
AIセーフティーのためのLLMオブザーバビリティとLLMOps


AIガバナンス・セーフティーを取り巻く国内の枠組み
日本では2024年4月19日に総務省と経済産業省から「AI事業者ガイドライン(第1.0版)」が公表され、AIの安全安心な活用を促進するための統一的な指針が示されました。このガイドラインはAIの開発・提供・利用を担う全ての事業者を対象とし、AI開発者、AI提供者、AI利用者それぞれに求められる要件を明確化しています。また、AIセーフティ・インスティテュート (AISI)からもAI開発者・AI提供者を対象とした「AIセーフティに関する評価観点ガイド(1.0.0版)」が示されています。これらの動きは特に生成AIの高い汎用性と社会に与えうる大きな影響を考慮すると、AI事業者には従来より大きな責任が求められることを反映しています。そして、その責任を果たすためには、運用しているAIについて記録を残し、追跡可能性と説明可能性を担保する必要が出てきます。
AIセーフティーのための3つの重要要素
検証可能性の確保
生成AIアプリケーションの安全性についての取り組みにあたって、当然ながらその実行履歴が記録に残っていなければ、検証や判断、問題への対応が満足にできません。また、単に記録に残っているだけでは不十分です。生成AIを組み込んだアプリケーションは時に多数のLLMやその他ツールを連携させて複雑なチェインを形成していますので、体系的・構造的に記録しなければ後から追跡することが難しくなるからです。AIセーフティに関する評価観点ガイドにおいても、「検証可能性が十分でない場合、AIセーフティに関する問題が発生した際の原因の特定ができない可能性がある」と指摘されています。
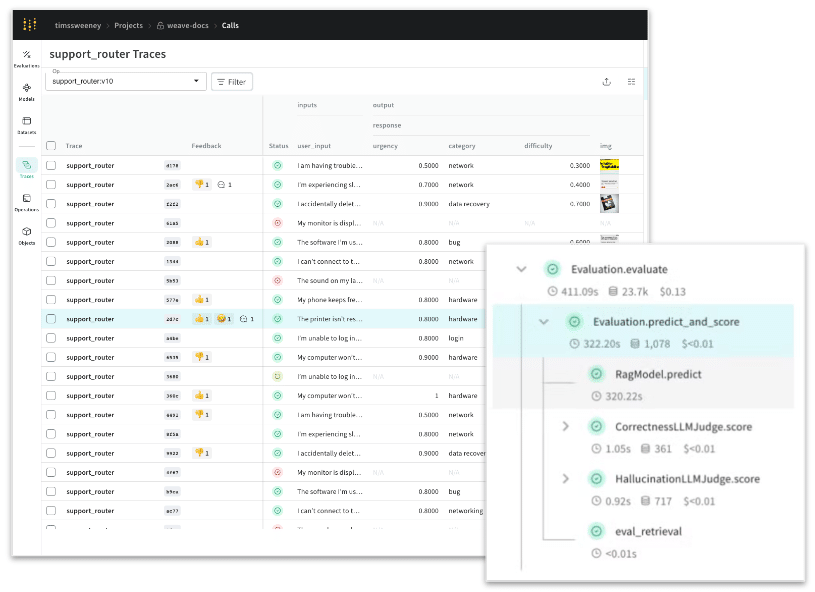
W&B Modelsを用いて実験管理を行うことで、基盤モデルの構築やファインチューニングのプロセスとそれらの関係性をしっかりロギングします。また、W&Bのトレース機能「Weave Traces」は、すべての入力データと出力データを自動的に記録し、簡単に操作できるトレースツリーに詳細な情報を構造的に記録することでこの課題に対応します。そのために必要な追加コードはほんの数行です。
説明可能性の担保
生成AIアプリケーションの説明性を担保するためには、どのようなAIモデルがどのように判断して、それらの出力を行なったかを示す必要があります。ここで、従来のAIと比較して異なる点として、システムプロンプトのバージョンやRAGシステムなど含まれる要素が多い点が挙げられます。これらも含めて記録管理することで、複雑な階層構造をなす生成AIアプリケーションのどのような変更が生成AIの挙動を変化させたのか、どのような根拠のもとに判断を行ったのかを常に説明可能であることが求められるのです。

AI事業者ガイドラインの「透明性」の項目においても、「AIの判断にかかわる検証可能性を確保するため、データ量又はデータ内容に照らし合理的な範囲で、AIシステム・サービスの開発過程、利用時の入出力等、AIの学習プロセス、推論過程、判断根拠等のログを記録・保存する」ことが求められています。「Weave Models」と「Weave Traces」の組み合わせにより、モデルの動作を定義する基盤モデル、システムプロンプト等の要素を体系的に管理し、説明可能性を確保します。
定期的・継続的評価の実施
生成AIアプリケーションにおいても評価は重要です。定期的・継続的に事前定義した評価パイプラインを実行することで、常にフェアな条件のもとにモデル性能を監視することができます。評価指標としては従来のAIで用いていたようなAccuracy Scoreのような決定論的な指標に加えて、いわゆるLLM-as-a-JudgeのようなLLMの評価にLLMを用いる手法も用いられます。また、RAGシステムまで含めた評価も行われます。そのため、評価自体にも前述の検証可能性・説明性の担保が必要であり、その上で結果を定量的に集計・可視化しなければなりません。

AIセーフティに関する評価観点ガイドでは、「AIセーフティ評価の各観点に関連する各種のベンチマーク、チェックリスト、バランス・スコアカードなどを参照し、LLMシステムによる出力や訓練データがそれらと適合しているかを見定めること」が推奨されています。「Weave Evaluations」を用いることで、データセットと評価メソッドを組み合わせた評価系を定義し、結果の比較と分析を継続的・視覚的に行うための仕組みを構築できます。
まとめ: 効果的なLLMオブザーバビリティの実現

ここまで見てきた通り、生成AIアプリケーションの開発においてはAIセーフティーへの取り組みが明確に求められており、LLMオブザーバビリティがその基礎となります。W&B Weaveの機能群は、AI開発者とAI提供者それぞれの立場で求められるそれらの要件に対応しており、AI開発者は深層学習の実験の詳細な記録と実験間の関係性の追跡を、AI提供者はログの記録やトラブル発生時の対処、さらにAIシステムの品質、安全性、公平性の確保を実現できます。
是非ともW&Bを活用することで、安全で信頼性の高いAIシステムの開発・運用を実現して頂きたいと思います。
