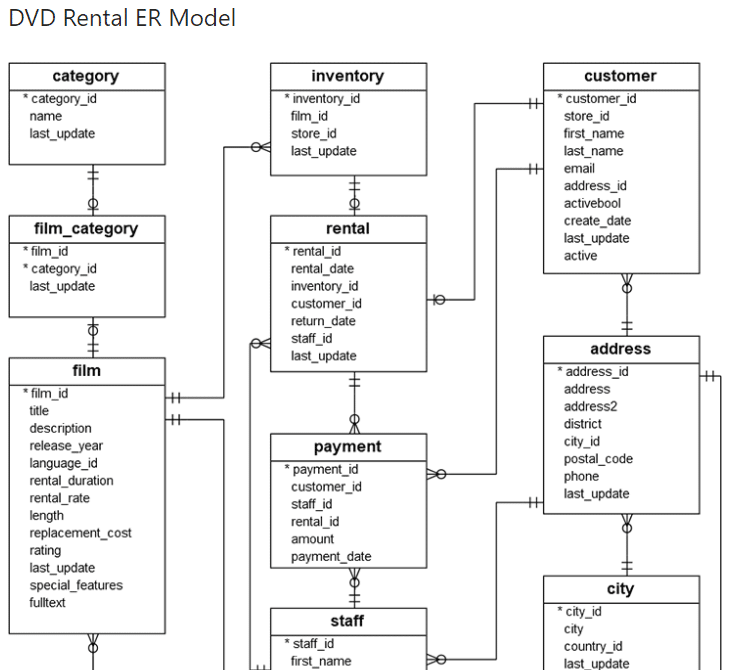
もう少し複雑な例として、PostgresSQLチュートリアルのサイトにある、サンプルデータベース「dvdrental」のER図の一部をお見せします。図の全体はこちらにあります。
ER図さえ見ればシステムが分かる!(かも)
個人的な思い出話をさせて下さい。
「プロジェクト配属初日には、俺はいつも真っ先に、文書のなかからER図を探し出し、目を通す。それが、アプリやシステムのあらましを最も手早く把握する方法だから」
なーんてことを、かつての私の上司は言っていました。
この上司の言っていることは、どんな状況でも正しいわけでは無いでしょうけれど。私はこの話を聞いて「なるほど、この上司さんは面白いこと言うなあ」と思ったものです。
なぜって、アプリやシステムを知るための第一歩として 「そのシステムは中心にどのような意味のデータを、どのような形で抱えるのか」 という点に関心のフォーカスを合わせるのは、なかなかセンスの良いやり方だと思うからです。でもって、フォーカスのあったそこを、あらわにする見取り図こそが、ER図なのですね。
以上、ER図の紹介でした。
まとめと次回予告
今回の記事では、前回導入したPostgreSQLを使ってRDBとSQLの案内をしました。
次回予告です。次回からは DCLによるトランザクション操作、そして、並列処理と排他制御の取り扱いについて、とりあげたいと思います(複数回にまたがるかもしれません)。このテーマは、これまでで最も手ごたえがあり、ヤッカイで、泥臭く、ウンザリするようなテーマかもしれません。オラ、なんだかワクワクしてきたぞ😅!
余談
'00年代のベストセラーラノベ、谷川流の「涼宮ハルヒの憂鬱」には、女子高生の登場人物、長門有希が、主人公の命を狙う敵と対峙しながら 「小説の朗読をするような口調で」つぎのSQL文めいたセリフをつぶやく場面があります。
「SELECTシリアルコードFROMデータベースWHEREコードデータORDER BY攻性情報戦闘HAVINGターミネートモード。パーソナルネーム朝倉涼子を敵性と判定。当該対象の有機情報連結を解除する」
この長門有希という女子高生はナカナカのやり手で、敵とバトルを繰り広げたあげく、ついに敵を打ち倒し主人公の命を助けてしまいます。
フィクションの出来事ではありますが、SQLとは、かくも偉大です。RDBやSQLをうまく使いこなせるようになると、まるでこの長門有希のように敵を倒せる、くらいの万能感を持てるかもしれません。
#コラム #プログラミング #独学 #案内 #RDB #PostgreSQL #SQL #ER図 #涼宮ハルヒの憂鬱 #長門有希