
W&B Weave を使ってRAGボットの性能を大幅改善 🤖

このブログでは、Weights & Biasesの製品であるWeaveを使用して、Weights & Biasesが提供するサービスの1つであるwandbotを改善するドッグフーディングの例を紹介します。(ドッグフーディング: 自社の製品を使い、自社のサービスを改善することの例え)
本番環境での生成AIアプリの運用は難しい…
便利なツールやライブラリの登場により、生成AIアプリのプロトタイプを構築するのは比較的容易になってきていますが、これらのプロトタイプを本番環境に移行するのは困難です。それは例えば以下のような理由によります。
性能に関する自信の欠如:開発者は多くの場合、自分たちの生成AI応用の性能に自信を持てていない。
デバッグの複雑さ:性能の問題を認識していても、様々なモデルチェーンや関数呼び出しを含む複雑なシステムのため、アプリケーションの改善が困難。
継続的なモニタリング:開発を一回限りのプロセスと考えるのではなく、アプリケーションを継続的にモニタリングし評価する必要がある。
システム変更と改善:API仕様が変更されたり、アプリのパフォーマンスが悪いことが判明した場合、アプリケーションを再構築する必要がありますが、複雑なシステムのデバックと包括的な評価に時間がかかってしまう。
実際、多くの企業や開発者が上記の課題に直面しています。一方で、開発が進むにつれて、課題が共有され、それらを解決するためのベストプラクティスやツールが提案されており、これらはOps(生成AIの場合はGenAI Ops)と呼ばれています。GenAIOpsを採用することで、GenAIアプリケーションをデモからプロダクションレベルに昇華するためのワークフローを確立し、短時間で高品質なAIアプリケーション開発を実現します。Weights & Biasesは、生成AIの初期段階からモデルトレーニング(基盤モデルの構築やファインチューニングなど)やモデルバージョン管理に使用できるツールを提供してきました。そして、2024年より、生成AIアプリケーションの開発をサポートするツールであるWeaveの提供を開始しました。

Weaveは主に以下の機能を提供します:
"Trace":開発途中で異なるコンポーネント間で特定の出力がどのように生成されるかを可視化。本番環境のモニタリングにも活用できます。
"Evaluation":アプリのパフォーマンスを評価するための定量的な指標を体系的にベンチマークし計算する方法を提供します。
詳しくは、下記の動画やWeaveのドキュメントを参照してください。
また、npakaさんの記事もご参照ください。
Wandbotの本番モニタリング
Weights & Biasesは、Wandbの使用方法に関する質問に答えることができるwandbotを運用しています。以下は、日本語のSlackコミュニティチャンネルでwandbotに質問をした例です(質問: ウェブインターフェースでどのようにしてrunを停止できますか?)。
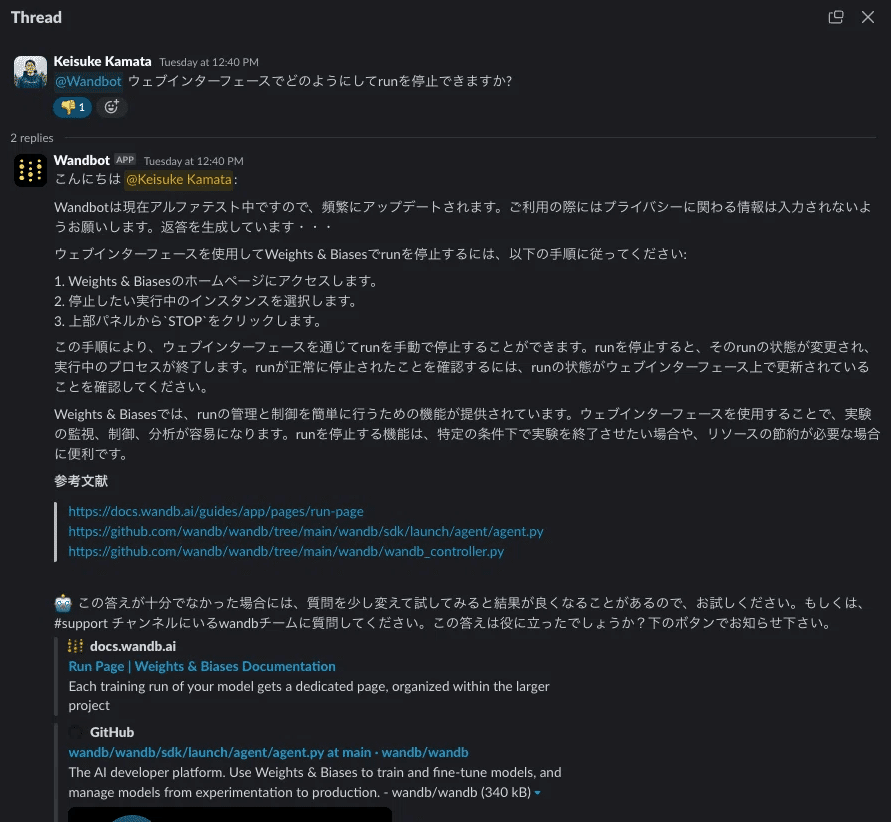
💡まだWandBotを使ったことがない方は、slackコミュニティチャンネル(wandbjp.slack.com)にアクセスして#wandbotチャンネルに参加してください!
これらのwandbotでの質問と回答は、実際にWeaveを使用してモニタリングされています!以下の図はモニタリング画面を示しています。まず、wandbotによって出力された質問と回答のリスト、および質問がどこで行われたか(SLACK_JAなど)の情報を見ることができます。実際の使用データをweaveに保存しています。Weaveでは人間のフィードバックを追加できるので、wandbが回答できる質問とできない質問のリストをそれぞれ取得できます。

Weaveでは、質問と回答を見るだけでなく、各行をクリックすることで内部プロセスを詳細にトレースすることができます(Weaveのトレース機能を使用)。実際、前の質問への回答は不正確でした。Weaveのトレースを使用して、これをより深く掘り下げることができます。
以下の図がその例です。wandbotはRAG(検索拡張生成)ベースのチャットボットなので、どのようなドキュメントが抽出されたかに興味があります。例えば、どのような種類のドキュメントが取得されたかを確認できます。実際に見てみると、抽出されたドキュメントには韓国語のコンテンツが含まれていることがわかります。ドキュメント検索がうまく機能していないようです。

現状のwandbotは、日本語のドキュメントが一部の領域で不十分な場合があるため、英語のドキュメントも検索するようにシステムが設定されています。そのため、異なる言語で類似のドキュメントが抽出されているのが分かります。より効率的で効果的なドキュメント検索が改善につながる可能性があります。
(実装が気になる方👦)上記のようなトラッキングはどのようにできるのでしょうか?
コードタブをクリックすると、関連する関数を確認でき、関数に@weave.op()デコレータが付いているのが分かります。Weaveを使用すると、関数に@weave.op()デコレータを追加するだけで、使用された関数とその入出力を簡単にトレースできます!詳しくはドキュメントを参照下さい。

次の章では、この分析から得られたヒントに基づいて、wandbotがどのようにアップグレードされているかを紹介します。
日本語wandbotの改善
前の章で、日本語wandbotのドキュメント検索に改善の余地があることがわかりました。多言語ドキュメントの管理には多くの労力が必要であり、かつ非効率なドキュメント検索につながる可能性があるため、日本語の質問を英語に翻訳し、英語でドキュメント検索と回答生成を行い、その結果を日本語に翻訳し直すプロセスを導入することを検討してみましょう。これがうまく機能すれば、パフォーマンスだけでなく、多言語ドキュメントのメンテナンスコストの面でもメリットが得られます。
wandbotのコードはこちらで公開されています。上記を実装するには、https://github.com/wandb/wandbot/blob/main/src/wandbot/chat/chat.py の修正が必要です。まず、下図の左側に示すように、_translate_ja_to_enと_translate_en_to_jpという関数を追加しました。また、図の右側に示すように、各関数に@weave.op()を追加して、Weaveを使用して翻訳がうまく機能しているかどうかをトレースできるようにしました。

実際に開発版を実行して、同じ質問「ウェブインターフェースでどのようにしてrunを停止できますか?」を尋ねてみました。正常に回答が提供されていることがわかります。

Weaveでこれがどのようにトレースされたかを見てみましょう。まず、前のトレースの最初と最後に、"Chat._translate_ja_to_en"と"Chat._translate_en_to_jp"という翻訳プロセスが追加されていることがわかります。これらの翻訳が正しく実行されたことも確認できます。画面に表示できるドキュメントの数が限られているため少し見づらいですが、英語のドキュメントのみが抽出され、これらから回答が生成されたことを確認できました。翻訳を組み込む方法がうまく機能しているようです。

定量的かつ包括的な評価
前の章では、翻訳プロセスを導入したwandbotの改良版を試してみましたが、1つのケースを見たにしかすぎません。最終的にデプロイメントに持っていくためには、包括的かつ体系的な評価が必要です。そこで、改良版をデプロイする前に、包括的な評価を行いました。wandbotの評価方法については、以下のレポートを参照してください。wandbotの評価とともに、約100問の評価データセットを常に更新し、このデータセットに基づいて評価を行っています。
日本語評価データセットの作成
上記の結果は英語の質問に対するwandbotのパフォーマンスを示していますが、wandbotの日本語パフォーマンスは体系的に評価されていませんでした。そこで、まず日本語の評価データセットを作成しました。英語のデータセットをLLMを使用して翻訳し、その後、手動でチェックして微調整を行いました。評価データセットはこちらで利用可能です。(Weaveはデータセットのバージョン管理も行えます。)

Weaveを使用した評価
次に上記のデータセットを使用して評価を行いました。評価は参照回答に基づいてLLM-judgeを使用して実施されます。Weaveは評価のためのEvaluationクラスを提供しており、Evaluationを使用すると評価データセットに対する評価と結果の集計が自動的に行われます。
実際の結果は以下の通りです。上から順に、システムは:
<日本語評価> 翻訳にgpt3.5を使用したRAG
<日本語評価> 翻訳にgpt4-oを使用したRAG
<日本語評価> 現在のwandbotを日本語で評価
<英語評価> 現在のwandbotを英語で評価
実際のプロジェクトはこちらで確認できます!

true_fractionは正確率を表しており、翻訳にgpt4-oを使用したRAGが現在の日本語wandbotと比較して改善された正確性を示していることがわかります。さらに、各行をクリックすることで、どの質問に正しく答えられ、どの質問に間違って答えたかを確認できます。包括的な評価により、新しいシステムがより高い正確性を達成していることが確認されました。

Weaveを使用したレポートの作成
Weaveを使ってもう少し深く掘り下げてみましょう。Weaveの評価機能では、比較したい結果を選択して「Compare」ボタンを押すと、自動的にレポートが生成されます。

以下は自動生成されたレポートです。レーダーチャート、棒グラフ、比較表が自動的に作成されます。

また、レポートの下部では、各サンプルに対する各システムの応答を表示できます。下の散布図は、任意の指標に対する各サンプルの位置を示しており、横軸と縦軸は2つのシステムの性能を示しています(0が不正解、1が正解)。マウスで興味のあるサンプルを選択することで、下の「Output Comparison」に表示されるサンプルをフィルタリングできます。以下の例では、旧RAGシステムも新RAGシステムも答えられなかったサンプルに絞り込んでいます。このようなフィルターを使用することで、wandbotが苦戦している質問の種類を理解し、さらなる改善のためのヒントを得ることができます。

最後に
このブログでは、Weaveを使用してwandbotを改善する実践的な例を紹介しました。生成AIを使用したアプリケーションの開発は、動作の理解、デバッグ、評価の面で課題がある場合があります。しかし、Weaveを使用することで、開発プロセスを加速することができます!Weaveを使って、より迅速に開発を進めていきましょう。
Weaveは、Weights & Biases が現在最も力を入れている製品の一つです。まだEarly Stageですが、開拓者になりたい方は是非試して、ブログを書き、どんどん広げていってください。
Weaveはこちらからスタートすることができます!